딥러닝으로 Navier-Stokes 방정식을 풀 수 있을까?

작성자 :
정현영
서울대학교 지역시스템공학과 정현영 | Deepest S18 Seminar
들어가며
유체역학의 근간을 이루는 지배방정식인 Navier-Stokes 방정식은 점성 유체의 운동을 기술하는 비선형 편미분방정식(Partial Differential Equation, PDE)입니다. 수돗물의 흐름부터 항공기 주변 기류까지, 이 방정식 하나가 대부분의 유체 현상을 지배한다고 알려져 있습니다.
이 방정식을 풀기 위해 CFD(Computational Fluid Dynamics, 전산유체역학)가 꾸준히 발전해 왔습니다. FEM(유한요소법), FVM(유한체적법), FDM(유한차분법) 등의 수치해석 방법론을 바탕으로 전산유체역학은 유체 시뮬레이션의 사실상 유일한 해법으로 여겨지기도 했습니다. 하지만 최근, 딥러닝이 과학 계산(Computational Science)분야에 본격적으로 진입하면서 새로운 패러다임이 열리고 있습니다. 이 글에서는 그 흐름을 따라 핵심 방법론을 정리해 보겠습니다.
1. 전통적 방법의 한계
기존 CFD 시뮬레이션은 시공간을 격자(grid)나 mesh로 이산화하여 PDE를 근사적으로 해석합니다.
위 식은 편미분방정식의 미분항을 이산화하는 유한차분법(Finite Difference Method, FDM)의 가장 기초적인 형태입니다. 이러한 방법을 통해 복잡한 편미분 방정식을 컴퓨터가 계산할 수 있는 이산적인 형태로 변환하여, 물리 현상을 수치적으로 시뮬레이션할 수 있게 합니다.
하지만 이러한 기존의 방식에는 세 가지 고질적인 문제가 존재합니다.
격자 의존성과 계산 비용. 격자를 세밀하게 만들수록 정확도는 올라가지만 계산량은 폭발적으로 증가합니다. 3D 난류 시뮬레이션에서는 격자 수가 수억 개를 넘기도 합니다.
시간 스텝 안정성 조건(CFL Condition). 수치적 안정성을 위해 Courant-Friedrichs-Lewy 조건을 만족해야 하는데, 이는 시간 스텝의 크기(\Delta t)를 격자 크기(\Delta x)에 비례하여 작게 유지해야 함을 의미합니다. 결과적으로 장기 시뮬레이션은 매우 비효율적일 수밖에 없습니다.
“One-Parameter-at-a-Time” 병목. 레이놀즈 수나 점성 계수 등 PDE의 파라미터가 바뀔 때마다 시뮬레이션을 처음부터 수행해야 합니다. 이는 수많은 파라미터 조합을 탐색해야 하는 Inverse problem이나 실시간 제어에는 치명적인 한계로 작용합니다.
Neural Network로 PDE를 풀 수 있을까?
가장 직관적인 접근은 CNN 같은 표준 신경망에 초기/경계 조건 등을 입력으로 제공하고, CFD 시뮬레이션 결과를 ground truth로 삼아 학습시키는 방식입니다. 실제로 이러한 시도가 많았고, 유동장 예측 속도는 크게 빨라졌습니다.
그러나 결정적인 문제가 두 가지 있습니다. 첫 번째는 블랙박스 문제(The Black Box Problem)입니다. 위 방법으로 설계된 모델은 물리 법칙을 전혀 고려하지 않기 때문에 질량 보존(연속 방정식) 등의 물리 법칙이 무시될 수 있고, 픽셀 수준의 통계적 패턴만 학습하는 경향이 있습니다. 두 번째 문제는 격자 의존성입니다. 고정된 euclidean grid 위에서 작동하는 CNN의 특성 상 훈련 시 사용한 격자 해상도에 모델이 종속되어(resolution-dependent) 다른 해상도로 일반화되지 않는 문제가 있습니다.
이 두 가지 근본적 한계를 극복하기 위해 두 계열의 연구가 등장했습니다. Physics-Informed 접근과 Neural Operator 접근입니다.
2. Physics-Informed Neural Network (PINN)
Raissi et al., 2019, “Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations”
핵심 아이디어
PINN의 핵심은 단순하면서도 우아합니다. 신경망 \hat{u}(t, x; \theta)가 PDE의 해를 근사하도록 하되, 손실 함수 자체에 PDE를 위반하는 정도(Physics Residual)를 포함시킵니다. 물리 법칙을 손실로 넣어 학습한다는 의미에서 “Physics-Informed”라고 부릅니다.
일반적인 비선형 PDE를 다음과 같이 쓸 때:
PINN은 Physics Residual을 다음과 같이 정의합니다:
그리고 손실 함수는 두 항의 합으로 구성됩니다:
MSE_u: 초기조건/경계조건/관측 데이터와의 오차
MSE_f: 임의로 sampling한 collocation Points에서 PDE 잔차의 크기
Automatic differentiation 덕분에 \hat{u}의 편미분을 정확하게 계산할 수 있어, 격자 이산화 없이 연속적인 시공간에서 PDE를 강제할 수 있습니다.
두 가지 활용 모드
① Data-driven Solution: \lambda(레이놀즈 수 등)가 알려져 있을 때, 내부 관측 데이터 없이 PDE 조건(초기 및 경계 조건)만으로 해 u(x,t)를 구합니다.
② Data-driven Discovery: 관측 데이터 u(x,t)가 있을 때, \lambda를 trainable parameter로 두고 PDE 계수를 역으로 추정합니다.
실험 결과
Schrödinger 방정식 (Data-driven Solution)
5-layer 신경망(100 neurons/layer)에 collocation points N_f = 20000개를 사용하여 1D 비선형 Schrödinger 방정식을 풀었을 때, 초기/경계 조건 데이터만으로(총 N_0 = 50개, N_b = 50개) 상대 L_2 오차 1.97 \times 10^{-3}을 달성했습니다. 특히 이는 훈련 데이터의 총량이 전체 데이터의 1% 미만임에도 불구하고 달성한 결과로, PINN이 물리 제약만으로 데이터 효율을 크게 높일 수 있음을 보여줍니다.
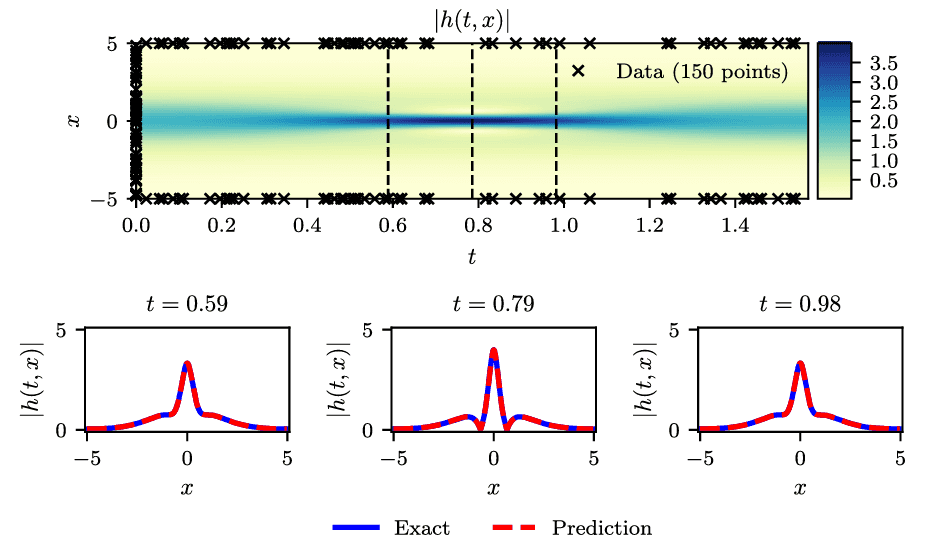
2D Navier-Stokes 방정식 (Data-driven Discovery)
레이놀즈 수 Re = 100인 원기둥 주위 유동(Kármán vortex street) 문제에서 PINN은 전체 데이터의 1%에 해당하는 N = 5000개의 속도장 데이터(noise 없음)만으로 미지의 PDE 계수 \lambda_1, \lambda_2를 다음과 같이 복원했습니다:
조건 | \lambda_1 오차 | \lambda_2 오차 |
Clean Data | 0.078% | 4.67% |
1% Gaussian Noise | 0.17% | 5.70% |
이와 함께, 훈련 데이터에 압력 정보가 전혀 없음에도 압력장 p(t, x, y) 전체를 정성적으로 정확하게 복원했습니다. 이는 PINN이 Navier-Stokes의 발산 자유 조건(\nabla \cdot \mathbf{u} = 0) 등 물리 구조를 이용해 관측되지 않은 물리량까지 추론할 수 있음을 보여주는 인상적인 결과입니다.
Burgers 방정식
9-layer, 20 neurons/layer 신경망 고정 상태에서, 경계/초기 훈련 데이터 수 N_u와 collocation point 수 N_f에 따른 상대 L_2 오차를 측정한 결과:
N_u \backslash N_f | 2,000 | 6,000 | 10,000 |
|---|---|---|---|
20 | 2.9e-01 | 8.9e-01 | 4.2e-02 |
80 | 5.5e-03 | 3.2e-03 | 4.5e-03 |
200 | 1.5e-01 | 8.2e-04 | 4.9e-04 |
이 결과는 collocation points N_f가 충분히 많을수록 오차가 줄어드는 경향을 보이며, PINN이 데이터(N_u)와 물리 제약(N_f) 모두를 적절히 확보해야 최적 성능을 낸다는 점을 보여줍니다.
PINN의 한계
PINN은 물리 법칙을 학습에 통합했다는 점에서 획기적이지만, 다음과 같은 한계도 함께 지닙니다.
Single-Instance Learning: 파라미터 \lambda가 바뀌면 처음부터 재학습이 필요합니다. CFD의 “one-parameter-at-a-time” 문제가 그대로 남아 있습니다.
Spectral Bias: 표준 MLP는 저주파 성분을 먼저, 고주파 성분을 나중에 학습하는 경향이 있어 난류처럼 다양한 스케일의 구조를 포착하기 어렵습니다. 유체 역학에서 이는 PINN이 전반적인 유동 방향은 포착하지만, 세밀한 난류나 급격한 충격파(shock waves)를 분해(resolve)하지 못함을 의미합니다.
Optimization Complexity: PINN의 손실 지형(loss landscape)은 종종 매우 거칠고(stiff) 비볼록(non-convex)하여, Adam과 같은 표준 최적화 알고리즘이 세심한hyperparameter 튜닝 없이는 global minimum을 찾기 어렵습니다. 즉, 데이터 손실과 PDE 손실의 상충(multi-objective optimization)으로 학습이 불안정하거나 수렴이 느려질 수 있습니다.
3. Neural Operators: FNO & LNO
Parametric PDE와 Operator Learning
PINN의 한계를 돌파하려면 관점의 전환이 필요합니다. 고정된 하나의 PDE를 푸는 대신, PDE들의 집합(a family of PDEs)를 한꺼번에 다루는 것입니다. 이러한 관점을 Parametric PDE Solving이라고 부릅니다.
왜 “parametric”이냐면, 우리가 푸는 PDE가 하나로 고정되어 있지 않고 초기/경계조건, 외력, 물성(점성, 레이놀즈 수 등) 같은 입력이 파라미터처럼 변하면서 서로 다른 해가 계속 생성되기 때문입니다. 즉 “한 번의 학습으로 하나의 해(u)만 맞추는 것”이 아니라, 입력 함수/파라미터 a가 바뀔 때마다 해 u가 어떻게 바뀌는지라는 매핑(해 연산자, solution operator) 자체를 학습하려는 문제 설정입니다. 이렇게 하면 기존의 CFD와 PINN의 한계인 “one-parameter-at-a-time” 병목을, 학습된 모델의 빠른 추론으로 완화할 수 있습니다.
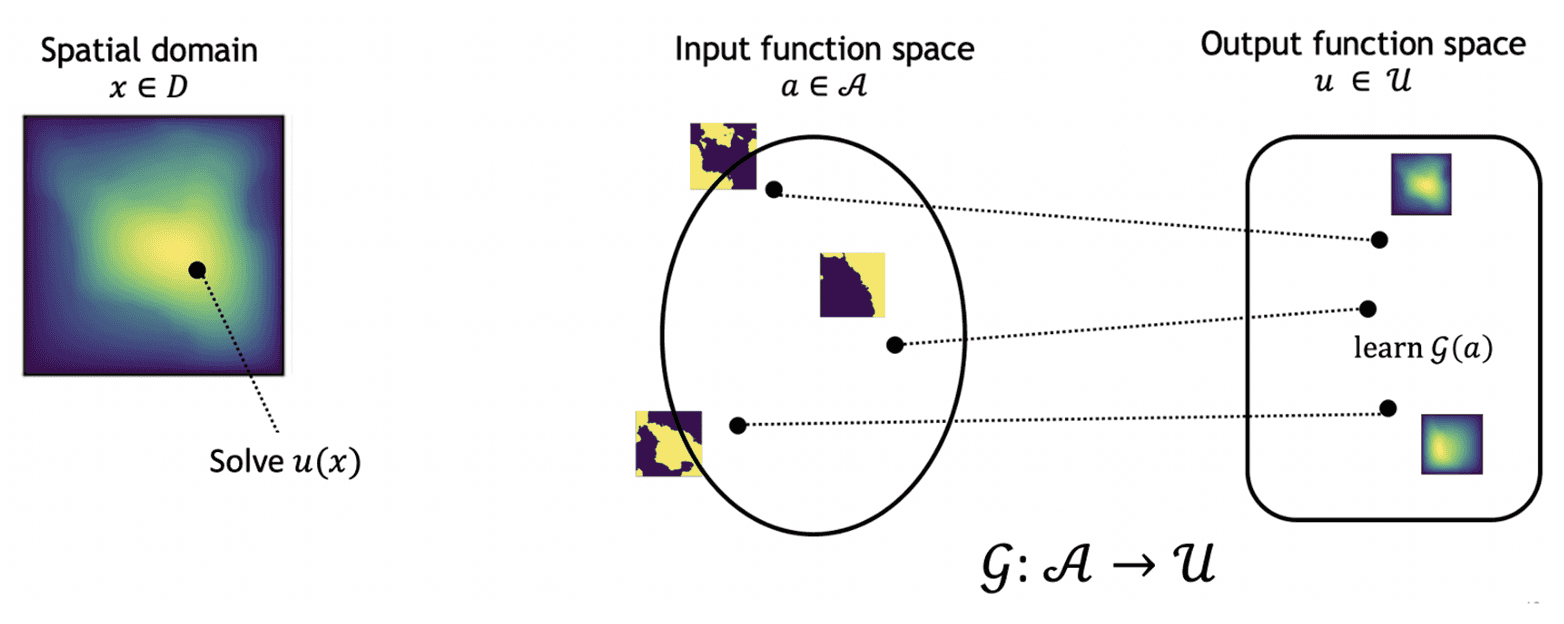
Parametric PDE는 입력 함수 a(x) \in \mathcal{A}가 주어졌을 때 해 u \in \mathcal{U}를 구하는 문제로 정리할 수 있습니다:
여기서 a(x)는 초기조건, 경계조건, 또는 물리 파라미터 자체일 수 있습니다.
목표는 Solution Operator G^\dagger: \mathcal{A} \to \mathcal{U}를 학습하는 것입니다. 즉, 입력 함수 공간에서 출력 함수 공간으로의 매핑을 신경망 G_\theta로 근사합니다:
한 번 학습된 Neural Operator는 새로운 입력 함수에 대해 단 한 번의 순전파(forward pass)만으로 해를 출력합니다. PINN처럼 재학습할 필요가 없습니다.
Neural Operator Architecture
Li et al., 2020, “Neural Operator: Graph Kernel Network for Partial Differential Equations”
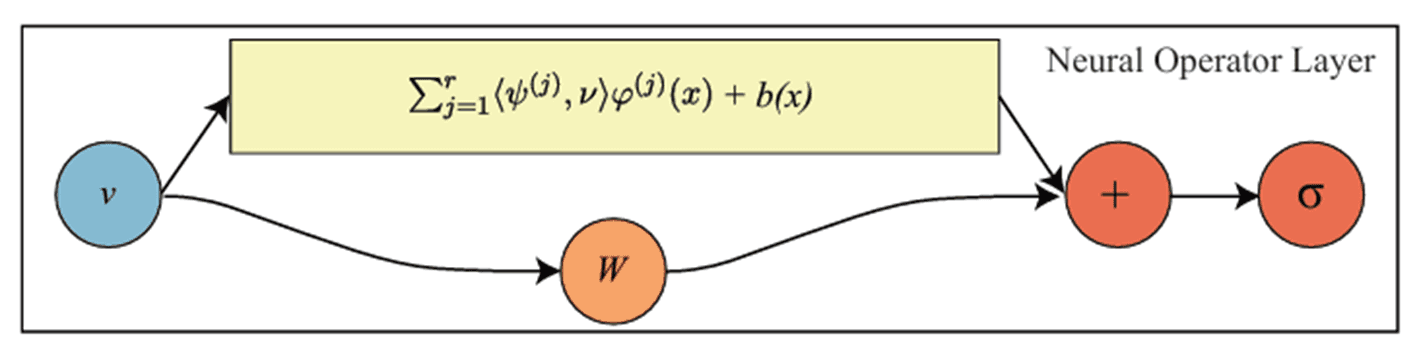
Neural Operator의 기본 구조는 세 단계로 요약됩니다.
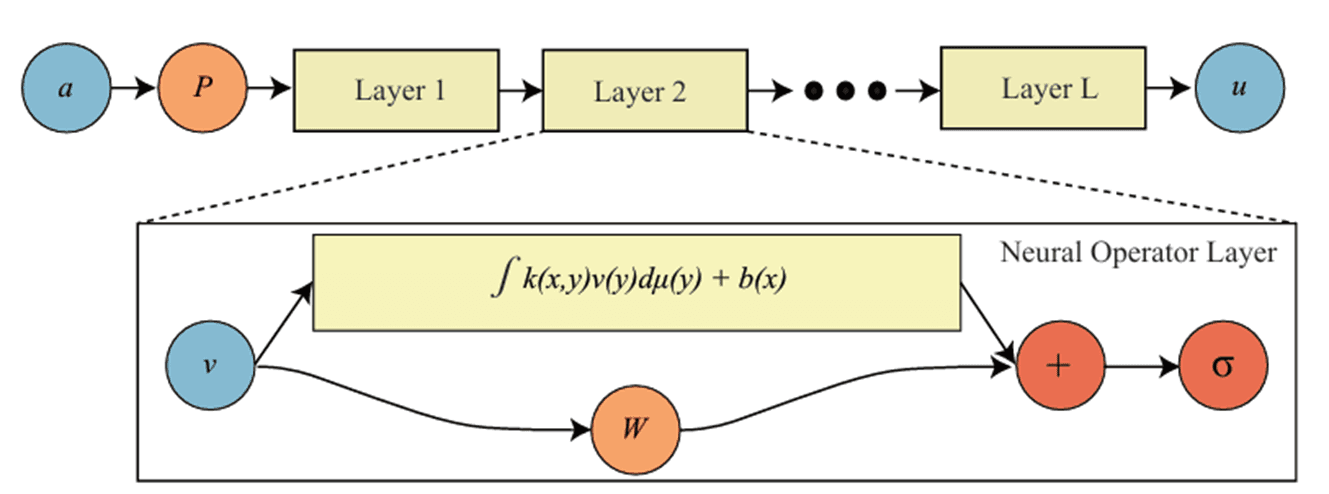
Lifting: 입력 함수 a(x)를 고차원 feature space로 변환합니다 — v_0(x) = P(a(x))
Iterative Updates: 여러 레이어를 거치며 표현을 정제합니다. 각 레이어에서 전역(Global) 경로와 지역(Local) 경로가 합산됩니다:
Projection: feature space에서 최종 해로 변환합니다 — u(x) = Q(v_T(x))
이러한 architecture은 이산화에 무관합니다(discretization invariant). 유한 차원 벡터 공간을 다루는 기존 신경망, 예를 들어 CNN이 특정 격자 해상도에 종속되는 것과 달리, Neural Operator는 함수 그 자체를 다루는 무한 차원 함수 공간에서 작동하는 architecture임으로 임의의 해상도 입력을 처리할 수 있습니다.
Fourier Neural Operator (FNO)
Li et al., 2021, “Fourier Neural Operator for Parametric Partial Differential Equations”
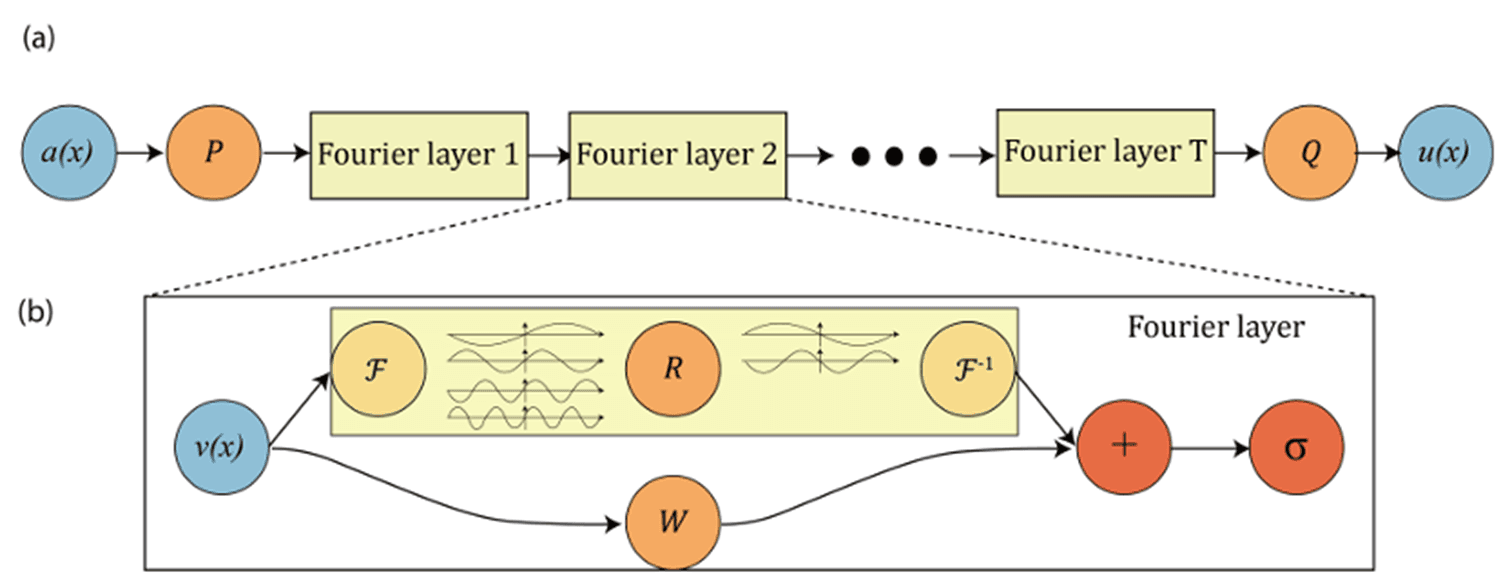
Kernel Integral 계산의 핵심 병목을 해결한 것이 FNO입니다. FNO의 작동 원리의 핵심은 Convolution Theorem입니다.
커널 적분을 convolution으로 변환하면 Fourier 공간에서의 단순 곱셈 연산으로 대체할 수 있습니다. FNO는 kernel을 Fourier 공간에서 직접 파라미터화합니다:
여기서 R_\phi는 학습 가능한 복소수 텐서입니다. FFT 덕분에 계산 복잡도가 O(N^2)에서 O(N \log N)으로 줄어듭니다.
실험 결과
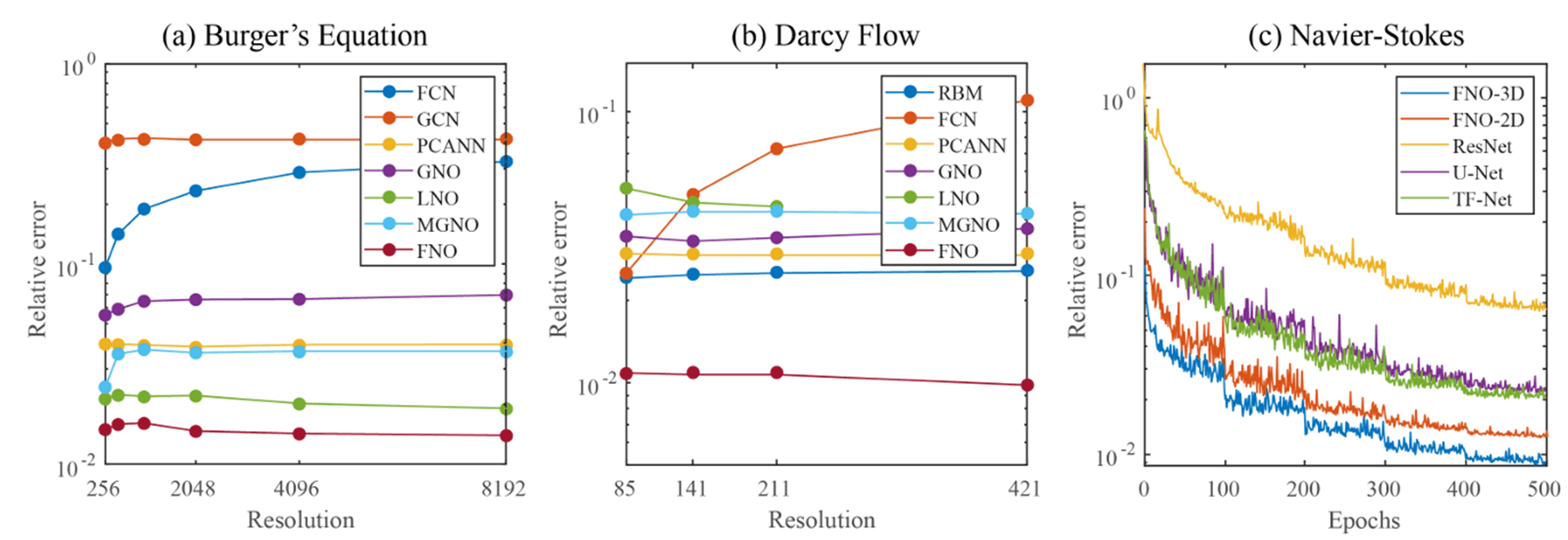
1D Burgers 방정식
FNO는 다양한 해상도에서 기존 방법들 대비 낮은 오차를 유지합니다. 특히 FCN(Fully Convolutional Network) 같은 CNN 기반 방법은 해상도가 높아질수록 오차가 급증하는 반면, FNO는 해상도에 무관하게 일관된 오차율을 보입니다:
방법 | s=256 | s=1024 | s=4096 | s=8192 |
|---|---|---|---|---|
FCN | 0.0958 | 0.1877 | 0.2855 | 0.3238 |
GNO | 0.0555 | 0.0651 | 0.0666 | 0.0699 |
MGNO | 0.0243 | 0.0374 | 0.0364 | 0.0364 |
FNO | 0.0149 | 0.0160 | 0.0142 | 0.0139 |
2D Darcy Flow
FNO는 Darcy Flow에서도 기존 방법 대비 낮은 오차를 보여줍니다:
방법 | s=85 | s=141 | s=211 | s=421 |
|---|---|---|---|---|
RBM | 0.0244 | 0.0251 | 0.0255 | 0.0259 |
GNO | 0.0346 | 0.0332 | 0.0342 | 0.0369 |
MGNO | 0.0416 | 0.0428 | 0.0428 | 0.0420 |
FNO | 0.0108 | 0.0109 | 0.0109 | 0.0098 |
2D Navier-Stokes 방정식
Navier-Stokes 방정식에서 64×64 고정 해상도 기준으로 FNO-3D는 모든 점성 조건에서 최고 성능을 보였습니다:
방법 | 파라미터 수 | ν=1e-3 (T=50) | ν=1e-4 (T=30) | ν=1e-5 (T=20) |
|---|---|---|---|---|
ResNet | 266K | 0.0701 | 0.2871 | 0.2753 |
U-Net | 24.9M | 0.0245 | 0.2051 | 0.1982 |
TF-Net | 7.4M | 0.0225 | 0.2253 | 0.2268 |
FNO-2D | 414K | 0.0128 | 0.1559 | 0.1556 |
FNO-3D | 6.5M | 0.0086 | 0.1918 | 0.1893 |
추론 속도 측면에서 FNO는 GPU 기반 pseudo-spectral solver 대비 약 400배 빠른 추론을 제공합니다. 256 \times 256 격자 기준으로 FNO는 0.005초에 하나의 인스턴스를 예측하는 반면, 전통적 solver는 2.2초가 소요됩니다.
Zero-shot Super-resolution
64 \times 64 \times 20 해상도 데이터로 학습한 FNO-3D를 256 \times 256 \times 80 해상도에서 평가했을 때도, 고주파 성분을 포함한 에너지 스펙트럼이 ground truth와 거의 일치하는 결과를 보였습니다. 이는 FNO가 훈련 시 보지 않은 더 높은 해상도로도 정확하게 일반화됨을 의미합니다.
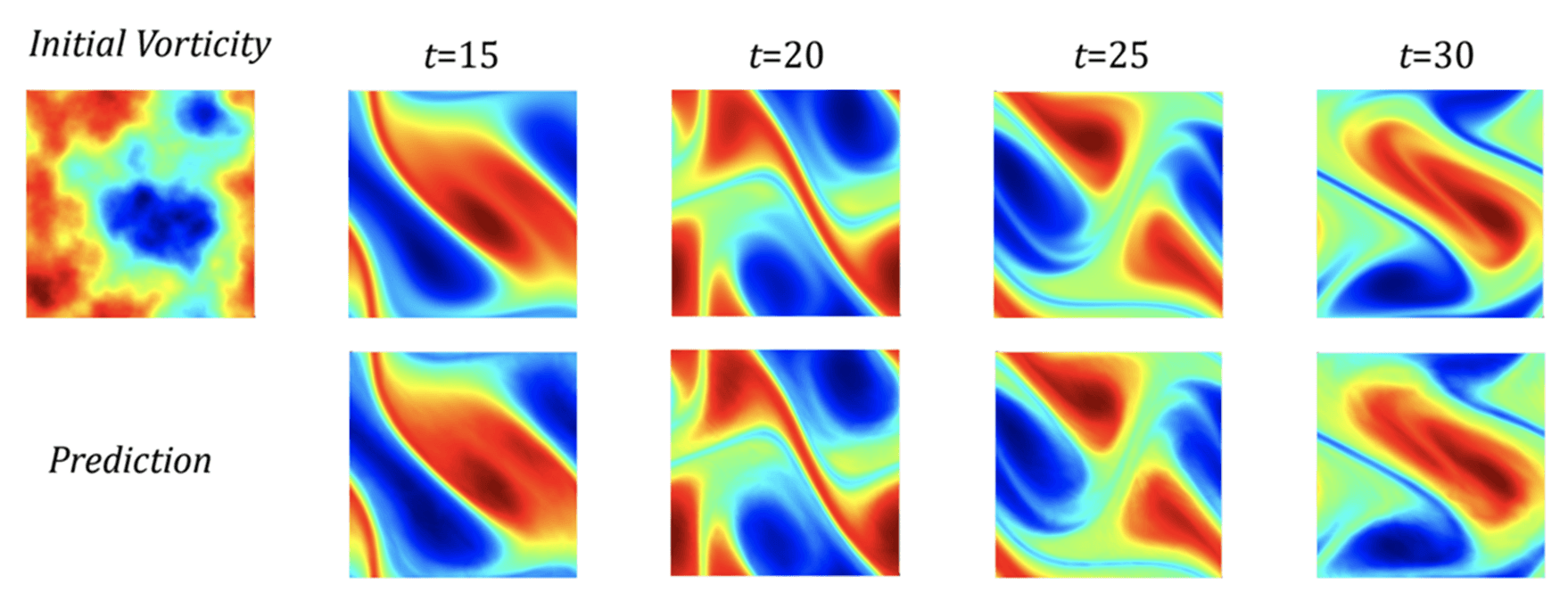
다만 FNO의 한계도 존재합니다:
FFT는 uniform Cartesian grid와 주기적 경계 조건을 가정하므로 복잡한 기하학적 도메인에 곧바로 적용하기 어렵습니다.
손실 함수가 point-wise error로만 구성되어 지배 방정식 자체의 물리 법칙을 학습 과정에 강제하지 않습니다.
자기회귀(auto-regressive) 방식으로 장기 예측 시 오차가 누적(error blow-up)될 수 있습니다.
Laplace Neural Operator (LNO)
Cao et al., 2023, “LNO: Laplace Neural Operator for Solving Differential Equations”
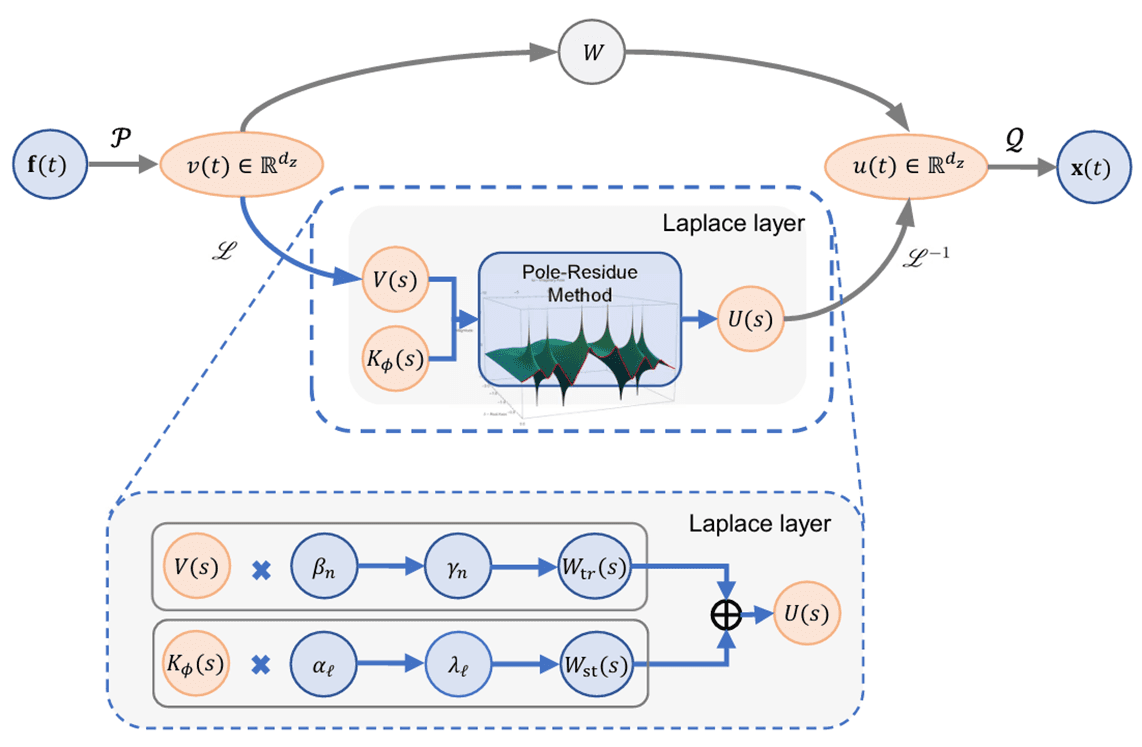
LNO는 Fourier Transform 대신 Laplace Transform을 기반으로 합니다. FNO가 주파수 영역을 다루는 반면, LNO는 s-domain(복소 주파수 영역)에서 Pole-Residue Method를 통해 kernel을 표현합니다:
이 접근은 인과성(causality)을 자연스럽게 보존하고, 비주기적 시스템이나 불안정한 동역학에도 잘 대응한다는 이론적 장점이 있습니다. 따라서 Navier-Stokes과 같은 유동 문제보다는 구조 해석이나 진동 제어 분야에서 좋은 성능을 발휘합니다. 보의 휨, 프레임의 진동, 댐핑 시스템 등 고체 및 구조 역학의 지배 방정식은 라플라스 도메인에서의 Pole-Residue 관계로 설명되는 경우가 많아 LNO의 아키텍처와 매우 잘 맞는 점도 이러한 장점을 강화시킵니다.
4. Physics-Informed Neural Operator (PINO)
Li et al., 2023, “Physics-Informed Neural Operator for Learning Partial Differential Equations”
PINN의 물리 제약과 Neural Operator의 함수 공간 일반화를 결합한 것이 PINO입니다.
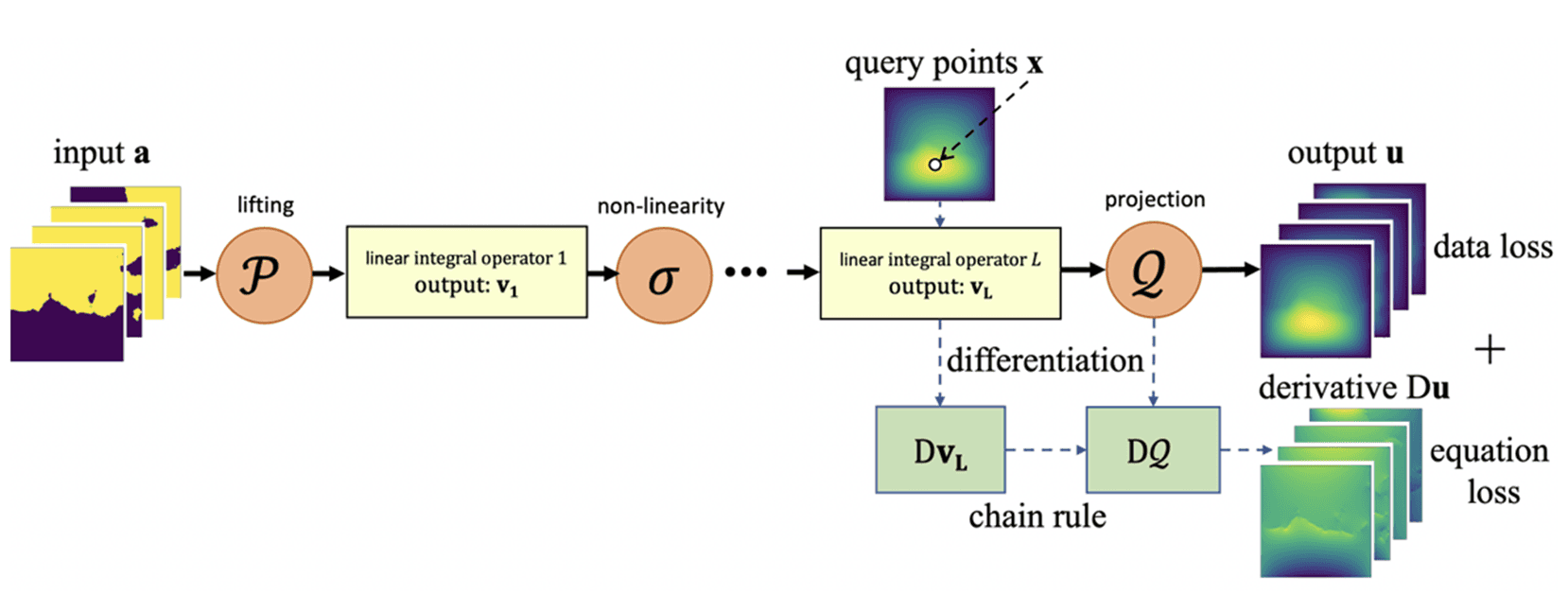
손실 함수
\mathcal{L}_{\text{pde}}는 FNO처럼 operator learning 과정에서, 그리고 새로운 인스턴스에 대한 instance-wise fine-tuning 과정에서 모두 활용됩니다.
실험 결과
PINO의 실험 결과는 크게 두 가지 강점을 보여줍니다.
1. PDE loss를 통한 다해상도 일반화 (Multi-Resolution Generalization)
저해상도 데이터로 학습하되, 고해상도 PDE loss를 병용하면 학습 데이터보다 훨씬 높은 해상도에서도 오차 열화 없이 일반화됩니다:
PDE | 학습 방식 | 학습 해상도 오차 | 2× 해상도 오차 | 4× 해상도 오차 |
|---|---|---|---|---|
Burgers | Data only | 0.32±0.01% | 3.32±0.02% | 3.76±0.02% |
Burgers | Data + PDE loss | 0.17±0.01% | 0.28±0.01% | 0.38±0.01% |
Darcy | Data only | 5.41±0.12% | 9.01±0.07% | 9.46±0.07% |
Darcy | Data + PDE loss | 5.23±0.12% | 1.56±0.05% | 1.58±0.06% |
Kolmogorov flow | Data only | 8.28±0.15% | 8.27±0.15% | 8.30±0.15% |
Kolmogorov flow | Data + PDE loss | 6.04±0.12% | 6.02±0.12% | 6.01±0.12% |
이 결과는 PDE loss가 단순한 정규화 이상의 역할을 한다는 것을 보여줍니다. Data only 학습 시 해상도가 두 배만 높아져도 오차가 10배 이상 증가하는 반면, PDE loss를 병용하면 4× 해상도에서도 오차 수준이 거의 유지됩니다.
2. PINN 대비 정확도·속도 우위
Re=500, T=0.5s Chaotic Kolmogorov flow에서 PINO는 PINN 대비 20배 낮은 오차(0.9% vs. 18.7%)와 약 7.5배 빠른 속도(608s vs. 4,577s)를 동시에 달성했습니다. 장기 transient flow(T=[0,50])에서도 GPU 기반 pseudo-spectral solver 대비 400배 빠른 속도로 상대 L_2 오차 2.87%(fine-tuning 후 1.84%)를 기록합니다.
5. PINNsFormer: Transformer 기반 PINN
Zhao et al., 2024, “PINNsFormer: A Transformer-Based Framework For Physics-Informed Neural Networks”
PINN의 또 다른 약점인 Spectral Bias와 Optimization Complexity를 Transformer 아키텍처로 극복하려는 시도가 PINNsFormer입니다.
아키텍처
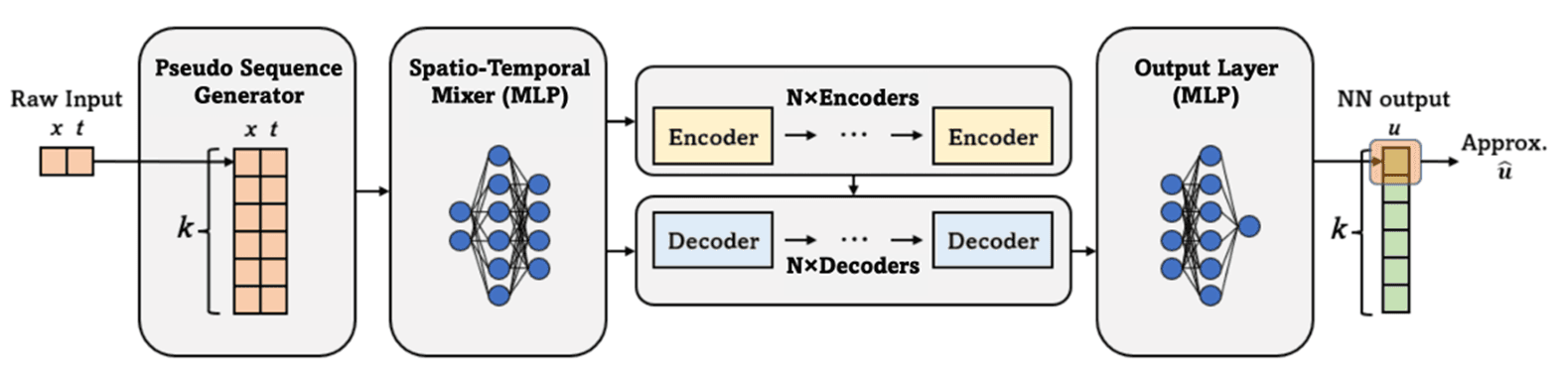
PINNsFormer는 네 모듈로 구성됩니다.
① Pseudo Sequence Generator
: PINN은 점별(point-wise) 시공간 좌표 (x, t)를 입력으로 받습니다. Transformer에 적용하려면 시퀀스로 변환해야 합니다. 각 입력 포인트를 시간축으로 k개 복제하여 pseudo sequence를 생성합니다:
② Spatio-Temporal Mixer (MLP): 저차원 PDE 입력(x, t 등)을 Transformer가 처리하기 적합한 고차원 벡터로 선형 투영합니다.
③ Encoder-Decoder Transformer
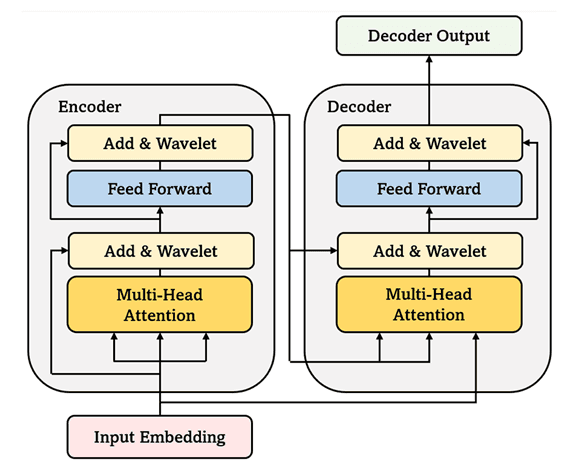
: Multi-Head Attention으로 시퀀스 내 전역적 상호작용을 포착합니다. 여기서 기존 LayerNorm 대신 Wavelet Activation을 사용하는 것이 핵심입니다:
이 활성화 함수는 목표 함수의 주파수 성분을 학습 가능하게 만들어 Spectral Bias를 완화하고, ReLU 대비 물리 제약의 gradient flow를 개선합니다.
④ Output MLP: Transformer 출력을 최종 PDE 해로 투영합니다.
손실 함수
시퀀스의 각 pseudo time step에서 PDE residual, 초기조건, 경계조건 오차를 모두 계산합니다.
성능
2D Navier-Stokes 방정식 실험에서 PINNsFormer는 기존 PINN 기반 방법들을 전 지표에서 크게 앞서는 성능을 보였습니다:
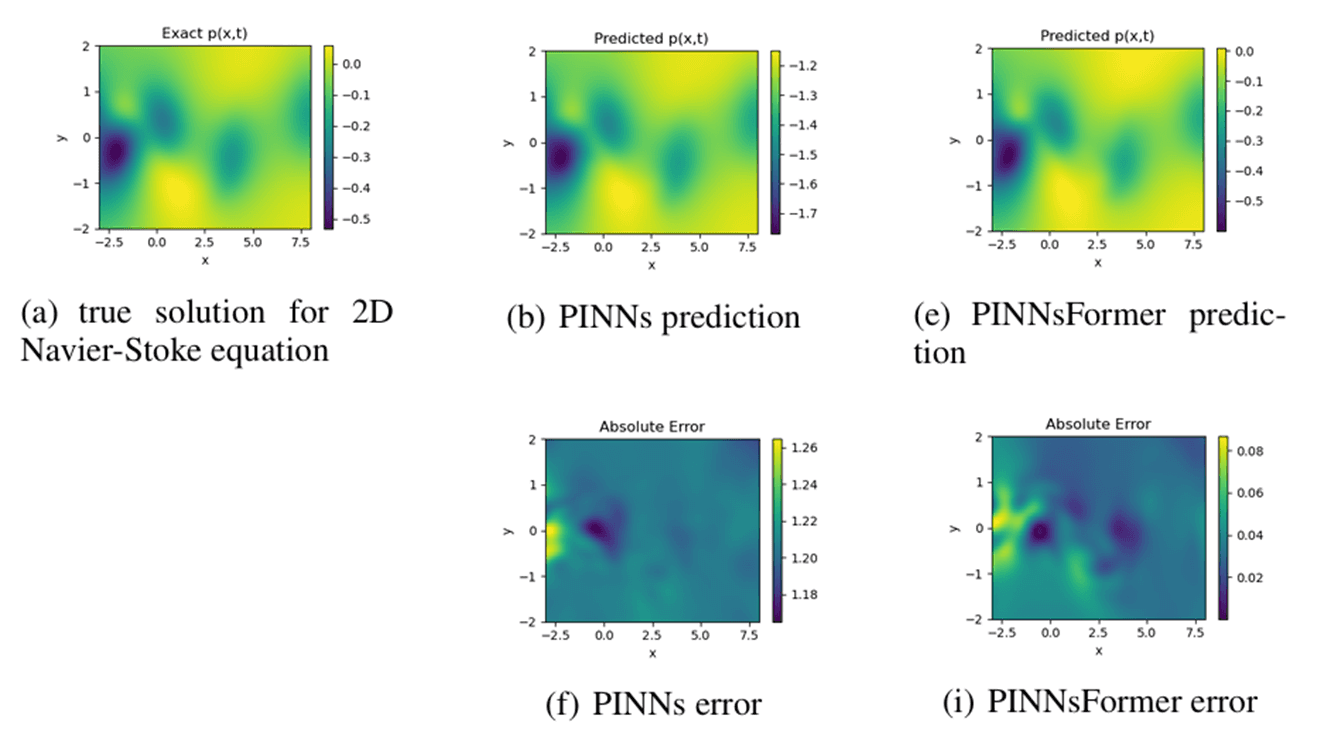
Navier-Stokes에서 PINNsFormer의 rMAE는 기존 PINN 대비 약 34배 낮습니다. 특히 기존 MLP 기반 방법들이 시간이 지남에 따라 압력 크기(magnitude)를 잘못 예측하는 반면, PINNsFormer는 시간에 걸쳐 형태와 크기 모두를 일관되게 맞추는 데 성공합니다.
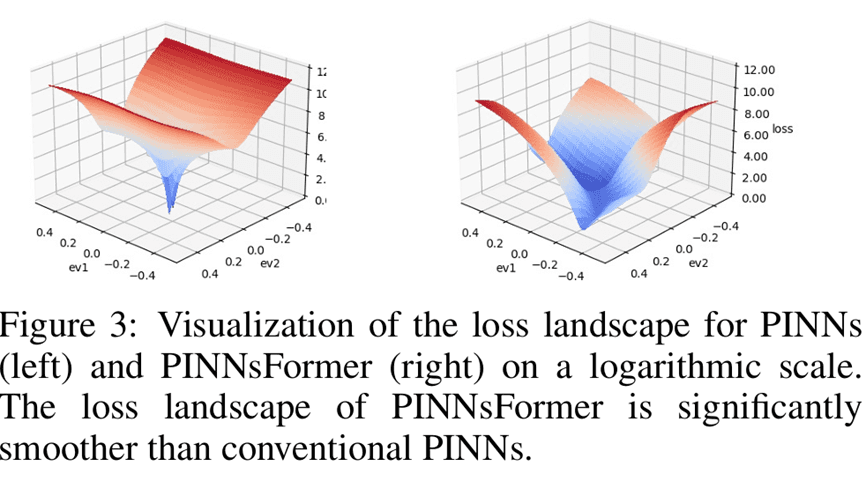
Loss landscape 시각화에서도 PINNsFormer의 landscape가 기존 PINN보다 현저히 매끄럽게 나타납니다. Lipschitz 상수 추정 결과, 기존 PINN은 L_{\text{PINNs}} = 776.16인 반면 PINNsFormer는 L_{\text{PINNsFormer}} = 32.79로 약 24배 더 매끄러운 landscape를 가집니다. 이는 학습 안정성의 개선을 정량적으로 뒷받침합니다.
마치며: 방법론의 계보와 전망
지금까지 살펴본 방법들의 계보를 정리하면 다음과 같습니다.
각 접근의 trade-off는 비교적 명확합니다. PINN 계열은 물리적 해석 가능성이 높고 데이터가 적어도 되지만 일반화에 약합니다. Neural Operator 계열은 빠른 추론과 강한 일반화를 제공하지만 물리 제약이 약하고 대량의 학습 데이터를 필요로 합니다. PINO와 PINNsFormer는 이 둘을 통합/발전하려는 시도라고 이해하실 수 있습니다.
아직 해결해야 할 과제들도 남아 있습니다. 복잡한 기하학(complex geometry)에서의 성능, 장기 예측의 안정성, 고차원 난류에서의 확장성 등이 대표적입니다. 다만 이 분야의 발전 속도를 고려하면, 딥러닝 기반 PDE solver가 전통 CFD를 보완하거나 일부 대체하는 시대가 멀지 않았다는 기대를 가져볼 수 있겠습니다.
참고문헌
Raissi, M., Perdikaris, P., & Karniadakis, G. E. (2019). Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378, 686–707. https://doi.org/10.1016/j.jcp.2018.10.045
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A., & Anandkumar, A. (2020). Neural operator: Graph kernel network for partial differential equations (arXiv:2003.03485). arXiv. https://arxiv.org/abs/2003.03485
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A., & Anandkumar, A. (2021). Fourier neural operator for parametric partial differential equations. In Proceedings of the International Conference on Learning Representations (ICLR 2021). https://arxiv.org/abs/2010.08895
Cao, Q., Goswami, S., & Karniadakis, G. E. (2023). LNO: Laplace neural operator for solving differential equations (arXiv:2303.10528). arXiv. https://arxiv.org/abs/2303.10528
Li, Z., Zheng, H., Kovachki, N., Jin, D., Chen, H., Liu, B., Azizzadenesheli, K., & Anandkumar, A. (2023). Physics-informed neural operator for learning partial differential equations. ACM/JMS Journal of Data Science, 1(3), 1–27. https://doi.org/10.1145/3648506
Zhao, Z., Ding, X., & Prakash, B. A. (2024). PINNsFormer: A transformer-based framework for physics-informed neural networks. In Proceedings of the International Conference on Learning Representations (ICLR 2024). https://arxiv.org/abs/2307.11833