On the "steerability" of GANs
작성자 :
최주영
Overview
제목: On the "steerability" of generative adversarial networks
저자: Ali Jahanian, Lucy Chai, Phillip Isola
학회: ICLR 8/8/8
요약:
GAN의 latent space에서 "linear walk"을 수행하여 생성 이미지의 zoom, shift, rotate, color transform 등을 하는 방식을 제안.
Self-supervised manner로 학습
"Steerability"를 강화하기 위해 data augmentation과 jointly training walk trajectory and generator weights를 제안
BigGAN, StyleGAN, DCGAN에서 실험

Method
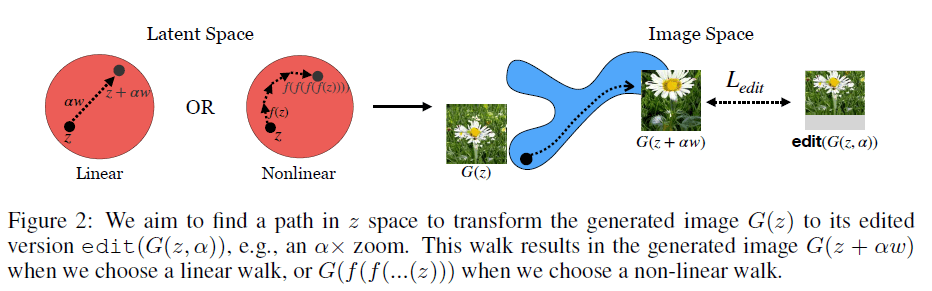
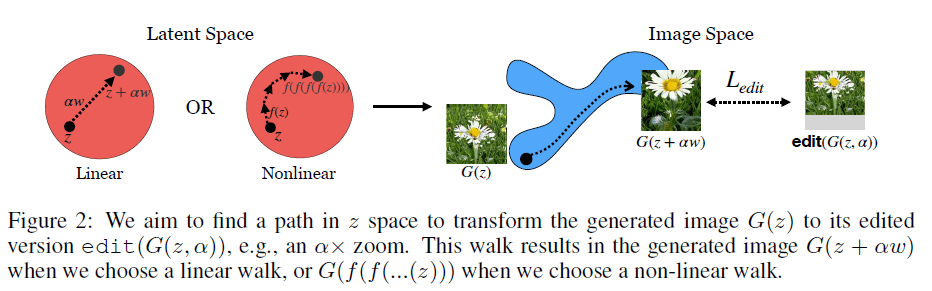
아래 그림처럼 latent space에서의 이동이 생성 이미지의 transformation으로 이어지게 하는게 목표.
"Equivariance"와 비슷한 개념이다. 논문에서는 전반적으로 latent space에서 linear walking을 다루지만, nonlinear walking 방식도 제시한다.
예를 들어 아래 그림의 edit함수가 zoom이라고 하자. 논문에서 제안한 학습과정을 통해서 zoom을 담당하는 vector w를 찾을 수 있고, latent vector z에서 w의 방향으로 alpha step만큼 가서 generator로 이미지를 생성하면 (G(z+aw)) 원하던 zoom된 이미지를 얻을 수 있다. Nonlinear walk의 경우에는 aw만큼 이동하는게 아니라 f라는 함수를 n번 씌워준다.
Linear walk w는 아래 objective로 학습하여 얻을 수 있다. 단, generator는 이미 학습되어 있고 fix됨. Loss는 L2 loss 혹은 LPIPS perceptual similarity를 사용한다.
별도의 label없이, 주어진 이미지를 edit하여 objective function에서 target으로 삼기 때문에 self-supervised learning이라고 할 수 있다.
Non linear walk function f는 아래 objective로 학습하여 얻는다.
뒤 실험에서 보이지만, 이렇게 pre-train된 generator로 walk w를 찾아서 transformation을 하면 transformation의 limit이 있다. 그리고 dataset의 bias에 따라서도 transformation의 limit이 존재한다. 그래서 data augmentation을 하고 generator weights와 linear walk w를 jointly training 하는게 낫다고 제시한다. 아래 objective function로 학습한다.
Experiments
Transformation limit을 알아보기 위해 data augmentation, jointly training 없이 linear walk w를 찾아서 image transformation을 살펴본다. 아래 figure들은 전부 BigGAN으로 실험한 결과들이다.

위 figure에서의 숫자들은 표시된 이미지들 사이의 LPIPS distance를 의미한다. 가운데 이미지를 기점으로 step size a를 늘이고 줄여보면서 image transformation을 관찰한건데, 가운데 이미지에서 멀어질수록 realism이 떨어지며 이미지 간의 LPIPS distance가 작아짐을 볼 수 있다. 이것은 transform 할 수 있는 정도가 limit이 있으며 step size를 키우거나 줄일수록 image 가 converge함을 의미한다.

위 figure 첫번째 row는 해파리와 새를 red로 color transform 한 결과이다. 해파리는 빨간색으로 잘 바뀌는 반면 새는 계속 노란색이다. 세번째 row에서는 파란색으로 color transform하는데, 스포츠카는 잘 바뀌는 반면 소방차는 계속 빨간색이다. 이는 dataset bias가 있기 때문이다. Dataset에서 goldfinch라는 새는 노란색밖에 없고, 소방차는 빨간색밖에 없다. 반면 해파리는 파란색과 빨간색 해파리가 모두 있으며 스포츠카도 빨간색과 파란색 스포츠카가 모두 있기때문에 color transformation이 가능했던 것이다.

위 figure에서도 마찬가지로 dataset bias를 반영한다. 새 이미지는 대부분 centered 되어있는 반면 노트북은 다양한 scale의 이미지가 존재하기 때문에 새는 zoom이 잘 안되고 노트북은 zoom이 잘 된다.
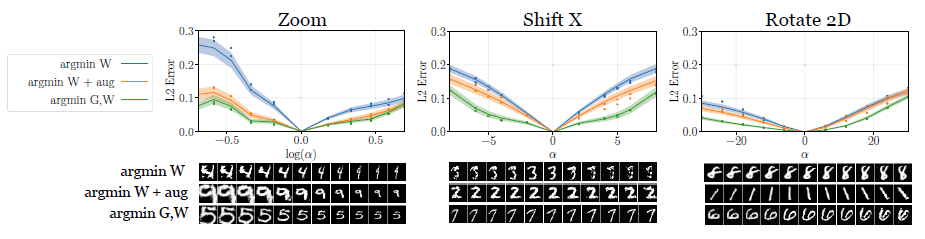
위에서 발견한 transformation limit문제를 해결하기 위해 data augmentation과 jointly training을 제시했다. L2 loss 비교로 그 효과를 보여준다. 아래 figure에서 argmin W는 pre-train된 generator로 W를 찾는 방식, argmin W + aug는 data augmentation을 했을 때, argmin G,W는 data augmentation과 jointly training을 할때이다.
논문 Appendix에 수많은 qualitative example들이 있다. 그 중 zoom, shift X, shift Y를 다같이 하는 예시 하나만 가져와봤다. transformation 정도가 커질수록 물체가 이상해지긴 하지만, transformation에 따라 기존 이미지에 없던 잔디, 하늘, 물 등이 등장하는게 신기하다.

Thoughts
Transformation의 정도가 커질수록 이미지가 망가지긴 하지만, 어느정도 transformation이 잘된다고 생각
Image2StyleGAN에서도 그랬고, 요즘 latent space에서의 조작을 통해 생성 이미지를 조작하는 시도들이 많은 것 같다
Zoom, shift, color transform 같은 transformation 하나하나 label을 지정하지 않고 self-supervised manner로 학습하는 방식도 인상적.
결국 dataset bias가 걸림돌인 듯 하다. Latent space에서 linear walking을 통해 dataset bias를 분석 해볼 수 있을 것 같다