3D pose estimation with textured object

작성자 :
황인우
Motivation
로봇이 실제로 물체를 집기 위해서는 카메라를 통해 얻은 이미지를 이용하여 3D 물체의 pose를 알아내어야 합니다. 본 포스팅 에서는 전통적인 computer vision 방법과 딥러닝을 결합하여 textured object 의 3d pose를 추정하는 방법에 대해 간단히 소개하고자 합니다.
Privileged information
먼저, world 좌표계와 카메라를 통해 얻은 2d좌표사이의 관계에 대해 알아보겠습니다. 카메라를 이용하여 사진을 찍는다는 것은 world 좌표(X,Y,Z) 를 특정 2d 평면의 한점(u,v)으로 projection 시키는 것이라고 할 수 있습니다. 이 때, world 좌표와 2d 좌표 상에는 다음과 같은 matrix multiplication 관계가 존재하며, 각각은 camera parameter, world 좌표계와 camera 좌표계 사이의 rotation 및 translation 를 의미합니다.
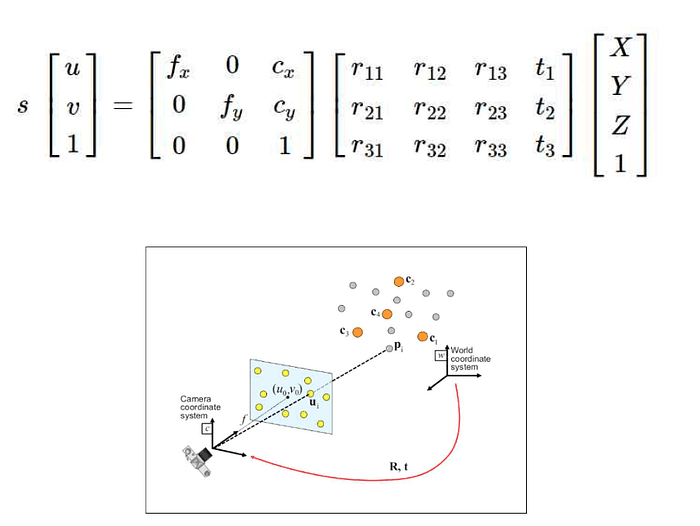
또한, opencv의 pnpsolver 를 활용하면 이미지 좌표 (u,v) 와 world좌표 (X,Y,Z)의 pair 가 7개 이상 존재하고 카메라 parameter를 모두 안다고 가정할 때, 위의 관계식에서 3*4 matrix에 해당하는 rotation 및 translation 정보를 얻을 수 있습니다. 즉, inverse problem 형태의 문제를 해결할 수 있습니다.
computer vision에서 keypoint 를 detect 하는 문제는 오래전부터 다뤄져 왔습니다. 기존의 방식들은 FAST, SIFT ,ORB 와 같은 hand-crafted feature 기반의 방법들이 널리 사용되어 왔습니다. R2D2는 딥러닝을 활용하여 keypoint를 extract 하는 방법으로 keypoint 의 repeatability 및 reliability 학습을 위해 unsupervised loss 및 Average Precision (AP) metric를 활용한 listwise ranking loss를 제안하여 image transformation에 보다 robust 한 keypoint를 extract할 수 있는 알고리즘입니다.
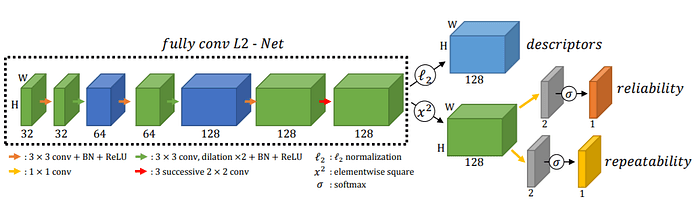
overview of R2D2 network
Algorithms
이제, 위의 지식들을 종합하여 texture가 존재하는 물체의 3d pose를 추정하는 방법에 대해 소개하겠습니다.
이에 앞서 우선 detect하고자 하는 3d object에 대한 vertex 정보가 있다고 가정합시다. (예를 들어, 단위 정육면체 구조이면 (0,0,0),(1,0,0),..(1,1,1) 와 같은 vertex 위치 ⠀정보) 서술의 편의상, 이를 만족하는 좌표계를 object 좌표계라고 정의하겠습니다.
step1. model registration
object를 특정 view에서 찍은 이미지를 얻었다고 가정합시다. model registration 과정의 목적은 얻은 이미지를 바탕으로 object의 keypoint를 얻어내고, 이 keypoint 의 object 좌표계 에서의 위치를 알아내어 pair로 저장하는 것입니다.
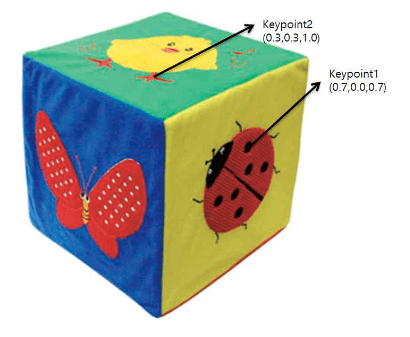
model registration 과정의 목적
R2D2 keypoint extractor를 이용하면, 해당 이미지에 존재하는 keypoint를 모두 얻을 수 있습니다. 하지만, 우리가 얻고자 하는 것은 object 에 존재하는 keypoint 정보입니다. 따라서, 해당 keypoint가 object에 존재하는 정보인지 아닌지를 판별하는 과정이 필요하게 됩니다.
아직, object에 대한 정보가 아무것도 없는 상태이기 때문에, 직접 수작업으로 이미지의 좌표와 object 좌표계를 대응시켜주는 과정이 필요합니다. 이 과정을 거치게 되면, pnpsolver를 통해 카메라 좌표와 object 좌표사이의 관계를 얻어낼 수 있습니다. 또한, Möller–Trumbore intersection algorithm를 적용하면, object에 존재하는 keypoint만을 얻을 수 있고, keypoint의 object계에서의 3차원 좌표를 계산할 수 있습니다.
위의 과정을 충분히 반복하여 object를 다양한 view에서 찍은 이미지에 model registration 과정을 진행하게 되면, detect하고자 하는 물체에 존재하는 모든 keypoint와 해당하는 object 좌표계에서의 3차원 위치를 pair로 저장할 수 있습니다. 이제 이 정보를 활용하여 model detection 단계에서 새로운 view에서 해당 object 의 이미지를 얻었을 때, 3d pose를 추정할 수 있습니다.
step2. model detection
model detection과정의 목적은 앞서 model registration 과정을 통해 얻은 다양한 keypoint 와 해당 keypoint 의 object 좌표계에서의 3차원 위치 pair 정보를 가지고, 새로운 camera view에서 찍은 object 이미지를 얻었을 때, object의 3d pose를 얻어내는 것입니다.
R2D2 network를 이용하여 새로운 camera view에서 찍은 이미지에서의 keypoint를 얻을 수 있습니다. 이제, 새로 얻어낸 keypoint 들과 model registration 과정을 통해 얻은 keypoint 의 matching을 통해 새로 얻어낸 keypoint에 대응하는 object 좌표계에서의 3차원 위치를 얻을 수 있습니다.

keypoint matching
새로운 이미지에서 얻어낸 keypoint와 이에 해당하는 object 좌표계에서의 3차원 위치의 pair가 충분히 생기게 되면, pnpsovler를 통해 rotation 및 translation 정보를 얻을 수 있습니다. 또한, 우리는 object 좌표계에서의 object의 vertex 좌표를 알고 있고, 현재 view에 서의 실제 camera의 위치와 camera matrix를 알수 있으므로 이를 결합하면 object의 world 좌표를 얻을 수 있습니다.

Gazebo simulation 환경에서 detect한 모습
이 방법은 textured object에만 사용할 수 있고, model registration 과정이 선행되어야 하므로 번거로울 수 있지만, 3d pose가 필요한 알고리즘을 실제 로봇 등에 적용해보고 싶을 때, 사용할 수 있습니다.
References
https://docs.opencv.org/master/dc/d2c/tutorial_real_time_pose.html
R2D2: Repeatable and Reliable Detector and Descriptor (https://arxiv.org/pdf/1906.061)