분산 학습의 GPU 통신 기술 알아보기

작성자 :
유용환
최근 몇년간 LLM 모델 사이즈가 크게 증가하면서, 단일 GPU로 모델을 학습시키는 것은 거의 불가능해졌습니다. Llama 3 70B는 FP16 기준으로 약 140GB, GPT-4급 모델은 수 TB 수준의 GPU 메모리를 요구한다고 알려져있습니다. 단일 H100 GPU의 메모리가 80GB인 점을 고려하면 [1], 수백에서 수천 개의 GPU를 활용한 분산 학습이 필수적인 시대가 되었습니다.
보통 PyTorch 기반으로 분산 학습 코드를 작성하다 보면 torchrun을 자주 사용하게 됩니다. 내부를 들여다보면 torch.distributed를 사용하고, GPU 환경에서는 backend로 nccl이 설정됩니다 [2]. 여기서 NCCL은 뭐고, 이게 분산 학습에서 어떤 역할을 하는 걸까요?
Backend | CPU | GPU |
|---|---|---|
gloo | O | △ |
mpi | O | ? |
nccl | X | O |
xccl | O | O |
Table 3: torch.distributed Backend [2]
분산 학습에 관한 자료들을 살펴보면 대부분 '알고리즘' 관점에서 DP, TP, PP 등 여러가지 병렬화 기법들을 설명합니다. 하지만 실제로 대규모 클러스터에서 이러한 방법론을 적용해 학습을 진행하다보면, GPU를 더 추가해도 성능이 선형적으로 증가하지 않는 현상을 경험하게 됩니다. 바로 GPU 간 통신으로 인해 병목이 발생한 것인데요. 이 글에서는 이러한 GPU 간 통신(communication)에 초점을 맞춰, NCCL을 비롯한 통신 기술이 어떻게 발전해왔는지 정리해보고자 합니다.
1. 분산 학습 병렬화
통신 기술을 살펴보기 전에, 최근 분산 학습에 사용되는 세 가지 주요 병렬화 기법 (Data Parallelism, Tensor Parallelism, Pipeline Parallelism)에 대해 간략하게 이해해 보겠습니다. 세 방식 모두 빈도나 패턴은 다르지만, GPU 간 데이터 이동과 동기화가 발생한다는 공통점이 있으며, 이 통신 과정은 분산 학습의 성능을 좌우하는 핵심 요소입니다.
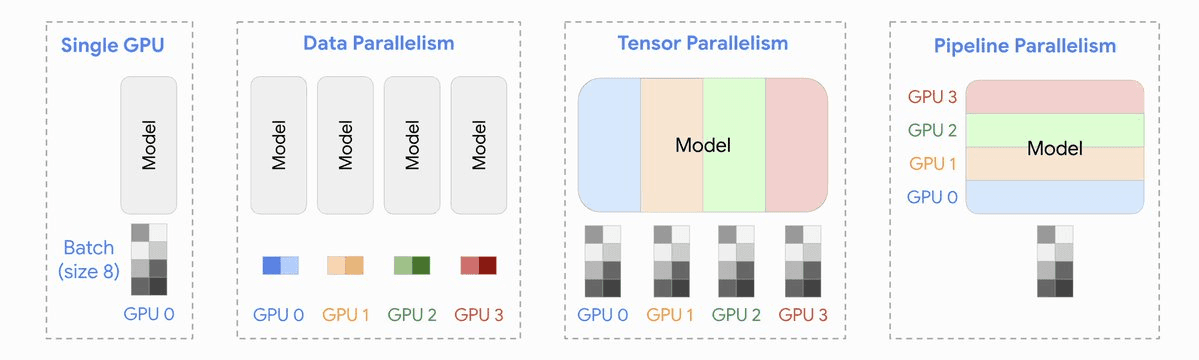
Figure 1: Single GPU, Data Parallelism, Tensor Parallelism, Pipeline Parallelism 비교
1.1 Data Parallelism (데이터 병렬화)
Data Parallelism에서는 동일한 모델의 사본을 여러 GPU에 복제하고, 데이터 배치를 나눠서 병렬로 학습합니다. 각 GPU가 서로 다른 데이터로 학습하기 때문에, 한 step이 끝나면 각각이 계산한 gradient 값을 다시 일관되게 맞추는 동기화 과정이 필요합니다.
1.2 Tensor Parallelism (텐서 병렬화)
레이어의 내부 연산을 여러 GPU에서 병렬 처리하는 방식입니다. 하나의 행렬 연산을 쪼개서 여러 GPU가 나눠 작업하기 때문에, 연산 중에 GPU 간 데이터 교환이 반복적으로 발생합니다.
1.3 Pipeline Parallelism (파이프라인 병렬화)
모델을 여러 stage로 쪼개서 순차적으로 실행하는 방식입니다. 앞 stage의 출력이 다음 stage의 입력이 되므로, 이 경우에도 GPU 간 데이터 전달이 필요합니다.
1.4 3D Parallelism
실제 대규모 모델 학습에서는 앞서 설명한 세 가지 병렬화 기법이 종종 동시에 사용됩니다.
DeepSpeed의 3D 병렬화를 예로 들면 [3], 각 기법이 서로 다른 역할을 맡도록 설계되어 있습니다:
Tensor Parallelism(TP)과 Pipeline Parallelism(PP): 단일 GPU가 감당해야 하는 메모리 사용량을 줄이기 위해 사용
Data Parallelism(DP): 연산 효율을 유지한 채 워커 수를 늘리기 위해 사용
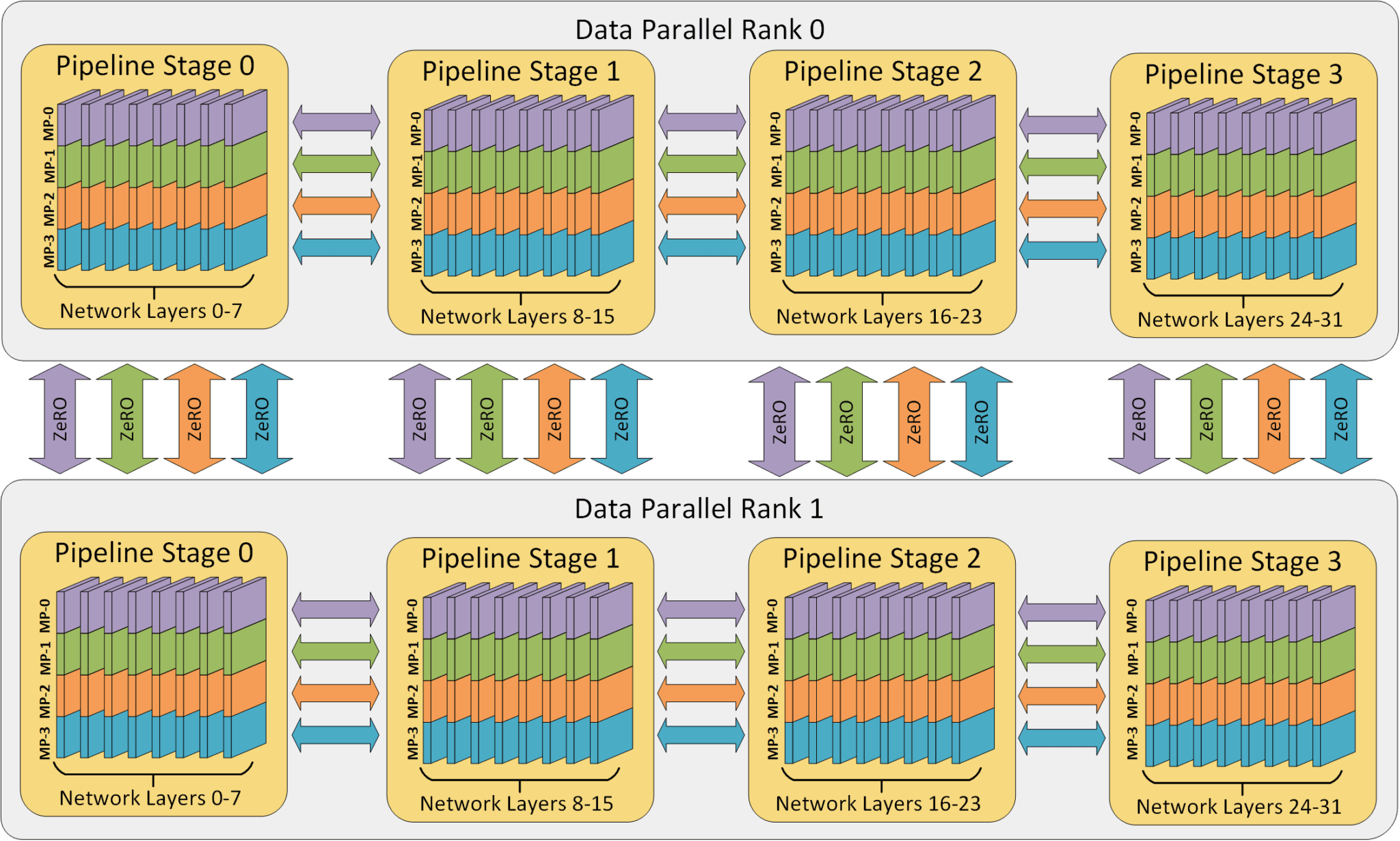
Figure 2: 32개 worker에서 Pipeline/Tensor/Data Parallel이 결합된 3D Parallelism 구조 [3]
이렇게 3D 병렬화를 사용하여 여러 GPU의 메모리와 컴퓨팅을 모두 감당할 수 있는 데까지 확장할 수 있습니다. 하지만 GPU 수가 많아질수록 그들 간의 통신이 확장성의 핵심 병목으로 남습니다. 뒤에서 더 자세히 다루겠지만, 최근 MoE 아키텍처가 유행하면서 등장한 Expert Parallelism 등으로 인해 GPU 간 통신 복잡도가 늘어나기도 했죠. Foundation model을 개발하는 스타트업들이 클라우드 GPU로 클러스터를 구성할 때, GPU 스펙 다음으로 고민하는 포인트가 데이터로더 성능(즉, I/O)과 GPU 간 통신 성능인 이유입니다.
이 병목은 단순히 병렬화 설계의 문제가 아니라 하드웨어 진화의 방향과도 깊은 연관이 있는데요, 이제 본격적으로 GPU 통신 기술이 어떻게 발전해왔는지 살펴보겠습니다.
2. GPU 통신 기술의 발전
2.1 통신 병목 현상 (Communication Bottleneck)
McCalpin의 분석에 따르면 [4], 지난 수십 년간 컴퓨팅 성능은 빠르게 발전해온 반면, 메모리 지연 시간은 거의 줄어들지 않았고, 메모리 bandwidth도 연산 성능 증가를 따라가지 못했습니다.
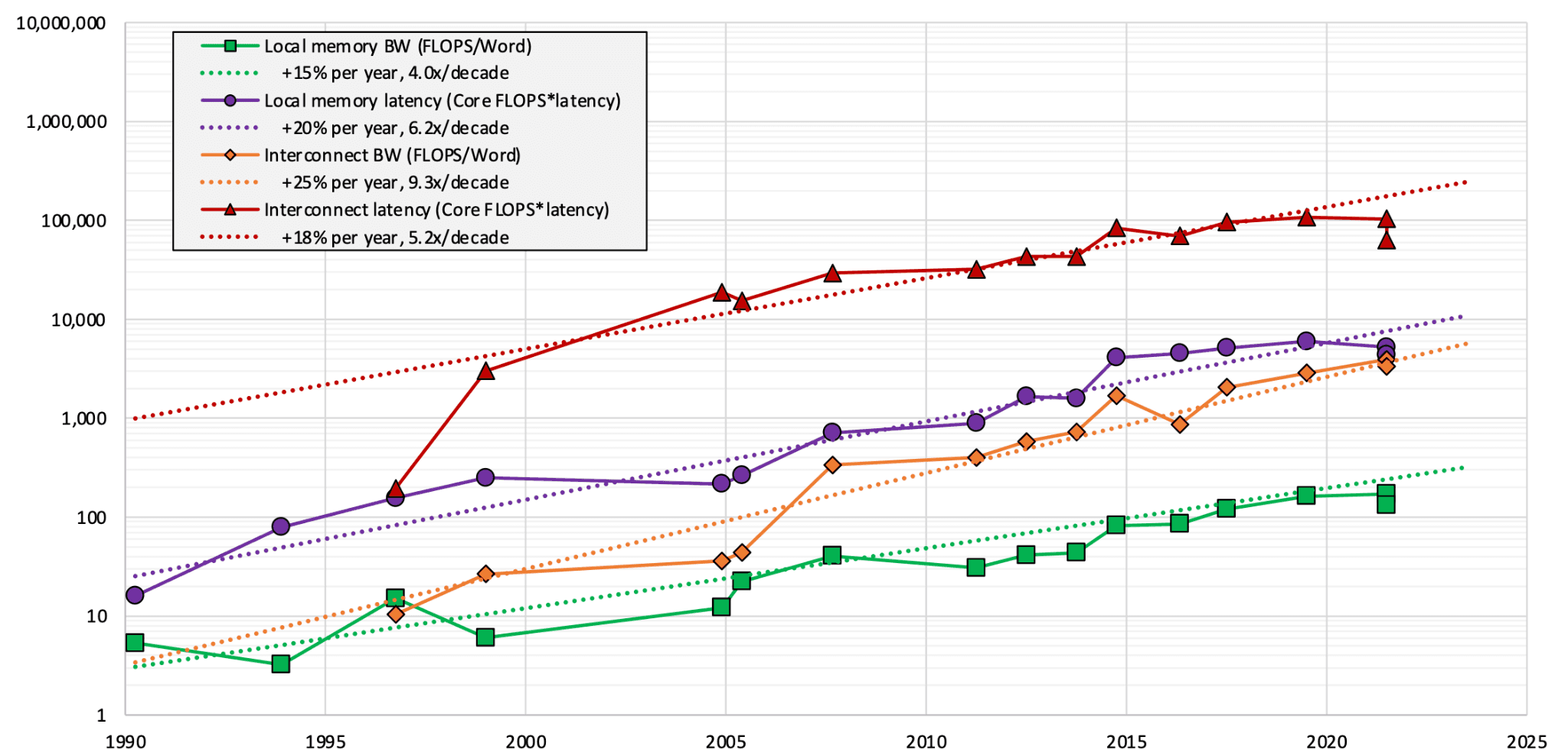
Figure 3: Memory Bandwidth and System Balance in HPC Systems [4]
차트를 해석하면:
초록색과 주황색: 대역폭 대비 컴퓨팅 속도(FLOPS/Word). GPU가 한 번 데이터를 가져왔을 때 얼마나 오래 연산할 수 있는지를 뜻합니다. 이 값이 늘어난다는 것은 컴퓨팅이 상대적으로 너무 빨라지고 있다는 뜻입니다.
빨간색과 보라색: 레이턴시 대비 컴퓨팅 속도(Core FLOPS*latency). 단위 레이턴시 동안 GPU가 수행할 수 있었던 연산 횟수입니다. 이 값이 커질수록 기다리는 동안 놀리는 연산량이 많아지고 있다는 의미입니다.
종합해보면, GPU의 FLOPS는 세대가 바뀔 때마다 빠르게 늘어나지만, latency는 거의 줄어들지 않습니다. 이것이 의미하는 바는 명확한데, 컴퓨팅 파워의 발전 속도가 다른 모든 요소보다 훨씬 가파르다는 것입니다. GPU는 점점 더 많은 연산을 짧은 시간에 수행할 수 있게 되었지만, 데이터를 메모리에서 가져오거나 다른 GPU로 전달하는 속도는 그만큼 빨라지지 않았다는 것인데요. 그러다보니 분산 학습에서 GPU를 많이 사용한다고 선형적으로 연산 속도가 빨라지는 게 아니라, 통신이 오히려 전체 학습 속도를 제한하는 경우가 빈번하게 발생합니다.
2.2 GPU-Centric Communication이란?
통신 병목 문제에 대응하기 위해 GPU 벤더들이 어떤 기술들을 발전시켜왔는지 살펴보겠습니다. 특히 Unat 등의 연구 [5]에서 이 발전 과정을 체계적으로 정리하고 있습니다.
전통적으로 멀티-GPU 통신은 GPU가 아니라 CPU에 의해 이뤄졌습니다. GPU는 태생이 가속기이므로 연산만 담당하고, 통신은 CPU가 오케스트레이션하는 구조인거죠.
이런 CPU-centric 방식에서는 통신 로직이 GPU의 상태나 실행 맥락을 전혀 고려하지 않습니다. "GPU에서 언제 연산이 끝나고, 언제 데이터가 필요해지는지"를 통신 계층이 알지 못하는 구조였기 때문에, GPU 간 통신의 critical path에 CPU가 개입하면서 비효율이 많이 발생했습니다.
하지만 지난 10년간 소위 'GPU-centric 통신'이라 부르는 여러 기술들이 개발됐습니다. 통신 과정에서 CPU의 개입을 최소화하고, GPU가 통신을 직접 시작하고 데이터를 동기화할 수 있게 하는 방향으로 발전해온 것입니다.
Intra-node vs Inter-node
우선 Multi-GPU 통신은 single-node에서 동작하는 intra-node와 multi-node에서 동작하는 inter-node 통신으로 구분해서 살펴볼 필요가 있습니다.
Intra-node: 하나의 GPU 노드는 메모리와 주소 공간을 공유하는 하나의 호스트 위에 여러 GPU가 붙어 있는 구조입니다. 같은 주소 공간을 공유하기 때문에 한 스레드나 프로세스가 GPU를 직접 제어할 수 있습니다.
Inter-node: 서로 다른 호스트 위에 GPU가 붙어 있는 구조로, 각 GPU마다 서로 다른 프로세스가 존재하며 메모리 공유가 되지 않습니다. GPU 사이 통신뿐 아니라, GPU와 NIC 간 상호작용, 프로세스 간 통신까지 처리해야 해서 훨씬 복잡한 환경입니다.
NVIDIA 기술 발전 타임라인
NVIDIA가 GPU를 통신의 중심으로 끌어올리기 위해 단계적으로 쌓아온 기술들을 정리하면 다음과 같습니다.
2006~2011: pinned memory, UVA, IPC처럼 메모리 관리 기법들이 등장
2011~2016: GPUDirect를 통해 CPU를 거치지 않고 GPU 메모리를 액세스하는 길이 열리기 시작
2016~현재: NVLink, NVSwitch와 같은 하드웨어 인터커넥트가 발전하면서 GPU 간 직접 통신이 실질적인 선택지가 됨
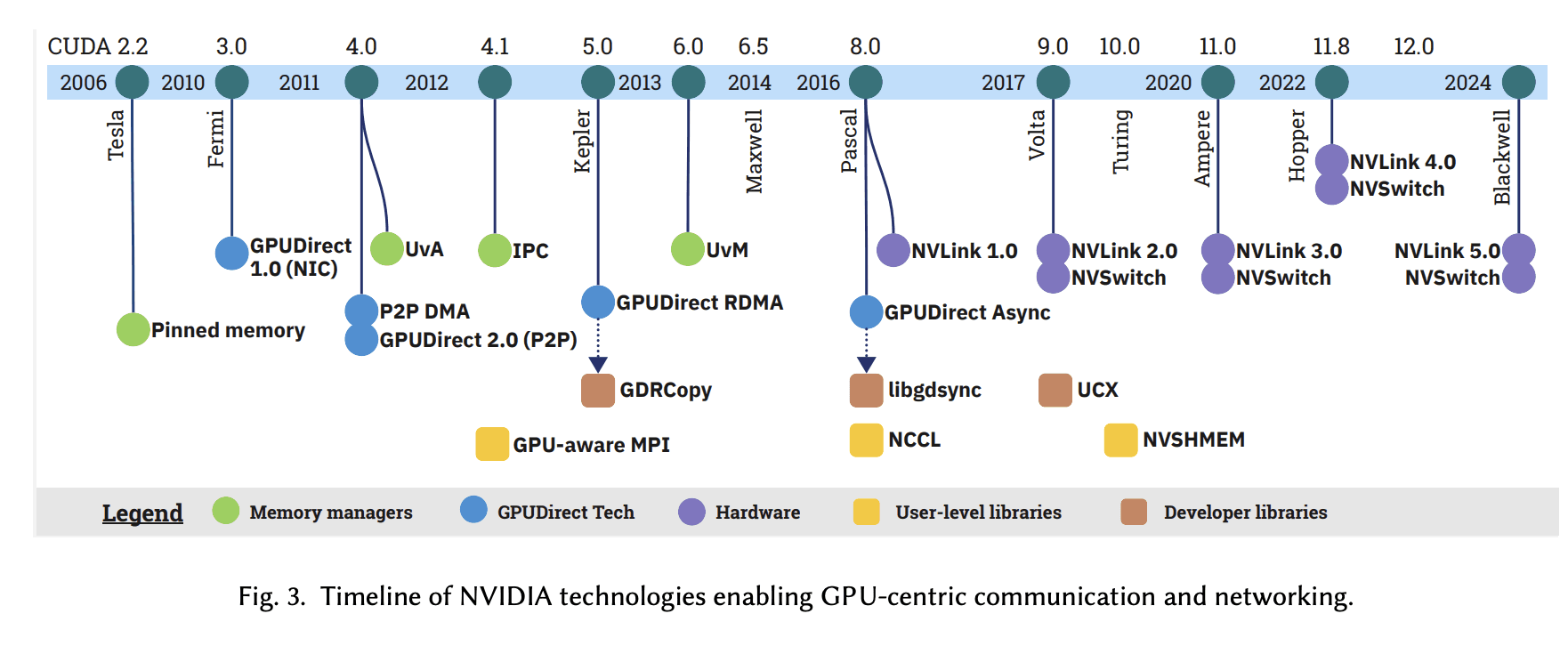
Figure 4: NVIDIA GPU Communication 기술 발전 타임라인 (2006-2024) [5]
이런 메모리 관리 기술, GPUDirect, 하드웨어 지원 위에 NCCL이나 NVSHMEM 같은 유저 라이브러리가 자연스럽게 등장했습니다.
2.3 노드 내 통신 (Intra-node Communication)
한 노드 안에서 발생하는 GPU 커뮤니케이션은 네 가지 타입으로 구분할 수 있습니다 [5]. 구분 기준은 통신의 주체가 누구인지입니다. 통신 API 호출이나 데이터 이동의 중심이 CPU인지 GPU인지에 따라 타입이 나뉩니다.
Type | API | Data Path | Examples |
|---|---|---|---|
① Host Native | Host | Host | cuda/hipMemcpy (No P2P) |
② Host-controlled | Host | Device | cuda/hipMemcpy with P2P |
③ Device Native | Device | Device | NVSHMEM, direct load/store |
④ Host Fallback | Device | Host | Direct load/store (No P2P) |
Table 1: Intra-node Communication Types [5]
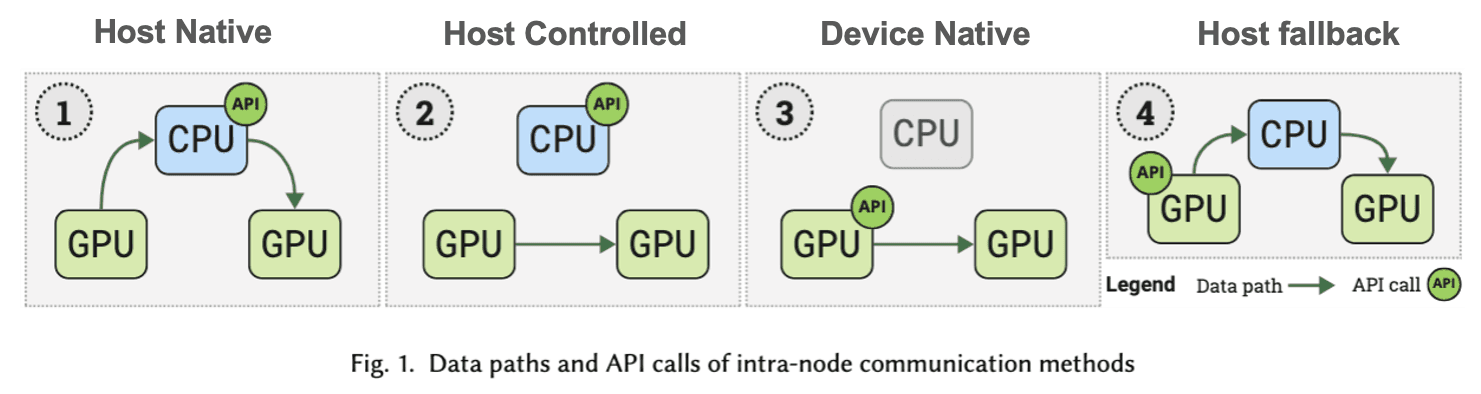
Figure 5: Intra-node Communication Types [5]
Type 1: Host Native
P2P가 없던 시절의 CPU-centric 통신입니다. 공유 자원인 호스트 메모리에 sender GPU가 데이터를 쓰고, receiver GPU가 그 데이터를 읽어가는 방식입니다.
Type 2: Host Controlled
GPUDirect 2.0이 등장하면서 PCIe 링크를 통해 GPU들이 P2P로 서로 액세스할 수 있게 되었습니다. 데이터 이동이 호스트 메모리를 거치지 않고 PCIe 혹은 NVLink 같은 인터커넥트를 통해 직접 이동하는 Host-controlled 방식이 가능해졌습니다. 구체적으로는 receiver GPU가 intermediate buffer를 제공해서 sender가 그 위로 데이터를 전송합니다.
이 덕분에 호스트 메모리로의 복사가 불필요해지면서 오버헤드가 크게 줄어들었으며, GPU-aware MPI, NCCL 같은 주요 라이브러리들이 이 방식을 제공합니다.
Type 3: Device Native
GPUDirect RDMA(Remote Direct Memory Access) 기술이 등장하면서 GPU가 다른 GPU의 메모리 주소에 직접 액세스하는 것이 가능해졌습니다. 디바이스 사이드 API가 데이터 패스와 컨트롤 패스 양쪽에서 모두 CPU 개입을 제거할 수 있게 된 것입니다.
즉, 통신 과정에서 호스트의 개입을 완전히 배제하는 것이 가능해졌고, 이 방식이 NVSHMEM 라이브러리에서 제공하는 통신 방식입니다. 참고로 NVSHMEM은 CUDA 커널에서 직접 호출하는 저수준 라이브러리로, NCCL이 collective 통신에 최적화되어 있다면 NVSHMEM은 GPU가 통신을 직접 제어해야할 때 주로 사용됩니다. 이에 대해서는 후술할 MoE 예시를 통해 더 설명드리겠습니다.
뿐만 아니라 2025년 말에 릴리즈된 NCCL 버전 (2.28.7)에도 GPU-initiated networking [6]이라는 이름으로 유사한 기능이 추가되었습니다.
Type 4: Host Fallback
GPU에서 시작된 커뮤니케이션이더라도 호스트 사이드에서 P2P 통신을 해제한 상태라면, Type 1과 유사하게 CPU 호스트 메모리를 거쳐가도록 fallback됩니다.
2.4 노드 간 통신 (Inter-node Communication)
Inter-node GPU communication에서는 NIC(네트워크 인터페이스 카드)이 통신 과정에 추가되면서 data path 복잡도가 올라갑니다 [5].
마찬가지로 아래 표와 같이 Type을 구분해보면, Type 1에서 5로 갈수록 구성 요소들이 점차 GPU 측으로 이동하면서 통신 과정 전반에 대한 제어 권한이 점차 CPU에서 GPU 쪽으로 넘어옵니다.
Data path 측면: NIC에 도달하기까지 필요한 데이터 복사 횟수가 크게 줄어듦
Control path 측면: 레지스터 접근이나 트리거와 같은 제어 작업이 점점 더 GPU에서 직접 수행됨
Type | API | Register | Trigger | Data Path | Examples |
|---|---|---|---|---|---|
① Host Native | Host | Host | Host | Through host (2 copies) | GPU-Aware MPI before ② |
② GPUDirect 1.0 | Host | Host | Host | Through host (1 copy) | GPU-Aware MPI, NCCL |
③ GPUDirect RDMA | D/H | Host | Host | Direct | GPU-Aware MPI, NCCL, NVSHMEM |
④ GPUDirect Async | D/H | Host | Device | Depends on ③ | GPU-Aware MPI, NVSHMEM |
⑤ Device Native | Device | Device | Device | Depends on ③ | NVSHMEM with IBGDA |
Table 2: Inter-node Communication Types [5]
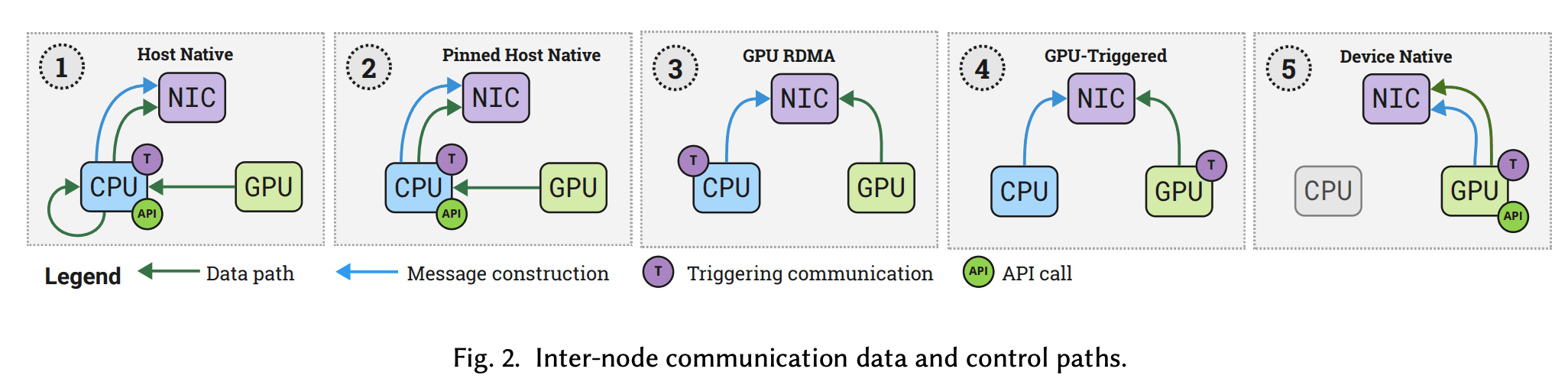
Figure 6: Inter-node Communication Types (Type 1-5) [5]
Type 1: Host Native (Naive)
CPU-centric 통신입니다. GPU가 먼저 CPU 호스트의 버퍼에 데이터를 쓴 다음 NIC이 그 데이터를 읽어갑니다. 초창기에는 심지어 GPU의 호스트 버퍼와 NIC의 호스트 버퍼가 달라서 버퍼 간 이동 때문에 불필요한 복사가 한 번 더 있었습니다.
Type 2: Pinned Host Native
Pinned memory 기술이 개발되면서 GPU와 NIC이 버퍼를 공유하게 되었고, 불필요한 복사가 한 번 줄어들었습니다. 하지만 여전히 모든 제어가 CPU에 있는 형태입니다.
Shared pinned memory는 CPU 메모리 중에서 GPU나 네트워크 카드가 바로 접근해도 위치가 바뀌지 않게 고정해둔 공용 버퍼입니다.
Type 3: GPU RDMA
GPUDirect RDMA 기술이 개발되면서 NIC에서도 PCIe를 통해 GPU 메모리를 직접 액세스할 수 있게 되었습니다. CPU 호스트 메모리 개입이 없어지면서 data path가 많이 개선된 방식으로, GPU-centric까지는 아니어도 GPU-aware한 통신이 가능해졌다고 저자는 구분하고 있습니다.
NCCL, NVSHMEM 같은 주요 라이브러리들은 이 방식을 기본적으로 지원합니다.
Type 4: GPU-Triggered
GPU가 데이터 전송에 대한 신호를 트리거하도록 control path를 개선한 것입니다. GPU 메모리와 네트워크 사이의 데이터 이동을 비동기적으로 처리하는 GPUDirect Async 기술이 등장하면서 가능해졌습니다 [7].
하지만 GPU-triggered에서 전송할 데이터를 레지스터하는 부분은 여전히 CPU 쪽의 proxy thread에 의해 수행된다는 점에서 최적화의 여지가 존재합니다.
Type 5: Device Native
CPU 쪽 proxy thread까지 제거하고, CPU가 kernel launch 이외에 아무것도 개입하지 않는 버전이 Device Native입니다.
NVSHMEM 라이브러리에서 지원하는 IBGDA(InfiniBand GPUDirect Async)가 inter-node 상황에서의 대표적인 Device Native 예시입니다. DeepSeek에서 개발한 DeepEP라는 MoE 전용 통신 엔진에서 이 방식을 사용하고 있으며, DeepEP GitHub issue에도 "IBGDA is necessary and crucial to run DeepEP"라고 언급되어 있습니다 [8].
3. GPU 통신 라이브러리와 활용
지금까지 GPU 통신이 어떻게 발전해왔는지 살펴봤습니다. 그렇다면 실제 분산 학습에서는 이 기술들이 어떻게 활용되는지 알아보겠습니다.
3.1 Communication Primitives
분산 학습에서 반복적으로 등장하는 통신은 일반적으로 소수의 communication primitive들로 귀결됩니다.
Data Parallelism → AllReduce
데이터 병렬에서는 각 GPU가 서로 다른 미니배치를 처리하지만, 모델 파라미터는 모두 동일합니다. 각 GPU는 backward 단계에서 서로 다른 gradient를 계산하게 되고, 이 gradient들을 하나로 합쳐서 평균 내는 과정이 필요합니다.
AllReduce는 모든 GPU가 각자 가진 값을 모아서 하나로 합친 다음, 그 결과를 다시 모든 GPU에게 나눠주는 오퍼레이션입니다.
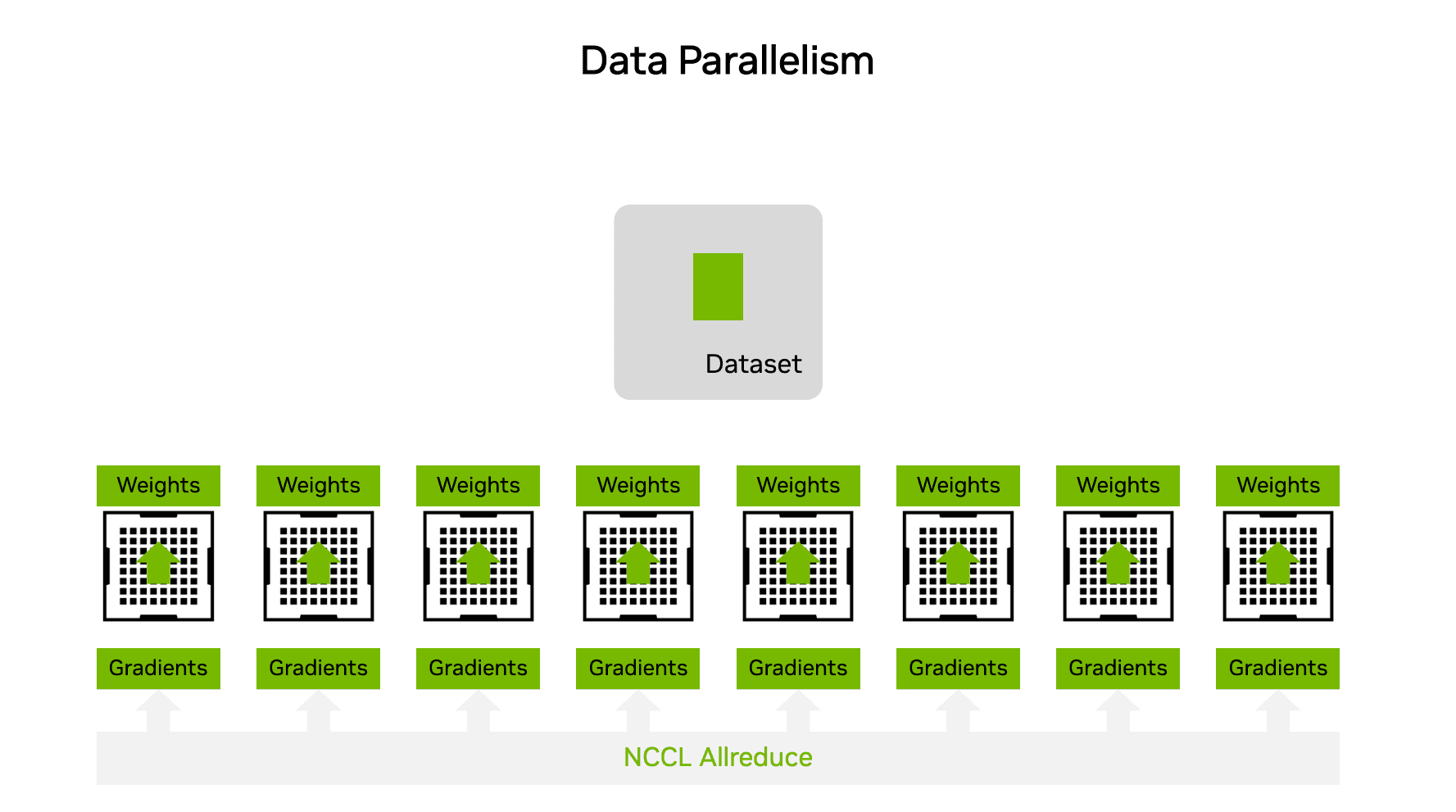
Figure 7: Data Parallelism에서 gradient를 AllReduce로 동기화하는 과정
Tensor Parallelism → AllGather
Tensor Parallelism의 경우 하나의 레이어를 여러 GPU가 나눠서 연산하기 때문에 각 GPU가 결과의 조각만 가지고 있습니다. 다음 연산을 위해 조각난 결과를 다시 모아야 할 때 AllGather가 사용됩니다.
AllGather는 각 GPU가 가진 조각을 서로 교환해서, 모든 GPU가 전체 결과를 갖게 만드는 연산입니다. 반대로, 연산 결과를 다시 쪼개서 분산시키는 경우에는 ReduceScatter가 사용됩니다.
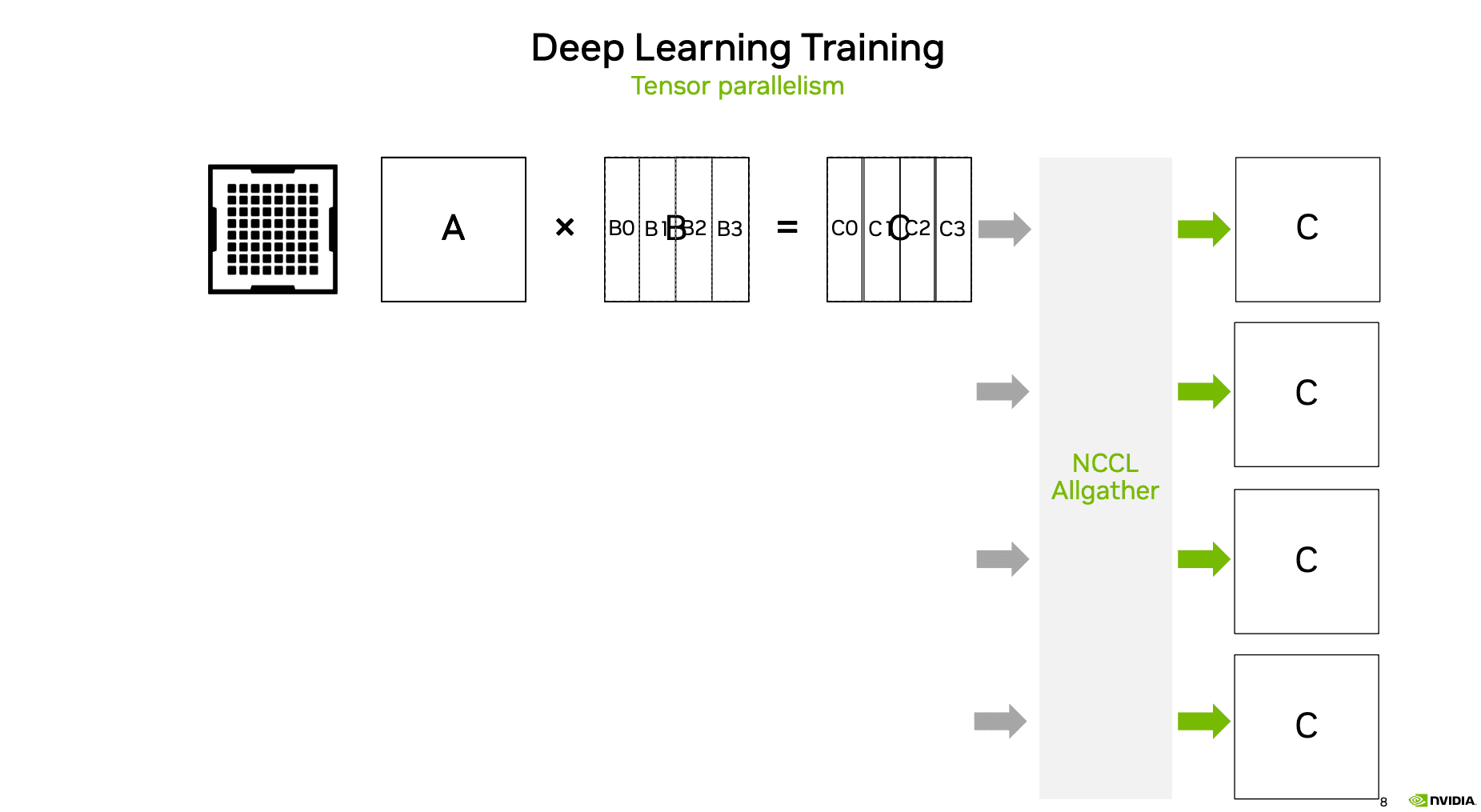
Figure 8: Tensor Parallelism에서 행렬 연산을 분할하고 AllGather로 결과를 모으는 과정
Pipeline Parallelism → Send/Recv
파이프라인 병렬에서는 모델이 레이어 단위로 나뉘어 있고, 각 스테이지가 서로 순차적으로 연결되어 있습니다. 따라서 모두가 같은 통신에 동시에 참여하는 collective 통신보다는 인접한 GPU 간의 point-to-point 통신이 주로 사용됩니다.
앞 스테이지에서 나온 activation을 다음 스테이지로 넘기기 위해 Send/Recv 같은 단순한 메시지 전달 오퍼레이션이 사용됩니다.
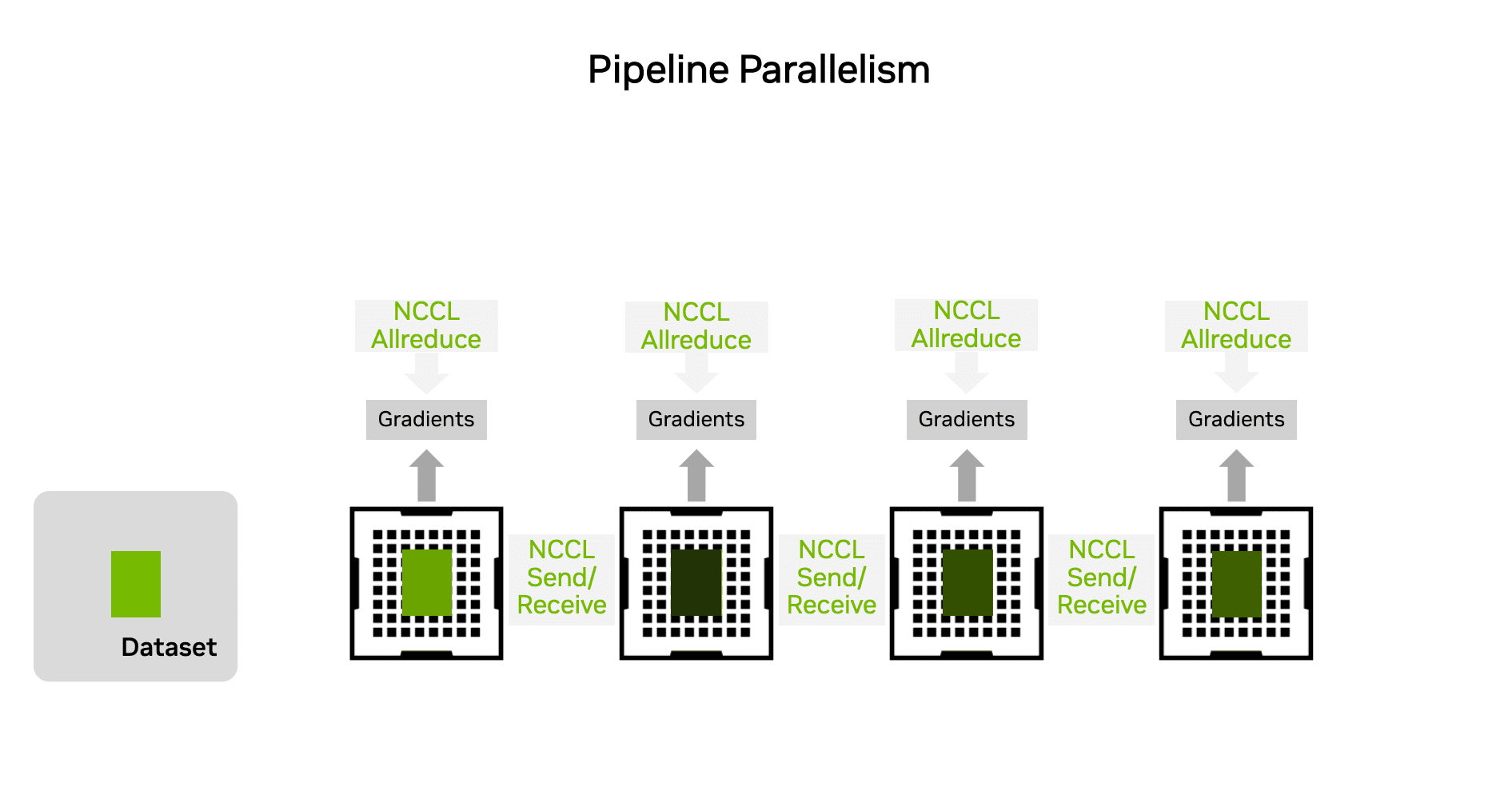
Figure 9: Pipeline Parallelism에서 Stage 간 activation 전달
정리
Parallelism Type | Primary Operation |
|---|---|
Data Parallelism | AllReduce |
Tensor Parallelism | AllGather, ReduceScatter |
Pipeline Parallelism | Send/Recv |
MoE (Expert Parallel) | All-to-All |
FSDP | AllGather, ReduceScatter |
NCCL은 이런 primitive들을 GPU 환경에서 효율적으로 구현해 놓은 라이브러리라고 볼 수 있습니다.
3.2 NCCL의 AllReduce 구현 예시
대표적인 primitive인 AllReduce를 구현하기 위한 알고리즘으로 Ring과 Tree 방식이 있습니다. NCCL의 내부 동작을 분석한 "Demystifying NCCL" [9] 논문에서 이 알고리즘들이 실제로 GPU 환경에서 어떻게 동작하는지 설명하고 있습니다.
Ring AllReduce
Ring topology 방식에서는 매 이터레이션마다 하나의 이웃한 GPU에게 하나의 벡터씩만 보내는 방식으로, 어떤 링크도 놀지 않고 어떤 GPU도 대기하지 않게 데이터를 이동시키는 대역폭 극대화 방식입니다.
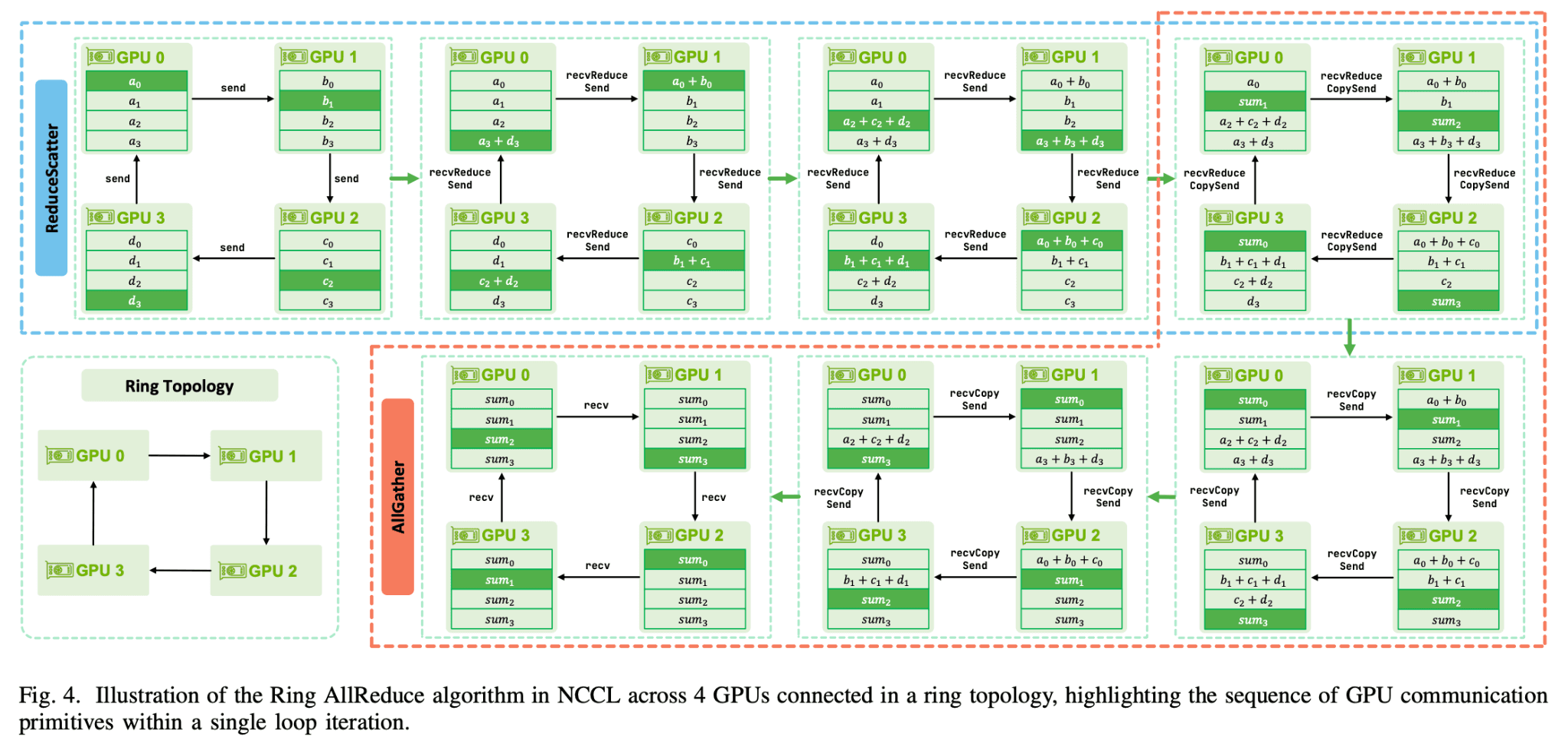
Figure 10: Ring AllReduce 알고리즘 - ReduceScatter → AllGather [9]
Tree AllReduce
Tree topology에서는 GPU들을 트리 구조로 구성해서 먼저 reduce를 빠르게 수행한 다음 그 결과를 다시 broadcast하는 방식입니다. 통신 단계 수가 로그 스케일로 줄어들기 때문에 레이턴시 최적화된 방식이라고 볼 수 있습니다.
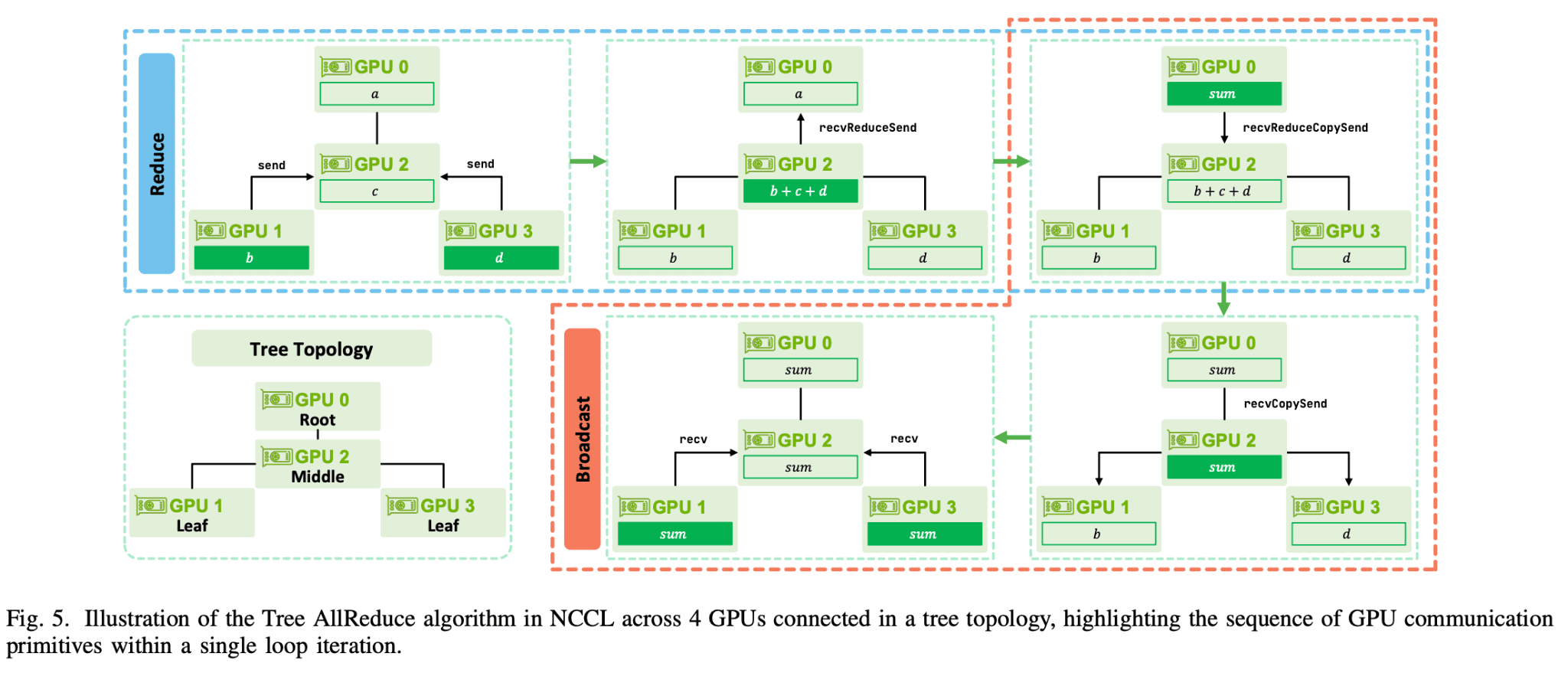
Figure 11: Tree AllReduce 알고리즘 - Reduce → Broadcast [8]
Ring은 large message에 좋고 Tree는 small message에 유리하기 때문에, NCCL은 상황에 따라 둘 중에 선택하거나 조합해서 사용합니다. 물론 실제로는 이 두 방식 외에도 여러 가지 방식 중에서 선택합니다.
또한 같은 AllReduce나 Send/Recv라도 실제 성능은 하드웨어 조건에 크게 의존하기 때문에, NCCL은 NVLink, PCIe, NIC 구성 같은 실제 시스템 토폴로지도 같이 고려해서 최적의 경로와 방식을 선택합니다.
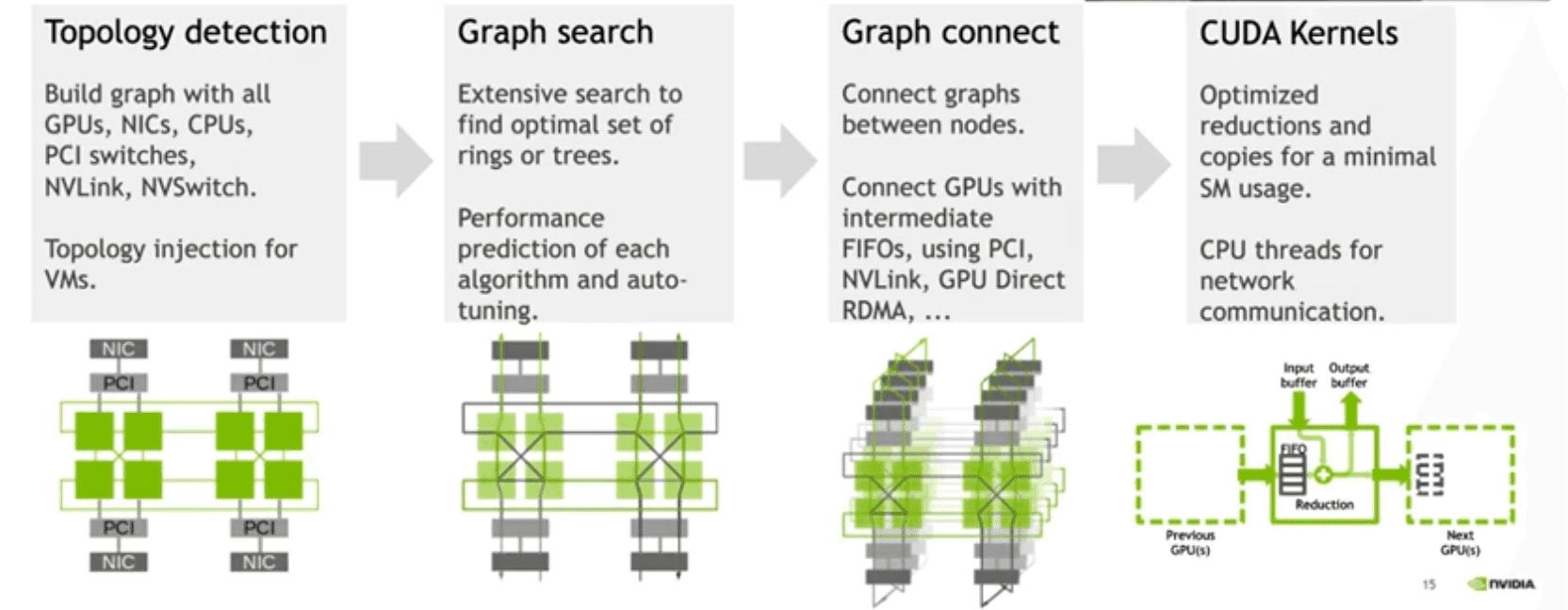
Figure 12: NCCL Architecture - Topology Detection → Graph Search → Graph Connect → CUDA Kernels
3.3 MoE: Device-Native가 중요해진 이유
NCCL은 AllReduce 같은 정형화된 collective 통신에서 거의 최적에 가까운 성능을 보여줍니다. 실제로 대부분의 데이터 병렬, 텐서 병렬 학습은 NCCL 위에서 매우 잘 동작합니다. 하지만, 당연하게도 모든 워크로드가 이렇게 잘 구조화된 collective 통신으로 표현되지는 않습니다.
MoE의 불규칙한 통신 패턴
대표적인 예가 Mixture-of-Experts, 즉 MoE 모델입니다.
MoE에서는 토큰이 어떤 expert로 가느냐에 따라 통신 대상과 통신량이 입력마다 달라집니다. 이 경우 통신은 AllReduce처럼 한 번에 모아서 처리하기 어렵고, 레이어 내부에서 불규칙한 All-to-All 통신이 발생합니다.
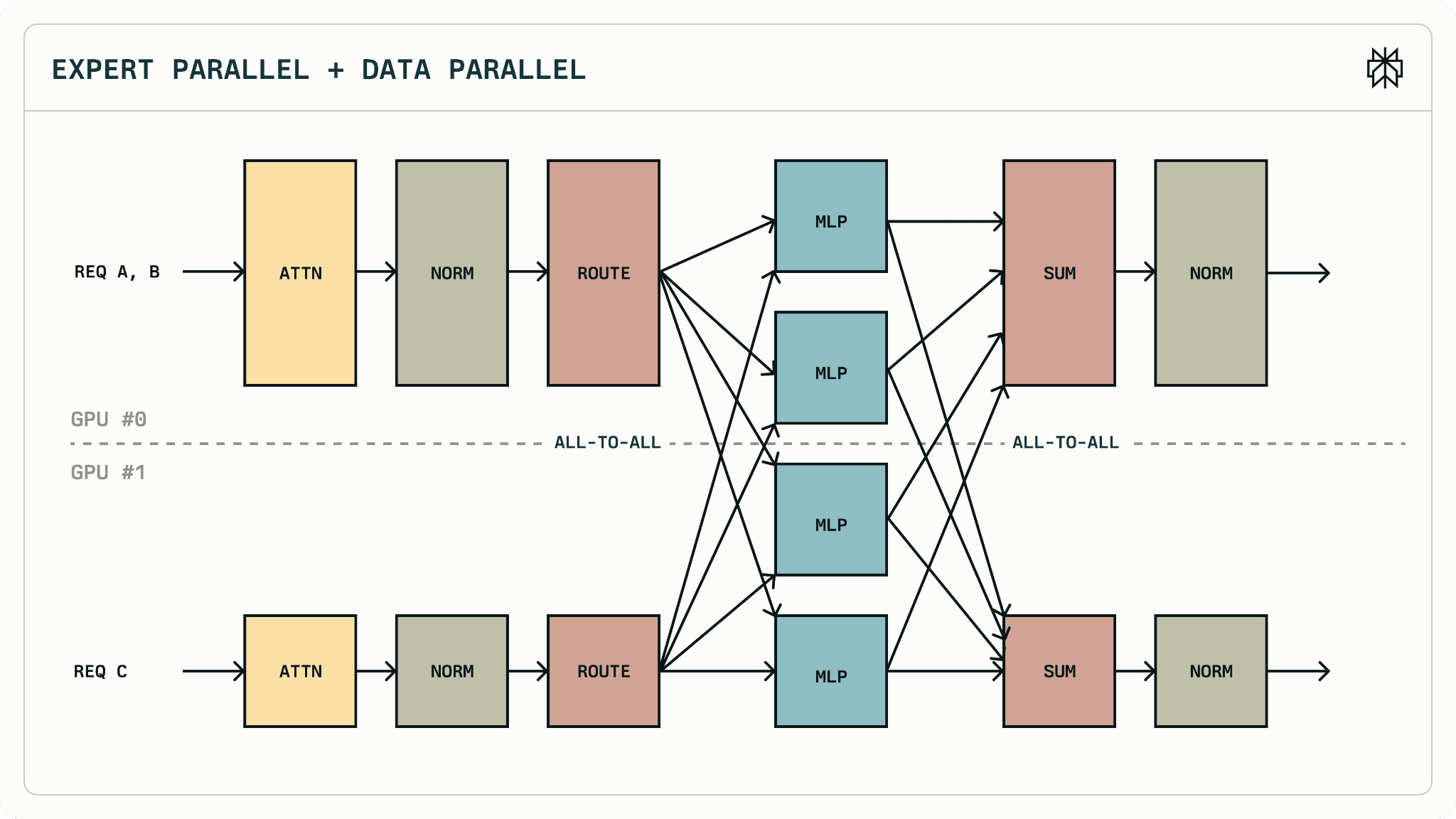
Figure 13: MoE - Expert Parallel + Data Parallel에서 All-to-All 통신 [10]
이런 워크로드에서는 기존 NCCL의 강점을 그대로 활용하기 어렵고, 통신 자체를 GPU 실행 흐름에 더 밀접하게 통합한 다른 접근이 필요해집니다.
Perplexity와 DeepSeek의 구현
MoE 통신은 receiver 입장에서 토큰이 어디서 날아올지 몰라서 기본적으로 All-to-All 방식의 통신입니다. 모든 데이터가 준비될 때까지 기다렸다가 한 번에 보내고 받는 collective 통신 방식은, 토큰마다 목적지가 다르고 준비되는 시점도 다른 MoE에서는 GPU를 계속 대기 상태로 만들기 때문에 비효율적입니다.
이를 해결하기 위해 Perplexity나 DeepSeek같은 회사는 내부적으로 카운터 같은 메커니즘을 사용해서 All-to-All을 더 잘게 쪼개서 GPU가 직접 처리하게 만든 커널을 제시했습니다 [10].
이런 구조를 가능하게 하려면:
GPU가 통신을 직접 시작할 수 있어야 하고
장치 간 메모리를 직접 접근할 수 있어야 합니다
Perplexity 구현은 NVSHMEM을 기반으로, GPUDirect RDMA와 GPU-initiated networking을 활용합니다.
IBGDA vs IBRC 성능 비교
IBRC: CPU proxy가 GPU-NIC 통신을 제어하는 GPU-triggered 방식
IBGDA: GPU가 온전히 통신을 주도하는 Device-native 방식
128 tokens per GPU, multi-node EP128 설정에서의 latency 비교를 보면:
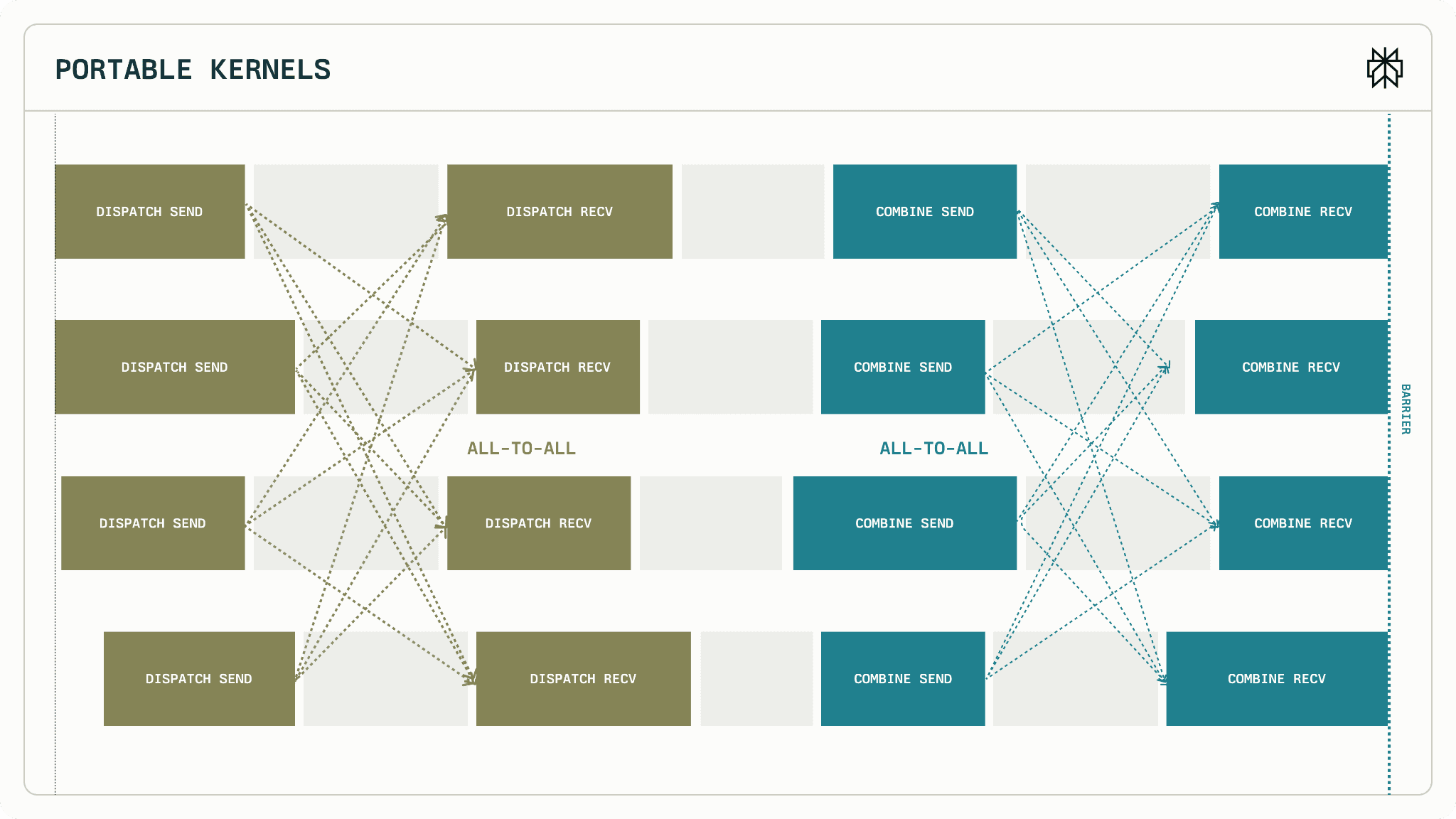
Figure 14: IBGDA vs IBRC 성능 비교 (128 tokens/GPU, multi-node EP128) [10]
Operation | IBGDA | IBRC |
|---|---|---|
pplx Dispatch | ~300 μs | ~2000 μs |
pplx Combine | ~300 μs | ~4700 μs |
IBGDA(Device Native)가 IBRC(GPU-Triggered)보다 약 3.6배 낮은 latency를 보여줍니다.
4. 정리 및 결론
이 글에서 다룬 내용을 정리하면,
HPC 시스템의 하드웨어 제약으로 인해 통신이 컴퓨팅 속도를 따라가지 못합니다. GPU의 연산 성능은 빠르게 발전했지만, 메모리 bandwidth와 latency는 상대적으로 정체되어 있습니다.
분산 트레이닝에서 활용되는 여러 병렬화 기법에 통신 병목이 발생할 수 있습니다. Data Parallelism의 AllReduce, Tensor Parallelism의 AllGather, Pipeline Parallelism의 Send/Recv 모두 GPU 간 데이터 이동이 필요합니다.
이 문제를 해결하기 위해 GPU-centric 통신 기술이 발전해왔습니다. Host Native에서 시작해 Host Controlled, GPU RDMA, GPU-Triggered를 거쳐 Device Native까지, CPU의 개입을 점차 줄이는 방향으로 발전했습니다.
MoE 같은 불규칙한 통신 패턴이 등장하면서 GPU-centric 통신이 더욱 중요해졌습니다. IBGDA 같은 Device Native 방식이 IBRC 대비 3.6배 이상의 latency 개선을 보여주는 것이 그 증거입니다.
GPU 통신 기술의 발전은 LLM 학습과 인퍼런스의 스케일 확장에 필수적인 요소입니다. 다시 처음 질문으로 돌아가면, torchrun에서 참조하는 NCCL과 같은 라이브러리들이 이러한 통신 기술들을 기반으로 계속해 개선되고 있습니다. 이 글을 통해 GPU를 더 추가해도 분산 학습의 성능이 기대만큼 늘지 않을 때, 그 밑에서 어떤 패턴으로 통신 병목이 발생하고 있을지 조금이나마 감을 잡을 수 있기 바랍니다.
References
NVIDIA. H100 Tensor Core GPU Specifications.
PyTorch. "Distributed Communication Package - torch.distributed." PyTorch Documentation.
Microsoft Research (2020). "DeepSpeed: Extreme-scale model training for everyone." Microsoft Research Blog, Sep 10, 2020.
McCalpin, J.D. (1995). "Memory Bandwidth and Machine Balance in Current High Performance Computers." IEEE Computer Society TCCA Newsletter, Dec 1995.
Unat, D., Turimbetov, I., Issa, M.K.T., Sağbili, D., Vella, F., De Sensi, D., & Ismayilov, I. (2024). "The Landscape of GPU-Centric Communication." arXiv:2409.09874 [cs.DC].
Khaled Hamidouche, John Bachan, Pak Markthub, Peter-Jan Gootzen, Elena
Agostini, Sylvain Jeaugey, Aamir Shafi, Georgios Theodorakis, Manjunath
Gorentla Venkata, "GPU-Initiated Networking for NCCL", arXiv:2511.15076, 2025.
LeBeane, M., Hamidouche, K., Benton, B., Breternitz, M., Reinhardt, S.K., & John, L.K. (2017). "GPU triggered networking for intra-kernel communications." Proceedings of SC'17: The International Conference for High Performance Computing, Networking, Storage and Analysis.
DeepSeek (2025). DeepEP GitHub Repository - Issue #9: "Is IBGDA necessary?"
Hu, Z., Shen, S., Bonato, T., Jeaugey, S., Alexander, C., Spada, E., Dinan, J., Hammond, J., & Hoefler, T. (2025). "Demystifying NCCL: An In-depth Analysis of GPU Communication Protocols and Algorithms." arXiv:2507.04786.
Perplexity AI (2025). pplx-kernels: Efficient and Portable Mixture-of-Experts Communication.