High Fidelity Speech Synthesis with Adversarial Network

작성자 :
박승원
Overview
제목: High Fidelity Speech Synthesis with Adversarial Network
저자: Mikolaj Binkowski et al. (Imperial College of London + Deepmind)
학회: ICLR 2020 Accept (Talk)
코드: (third-party) https://github.com/yanggeng1995/GAN-TTS (중국어?)
Introduction
Background
Neural TTS 는 text 를 받아 mel-spectrogram 과 같은 intermediate representation 을 예측하는 acoustic model 과, 그를 청취 가능한 raw audio 로 변환해주는 vocoder 로 나뉜다.
Neural acoustic model의 예시: Tacotron, Transformer-TTS, MelNet
Neural vocoder의 예시: WaveNet, WaveRNN, WaveGlow, MelGAN
보통 TTS 성능 평가는 사람이 직접 들어보며 자연스러움을 평가하는 MOS(Mean Opinion Score) 를 사용한다.
2. Contribution
이 논문에서는 linguistic feature extractor 의 힘을 빌려, text로부터 raw audio를 한번에 만들어내는 generator 를 GAN 으로 학습시킨다. 또한, MOS 대신 사용될 수 있는 metric 을 4가지 제시한다.
GAN-TTS
Note: 1번째 깊이의 bullet 까지만 읽어도 큰 그림을 이해하는 데에 문제가 없습니다. 구현에 필요한 detail 까지 알고 싶으시다면 전체를 읽으세요.
Generator (이하 "G")
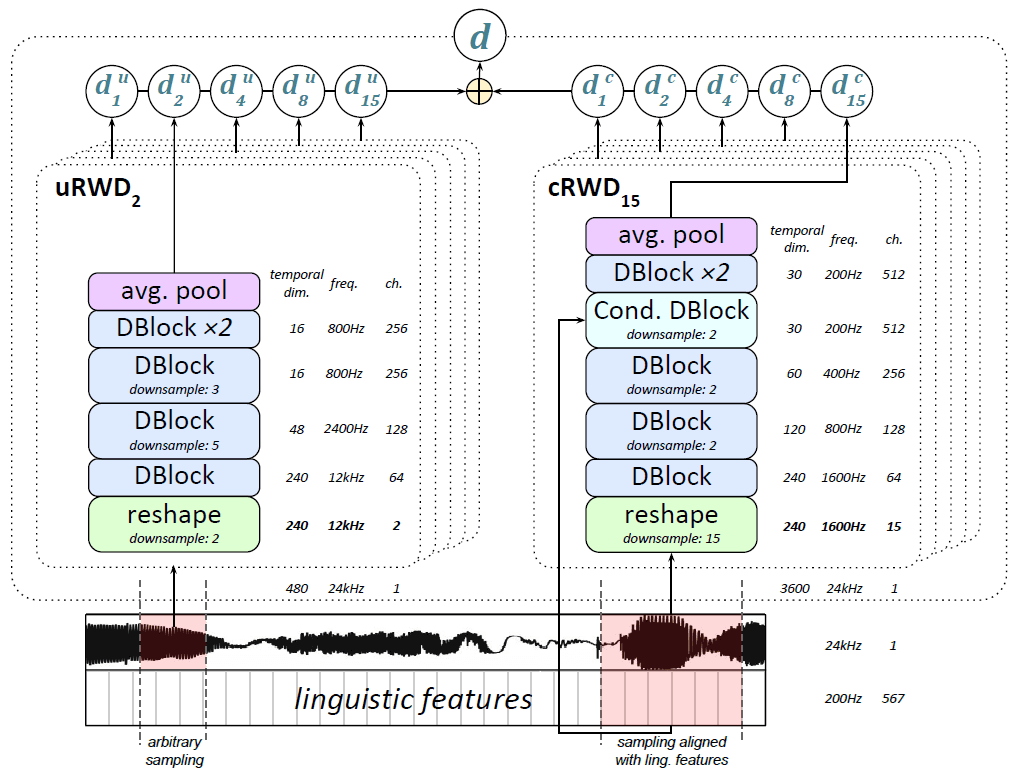
Discriminator (이하 "D")
Experiments
Dataset: North American English single speaker, 24kHz, 44 hours of speech + transcription + linguistic features
Discriminator 에 대한 ablation study를 한 결과: random window 대신 전체 음성을 받는 D를 쓰거나, D를 하나만 쓰거나, conditional D 만 쓰거나, 여러 개의 D를 쓰되 같은 scale 만 사용할 경우 모두 성능 저하로 이어졌다.
Parallel WaveNet 보다 3배 적은 FLOPs 로 작동하며, MOS는 거의 비슷하다.
GAN 임에도 불구하고 아주 안정적으로 학습되었다.
Frechet DeepSpeech Distance
ASR 에 사용되는 DeepSpeech2 에 real & generated audio 를 넣어 나온 feature 를 비교하는 방식으로, 자동화된 metric 을 만들 수 있다. (자세한 내용은 생략, Appendix B 참조)
Thoughts
GAN 은 loss curve 보는 것만으로는 학습이 잘 되고 있는지 판단하기 어려운데, FID 와 유사하게 자동 측정 가능한 metric 을 만들어서 실제로 학습 모니터링에 쓸 수 있다는 점이 인상적.
Multi-scale discriminator 아이디어가 MelGAN 과 아주 유사하다.
Inference speed 를 측정하지 않았다. 왜 어느 reviewer 도 지적하지 않았을까?
나도 linguistic feature extractor 갖고싶다...
이해 안 된 내용: