Deep Double Descent: Where Bigger Models and More Data Hurt
작성자 :
Louis Park
Overview
제목: Deep Double Descent: Where Bigger Models and More Data Hurt
저자: Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, Ilya Sutskever
기관: Open AI
블로그: https://openai.com/blog/deep-double-descent/
Introduction
점점 더 크고 복잡한 모델을 사용하면서 모델의 성능은 어떻게 변화할까??
고전(?) 머신러닝을 제대로 공부한 사람은 쉽게 다음과 같은 대답을 할 수 있다.
하지만 최신 딥러닝 연구들을 공부하다 보면 이런 "상식"은 더이상 적용되지 않는 것 같은 느낌이 든다. (특히 자본으로 승부하는 몇몇 GAN이나 NLP연구들...)
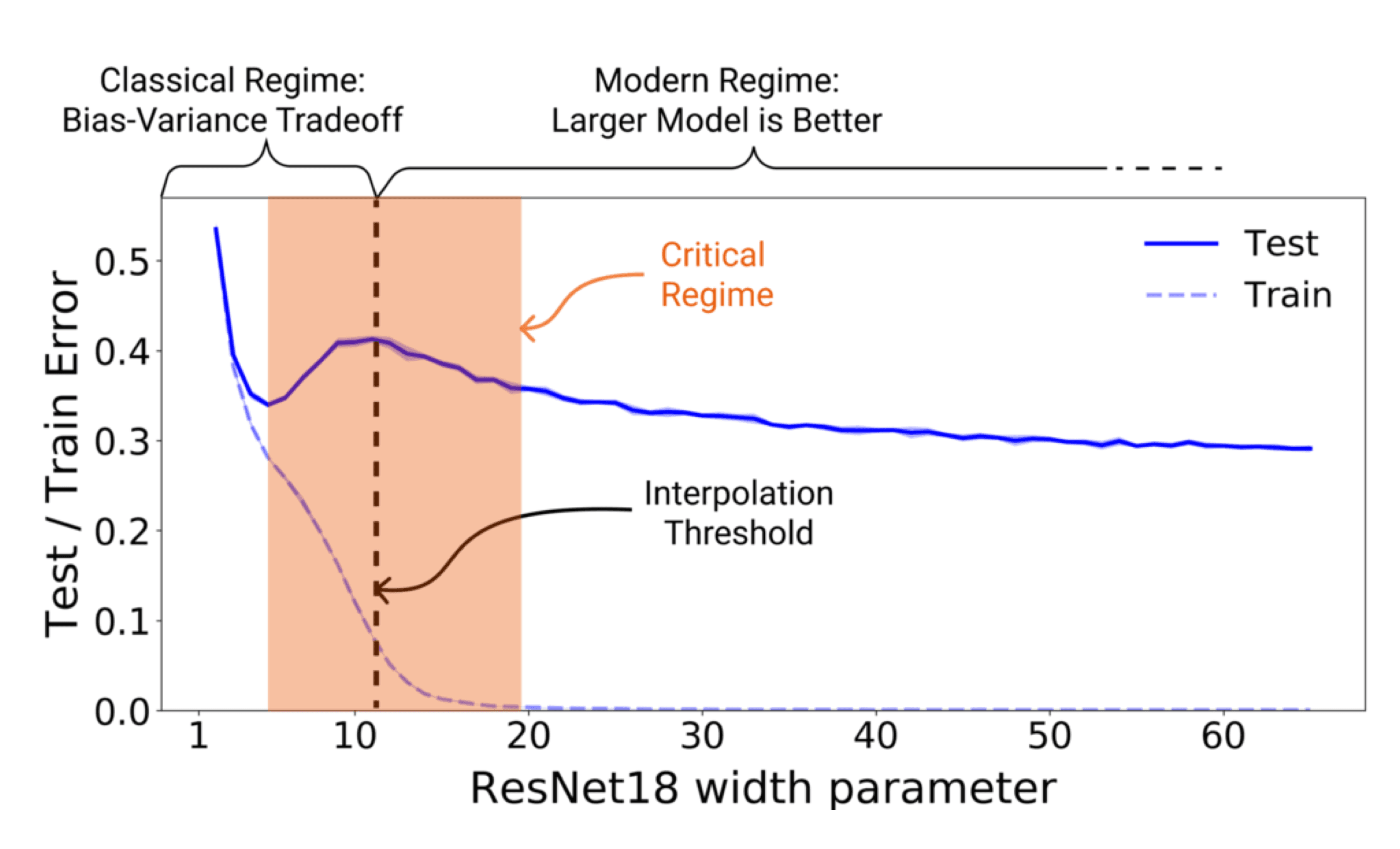
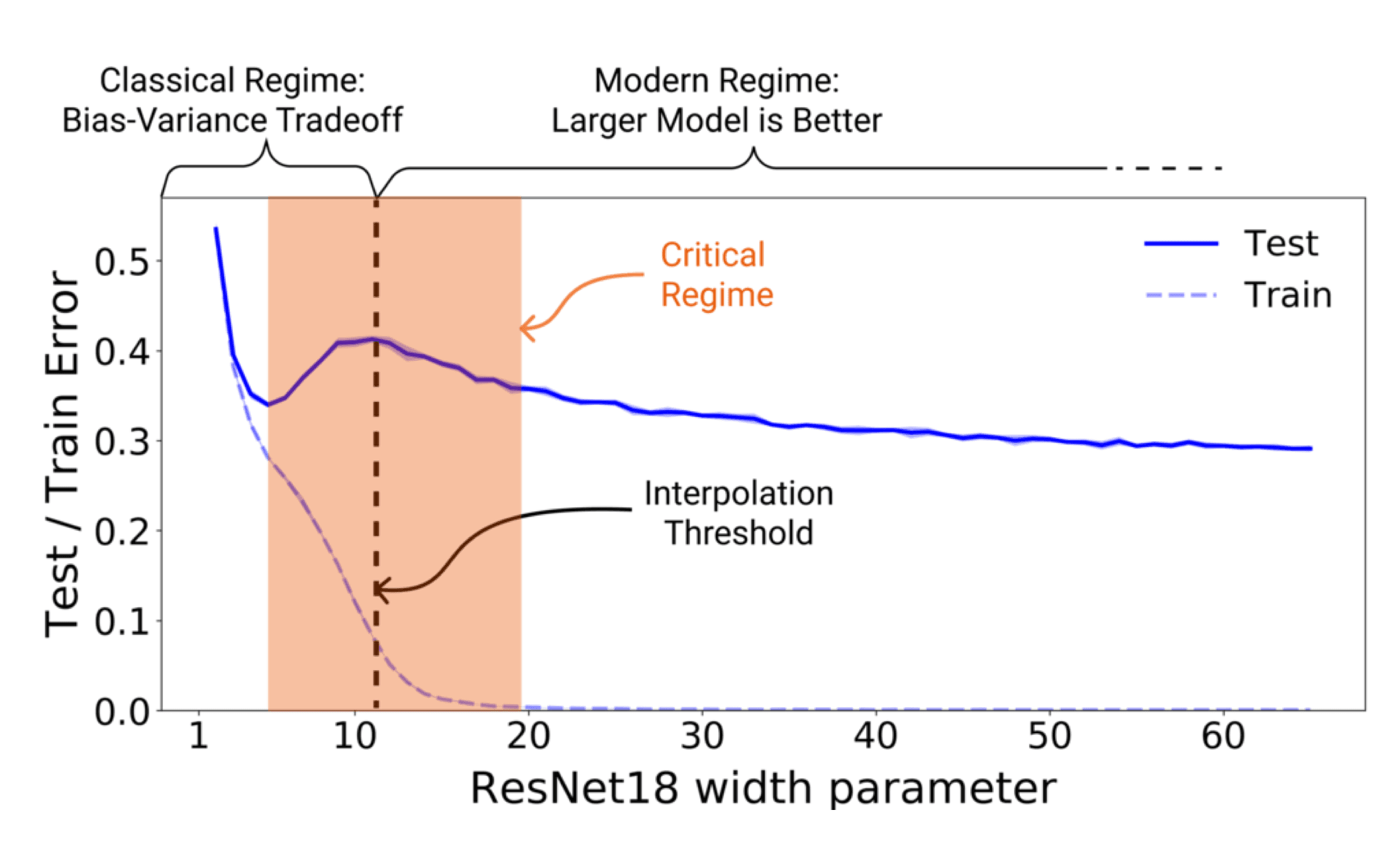
이 논문이 제시하는 가설은, 모델의 크기에 따른 에러의 크기는 단순히 계속 좋아지거나, 계속 나빠지는 것이 아니라 위의 그래프와 같이 double descent의 형태를 띠게 된다는 것, 그리고 이때 트레이닝 과정에 따라 결정되는 모델의 Interpolation Threshold에 따라 critical regime(에러가 peak을 찍는 부분)의 위치를 대략적으로 예측할 수 있다는 것이다. 이런 현상을 좀더 formal하게 표현하기 위해서는 다음의 개념이 필요하다.
Effective Model Complexity
EMC란 Effective Model Complexity로, 다음과 같이 정의된다.

예를 들어 Cifar-10 데이터셋을 가지고 Resnet18 모델을 트레이닝 한다고 생각해 보자. 데이터셋의 분포 D는 cifar 데이터셋의 이미지이고, 여기에서 작은 크기의 subset S만을 샘플링하여 모델을 학습한다. 매우 작은 크기의 S를 (ex: 100장) 가지고 모델을 학습하면 트레이닝 에러는 매우 쉽게 0으로 수렴하지만, 데이터 수가 많아질수록 그렇게 하기는 점점 쉽지 않아진다. EMC란 특정한 방식 Tau(모델구조, optimizer 등등)으로 네트워크를 학습할 때, 트레이닝 에러를 0으로 수렴시킬 수 있는 데이터셋의 최대 크기를 말한다. (epsilon은 에러가 0으로 수렴했는지를 판단하는 parameter 인데 크게 중요하지는 않을 듯함)
EMC는 트레이닝 프로세스(Tau)에 따라 결정되는 값인데, 이 트레이닝 프로세스라는게 상당히 광범위한 조건들을 포함하는 내용이다. 모델구조, 파라미터 수, 학습 에폭 수, optimizer, 라벨 노이즈 등등...
이 EMC를 이용하면 처음 이야기했던 논문의 주장을 다음과 같이 표현할 수 있다.
Generalized Double Descent Hypothesis

즉, 모델을 학습하는 특정 트레이닝 프로세스 Tau에 대해, 더 많은 데이터를 fitting할 수 있도록 학습 프로세스를 변화시키면, EMC와 데이터셋의 크기 n에 따라 다음과 같은 변화가 일어난다.
EMC << n 인 경우 성능이 좋아진다
EMC >> n 인 경우에도 성능이 좋아진다
EMC가 n 근처인 경우에는 성능이 나빠질 수 있다
"any perturbation of Tau that increases its effective complexity"라는 표현이 이 statement를 매우 강력하게 만들어 주는데, 위에서 언급한 Tau에 영향을 미치는 온갖 것들이 여기에 해당한다. 모델의 크기를 키운다거나, 더 효율적인 구조를 쓴다거나, 학습을 오래 돌린다거나, 더 좋은 옵티마이저, 더 깨끗한 데이터를 사용하는 등등의 방향으로 Tau를 변화시키면 아마도 모델이 fitting하는 데이터의 수가 증가할 것 같은 느낌이므로 이러한 것들이 여기서 말하는 perturbation에 해당할 것이다.
Experiments
본 논문의 주된 내용은 이렇게 모델의 EMC에 영향을 미치는 조건들을 다음의 세가지로 분류하고 각각의 조건(또는 그것들의 조합)에 대해 더블디센트 곡선이 어떻게 변화하는지 관찰하고 거기에 대해 분석하는 것이다.
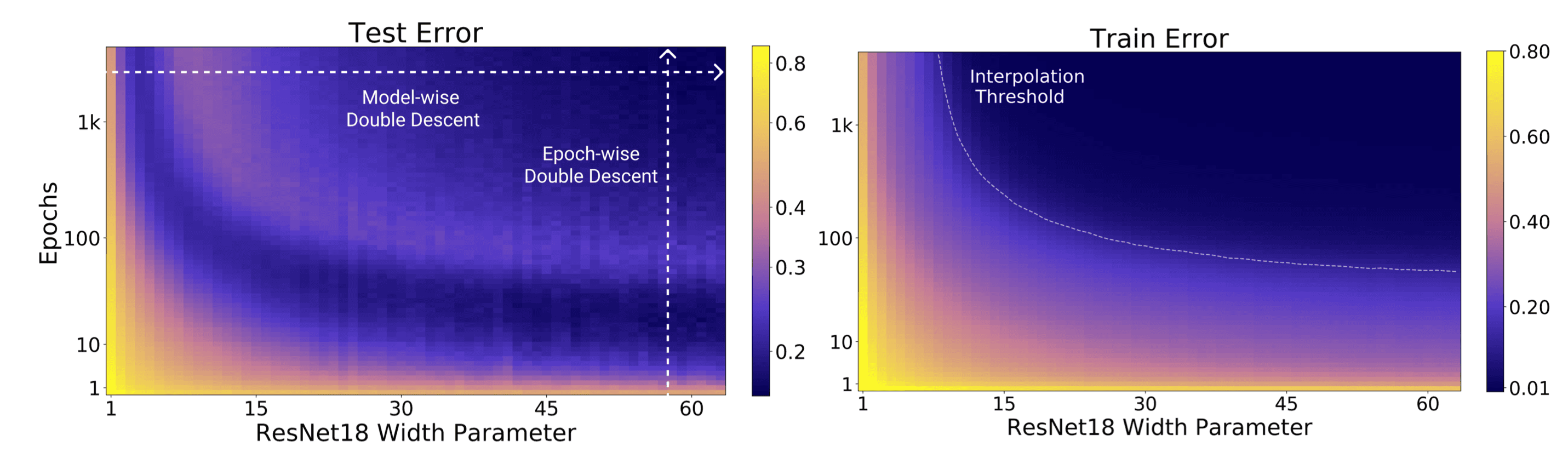
Model-wise DD: 모델의 파라미터 수
Epoch-wise DD: 트레이닝 epoch수
Sample-wise DD: 트레이닝셋의 크기, 라벨 노이즈를 조절
본 요약에서는 이러한 실험들 중 인상깊었던 몇몇 실험 내용에 대해서만 이야기할 예정이다.
Early Stopping
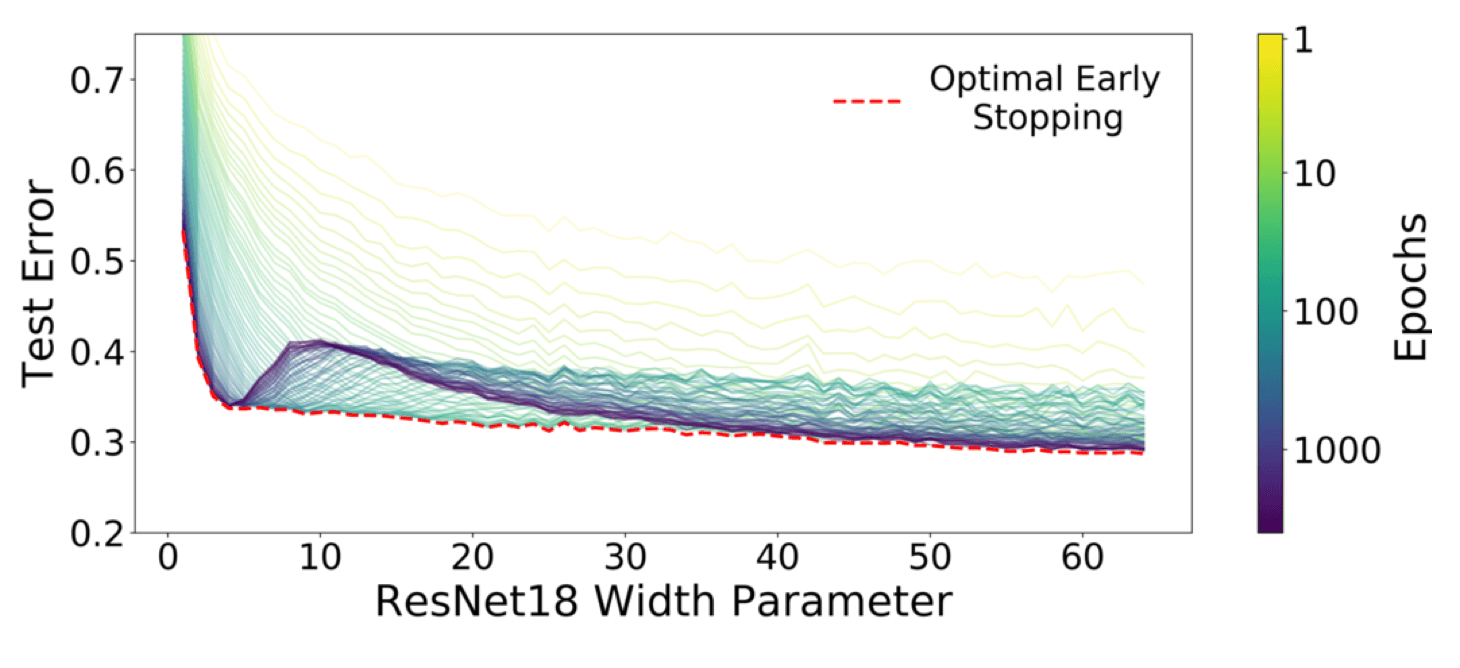
처음 배울때는 매우 중요할것 같았지만 사실 생각보다 많이 쓰지는 않는, early stopping. 위 그래프는 모델의 크기가 어느정도 이상일때 early stopping을 하는게 별로 의미가 없을 수 있다는 것을 보여준다.
Where More Data can Hurt Performance
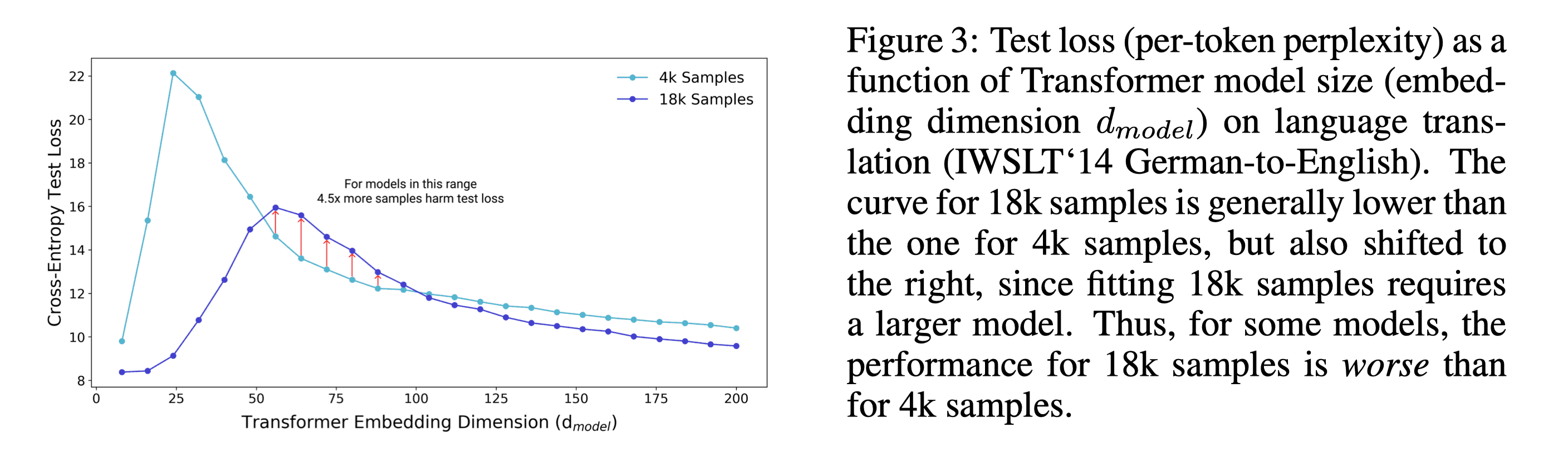
일반적으로 다른 것들은 적정 수준을 찾는게 중요하지만 데이터의 양, 다양성만은 다다익선이라는 것이 알려져있다. 이 논문의 실험결과에 따르면, 특정 조건에서는 데이터를 몇배 더 많이 사용한 모델이 오히려 더 성능이 떨어질 수도 있는 것으로 나타났다.
결론
이런 현상(더블 디센트)이 왜 일어나는지에 대해서는, 5장 model-wise DD의 Discussion부분에서 간단한 설명을 찾을 수 있었다. "Interpolation Threshold에서는 가능한 fitting의 개수가 한가지 뿐이기 때문에 작은 perturbation으로도 모델이 쉽게 망가지는게 아닐까...?"하는 내용.
딥러닝 모델을 학습시키면서 어느 정도 크기의 모델을 사용해야할지, 몇 epoch까지 학습을 돌려야할지 등등은 그냥 직감에 의존하는 경우가 많은데, 각각의 설정에 따라 모델의 성능이 어떻게 변화하는지에 대해 대충이라도 감을 잡는데 도움이 되는 내용인 것 같다. 처음에 훑어보면서 "모델의 복잡도에 따른 성능이 더블 디센트 곡선을 그린다"까지가 내용의 전부인 줄 알았지만, 실험 하나하나의 결과가 상당히 괜찮아서 나중에 모델 트레이닝하면서 여러번 다시 참고하게 될것 같은 논문이다.
#Deepest #DPR2020