200115 High Fidelity Speech Synthesis with Adversarial Network
URL: https://openreview.net/forum?id=r1gfQgSFDr
Overview
- 제목: High Fidelity Speech Synthesis with Adversarial Network
- 저자: Mikolaj Binkowski et al. (Imperial College of London + Deepmind)
- 학회: ICLR 2020 Accept (Talk)
- 코드: (third-party) https://github.com/yanggeng1995/GAN-TTS (중국어?)
Introduction
- Background
Neural TTS 는 text 를 받아 mel-spectrogram 과 같은 intermediate representation 을 예측하는 acoustic model 과, 그를 청취 가능한 raw audio 로 변환해주는 vocoder 로 나뉜다.
- Neural acoustic model의 예시: Tacotron, Transformer-TTS, MelNet
- Neural vocoder의 예시: WaveNet, WaveRNN, WaveGlow, MelGAN
보통 TTS 성능 평가는 사람이 직접 들어보며 자연스러움을 평가하는 MOS(Mean Opinion Score) 를 사용한다.
- Contribution
이 논문에서는 linguistic feature extractor 의 힘을 빌려, text로부터 raw audio를 한번에 만들어내는 generator 를 GAN 으로 학습시킨다. 또한, MOS 대신 사용될 수 있는 metric 을 4가지 제시한다.
GAN-TTS
Note: 1번째 깊이의 bullet 까지만 읽어도 큰 그림을 이해하는 데에 문제가 없습니다. 구현에 필요한 detail 까지 알고 싶으시다면 전체를 읽으세요.
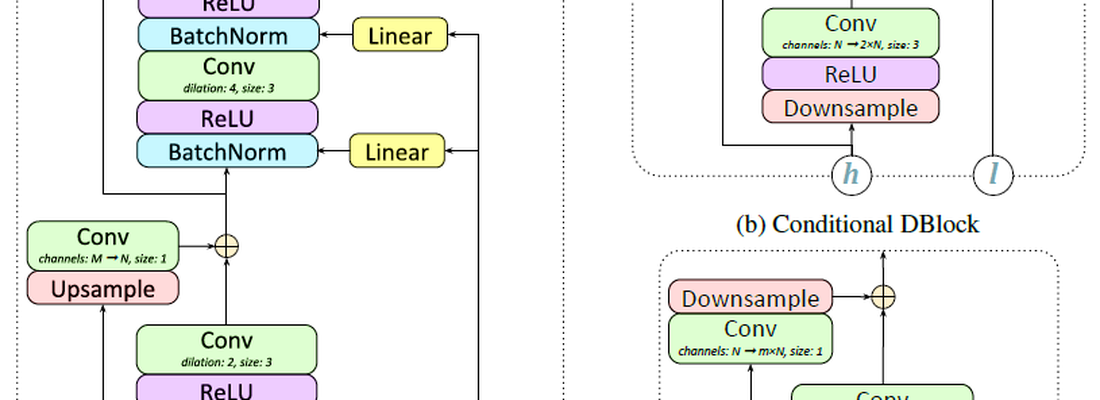
- Generator (이하 “G”)
- Input: [Batch, 567, Time], [Batch, Latent dimension]. Linguistic feature extractor 로 text 로부터 linguistic feat. + pitch info. 를 200Hz 의 sample rate 로 만들어낸다.
- 최종 결과물의 길이도 linguistic feature extractor 가 결정하는 셈.
- 2.0초 만큼의 고정된(!) 길이의 input 이 들어간다.
- Output: [Batch, 1, Time]. Sample rate 24kHz 의 raw audio.
- Tanh activation 으로 마무리해 (-1, 1) 의 값을 갖는 mu-law encoding 으로 표현.
- 가장 앞/뒤의 conv. 를 제외하고 총 7개의 GBlock 으로 구성됨.
- 각각의 GBlock 는 2개의 residual block 으로 이루어져 있으며, 필요에 따라 n배의 upsampling을 한다.
- 200Hz 에서 24000Hz 로 총 120배가 되어야 하기 때문에 차례로 1, 1, 2, 2, 2, 3, 5배의 upsampling 을 수행. 각각의 채널 수는 Appendix A.2 의 Table 1 참조.
- Residual block 에 있는 conditional batch norm layer 를 통해 latent vector z (128차원) 삽입.
- 단, z 가 바로 사용되지는 않고 AdaIN 과 유사하게 linear layer 를 거쳐 삽입.
- Multi-speaker 의 경우 speaker ID 에 따른 one-hot vector 를 z 와 concat. 하여 삽입.
- Dilated conv. 사용: kernel size 3, dilation factor 1 → 2 → 4 → 8
- Input: [Batch, 567, Time], [Batch, Latent dimension]. Linguistic feature extractor 로 text 로부터 linguistic feat. + pitch info. 를 200Hz 의 sample rate 로 만들어낸다.
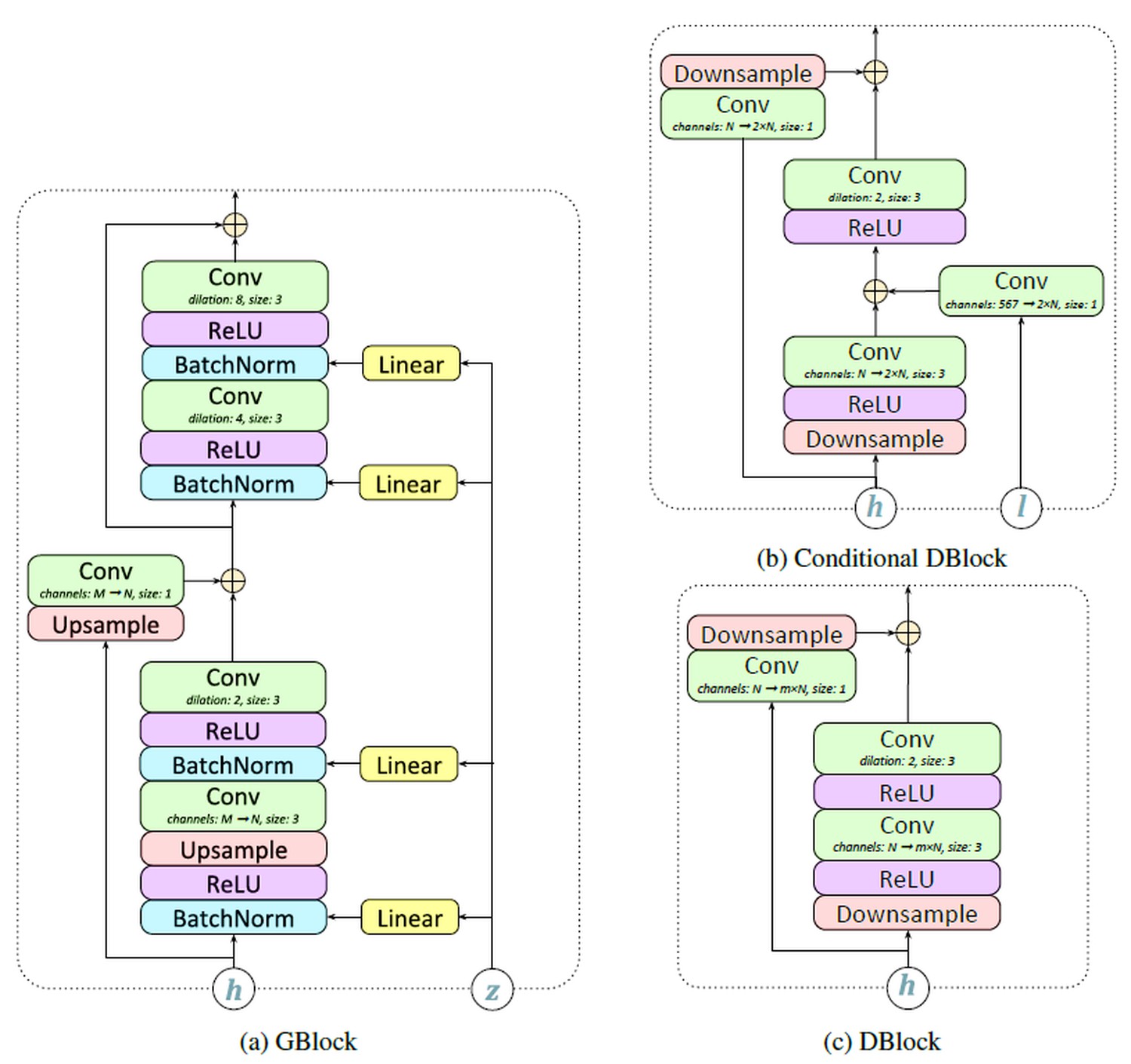
- Discriminator (이하 “D”)
- Input: [Batch, 1, Time], [Batch, 567, Time]. Sample rate 24kHz 의 raw audio, (Generated & Real) 그에 해당되는 linguistic feat. + pitch info.
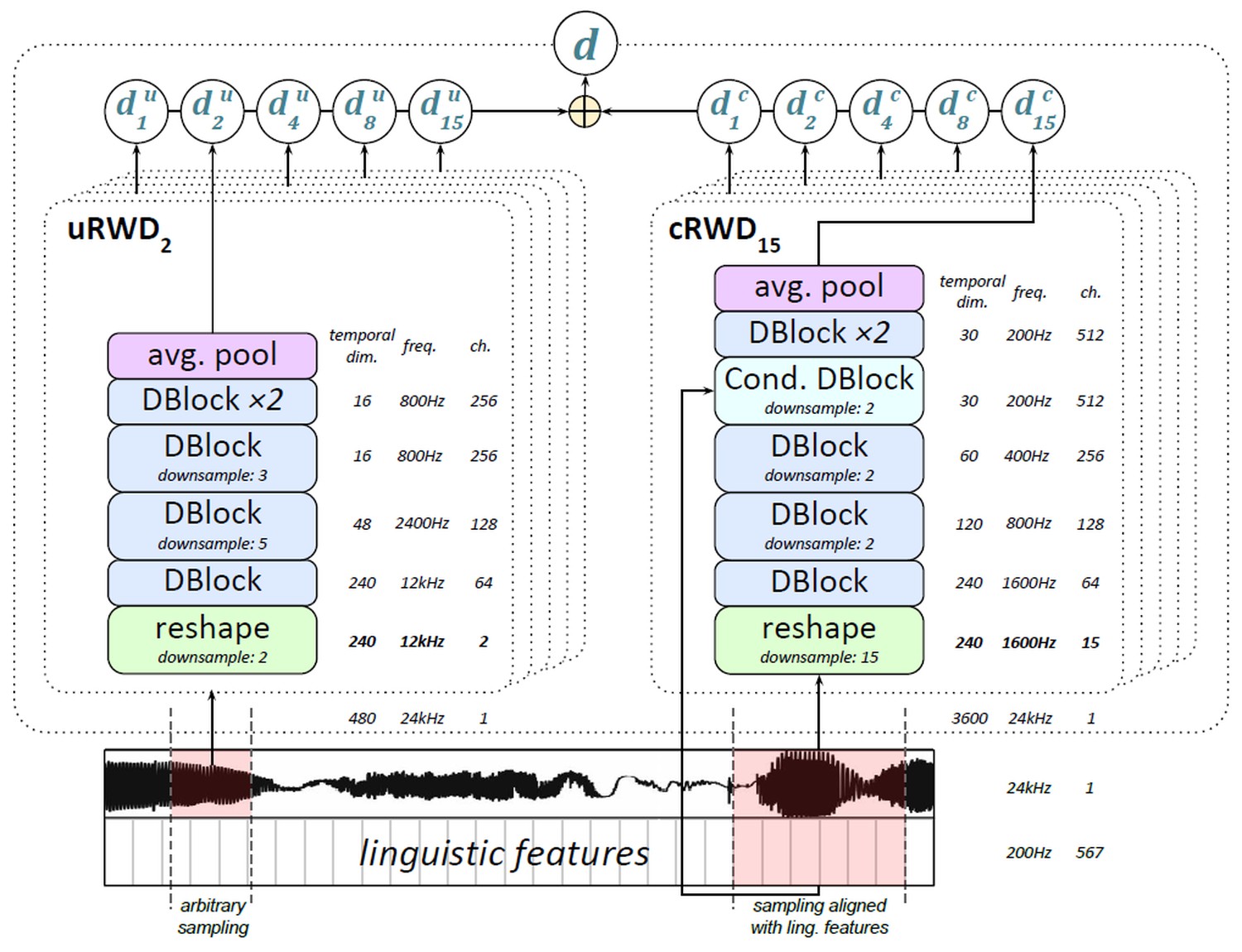
- “Random Window Discriminator” (RWD): Input 으로 들어가는 window 의 위치가 random으로 선택됨.
- 단, sample 되는 부분이 오디오 길이 바깥으로 나가지는 않게 하는 듯함. 예를 들어 길이가 240000인 오디오에서 960개를 추출한다면 [0, 239040) 에서 start index 선택.
- Raw audio 전체 길이를 사용할 수도 있지만, 이렇게 random segment 를 고르는 것이 data augmentation 효과도 있기 때문에 좋다.
- “Random Window Discriminator” (RWD): Input 으로 들어가는 window 의 위치가 random으로 선택됨.
- Output: [B, 1]. 여러 개의 D 들이 낸 score 의 총합. 각각의 D 가 낸 점수는 원래 input의 길이에 비례하지만, 이를 average 하여 하나의 scalar 로 낸다.
- MelGAN 에서는 PatchGAN 의 방식을 따라 score 를 time 방향으로 sum 하기 때문에 총 score 의 크기가 input의 길이에 비례했지만, GAN-TTS 는 그렇지 않다.
- Conditional D 는 unconditional D와 다르게, G의 input 이었던 [Batch, 567, Time]을 함께 사용.
- D가 단순히 audio artifact 를 잡는 것에서 그치지 않고, “이 음성은 이 텍스트를 읽은 것이 맞나”도 판별해줘야 하기 때문.
- Raw audio 와 linguistic feat. 는 time dimension이 맞지 않기 때문에, 몇번의 downsampling 을 거친 뒤 sum.
- “그러면 conditional D만 써도 되지 않나요?” → Conditional D 는 raw audio 에서 항상 24000Hz / 200Hz = 120 의 배수인 인덱스만 sample 가능하기 때문에, 이러한 제한이 없는 unconditional D 의 역할도 중요하다. (section 3.3의 lambda, eq. (1), (2) 참조)
- Multi-scale D 로 서로 다른 scale 의 오디오 특성을 잡아 GAN 학습을 가속.
- Raw audio input 직후에 서로 다른 5가지 kernel=stride 의 average pool layer 를 둔다.
- Kernel size 는 24000Hz / 200Hz = 120 의 약수 5가지 1, 2, 4, 8, 15 를 사용.
- 따라서 D는 총 2*5=10가지. 공평하게 1:1:1:…:1 로 sum. (eq. (3))
- D 를 여러개 두더라도 어차피 inference 때는 G 만 쓰기 때문에 generation 이 느려지지 않는다.
- Dilated conv. 를 쓰되, G 처럼 1-2-4-8 로 dilation 을 키워도 효과가 없어서 1-2-1-2-… 반복.
- Input: [Batch, 1, Time], [Batch, 567, Time]. Sample rate 24kHz 의 raw audio, (Generated & Real) 그에 해당되는 linguistic feat. + pitch info.
Experiments
- Dataset: North American English single speaker, 24kHz, 44 hours of speech + transcription + linguistic features
- Discriminator 에 대한 ablation study를 한 결과: random window 대신 전체 음성을 받는 D를 쓰거나, D를 하나만 쓰거나, conditional D 만 쓰거나, 여러 개의 D를 쓰되 같은 scale 만 사용할 경우 모두 성능 저하로 이어졌다.
- Random window 를 쓰는 것은 data augmentation 측면에서도 좋을 뿐 아니라, input 길이가 작고 고정되어 있기 때문에 학습 속도도 빠르다!
- 연산 수가 줄어드는 것 뿐 아니라, input 크기가 고정될 경우 (PyTorch 기준) torch.backends.cudnn.benchmark = True 로 가속 가능하다.
- Random window 를 쓰는 것은 data augmentation 측면에서도 좋을 뿐 아니라, input 길이가 작고 고정되어 있기 때문에 학습 속도도 빠르다!
- Parallel WaveNet 보다 3배 적은 FLOPs 로 작동하며, MOS는 거의 비슷하다.
- GAN 임에도 불구하고 아주 안정적으로 학습되었다.
- (출처: OpenReview author response) Text 라는 강력한 condition 이 있기 때문에 mode collapse 는 논할 필요가 없다. 또한, model collapse 의 경우 ablation study 중 가장 열악한 성능을 냈던 setting 에서만 나타났다.
Frechet DeepSpeech Distance
ASR 에 사용되는 DeepSpeech2 에 real & generated audio 를 넣어 나온 feature 를 비교하는 방식으로, 자동화된 metric 을 만들 수 있다. (자세한 내용은 생략, Appendix B 참조)
Thoughts
- GAN 은 loss curve 보는 것만으로는 학습이 잘 되고 있는지 판단하기 어려운데, FID 와 유사하게 자동 측정 가능한 metric 을 만들어서 실제로 학습 모니터링에 쓸 수 있다는 점이 인상적.
- 하지만 Table 1 을 보면 MOS 가 3 이상일 경우 MOS 와 proposed metrics 의 상관관계는 많이 떨어지는 것 같다. 자신이 없어서 plot 대신 표로 넣은 것 아닐까?
- Metric 계산 코드를 공개할 계획이라 한다. It’s better than nothing, I guess?
- Multi-scale discriminator 아이디어가 MelGAN 과 아주 유사하다.
- 그 때문인지 OpenReview 에 MelGAN 1저자가 등판해서 인용해달라고 했으나, 이 논문의 제출 시점 이후에 publish 되었기 때문에 “prior work”로 고려하기 어렵다는 입장을 보임.
- 실제 ICLR review guideline 을 보면, 어떤 논문이 “prior work” 가 되기 위한 최소 조건 중 하나는 제출기한 30일 전에 publish 되어있어야 한다는 것이다: https://iclr.cc/Conferences/2019/Reviewer_Guidelines
- Generation, Classification(Discrimination) 모두 multi-scale modelling 이 효과적으로 나타나는 사례가 많이 보이는 것 같다. e.g. SinGAN, MelNet, MelGAN, PGGAN, VQ-VAE-2
- 그 때문인지 OpenReview 에 MelGAN 1저자가 등판해서 인용해달라고 했으나, 이 논문의 제출 시점 이후에 publish 되었기 때문에 “prior work”로 고려하기 어렵다는 입장을 보임.
- Inference speed 를 측정하지 않았다. 왜 어느 reviewer 도 지적하지 않았을까?
- 물론 parallel 하니까 빠르긴 하겠지만, latency (speed) 와 FLOPs 의 차이가 클 수도 있다.
- Quoc Le가 트위터에 EfficientDet 소개할 때에도 누군가가 이 점을 지적하자, 그를 인정하고 latency plot 도 같이 올렸다.
- 나도 linguistic feature extractor 갖고싶다…
- FastSpeech 와 같이 별도의 teacher network 없이도 fully parallel & convolutional generator 를 만들 수 있었던 데에는 이 linguistic feature extractor 의 공헌이 컸는데, 이에 대한 정보가 거의 없어서 아쉽다.
- Rule-based extractor일 경우 speech 의 variability 를 다루기 어려울 것이고, 학습 데이터도 이 extractor 를 만드는 데에 사용된 “표준” 억양을 잘 따라야 하지 않을까 싶다. (Sour grape!)
- 이 논문의 주요 novelty 가 이 extractor 에서 왔고, 그것이 neural approach 가 아니었다는 점을 고려하면 이것이 과연 ICLR 에 Talk 로 선정되는 것이 맞는지 의문.
- 이해 안 된 내용:
- Appendix A.1 에서, generator 에 서로 다른 길이의 audio 가 들어가기 때문에 적절한 masking 이 필요하다고 주장한다. 그런데 generator 와 discriminator 모두 짧은 (2초, max. 3600 sample) 길이의 input 만 들어간다. 정말 padding & masking 이 필요했던게 맞나? 설마 학습 데이터 중 2초보다 짧은 음성이 있었나? (나라면 귀찮아서 버릴듯)