[Paper Review] Are Deep Policy Gradient Algorithms Truly Policy Gradient Algorithms?
작성자 :
박관영
요약:
평균적으로 좋은 성능 및 간단한 구현으로 인해 널리 사용되는 policy optimization 기법인 PPO, 그리고 구현은 어렵지만 안정적인 성능을 보여주는 TRPO를 심층적으로 분석한다.
이러한 policy optimization algorithm들은 Real-world 세팅에서 알고리즘의 수학적 예측과 크게 다르게(심지어 상반되게도) 움직인다.
저자들은 이러한 사실이 RL 논문들의 낮은 reproducibility의 중요한 원인 중 하나임을 지적한다.
Motivation
To what degree does the current practice of deep RL reflect the principles that informed its development?
RL 페이퍼를 읽고 이를 구현하고자 했던 사람들은 RL이 hyperparamter에 굉장히 민감하다는 사실을 알고 있을 것이다. 특히 PPO의 경우에는 알고리즘이 단순하여 구현해 놓은 github 코드들이 많은데, 알고리즘은 맞게 구현했음에도 불구하고 결과가 잘 나오지 않는 경우가 많다. 하지만 논문을 보면 대부분 수학적으로 policy improvement가 보장되며, 이 과정에서 나오는 수식들을 통해 알고리즘의 성능 개선을 설명한다. 저자들은 이러한 이론적 설명에 대하여 의문을 던지며, “과연 RL 알고리즘의 performance는 얼마나 알고리즘의 이론적 기반을 반영하는가?” 라는 현실적인 질문에 답하고자 한다.
Understanding Performance of PPO & TRPO
저자들은 이 논문에서 PPO와 TRPO의 성능이 알고리즘의 수학적 기반을 얼마나 반영하는지를 확인하기 위해 3개의 기준을 제시한다.
Gradient Estimation : Sampled gradient가 얼마나 true gradient를 잘 근사하는가?
Value Prediction : Value function V(s)를 얼마나 잘 학습하는가?
Optimization landscape : Policy optimization에 사용되는 loss function이 얼마나 true reward function을 잘 나타내는가?
이 3가지 기준들은 PPO와 TRPO의 수학적 fundamental이 얼마나 잘 지켜지고 있는지를 나타낸다. 만약 PPO 알고리즘이 잘 작동하는 이유가 정말로 ‘알고리즘의 이론적인 부분이 실제로도 잘 적용되어서’ 라면, 이 3가지 조건을 모두 만족해야 한다.
Experiments
저자들은 위 3가지 기준을 Policy optimization 알고리즘들이 만족하는지를 테스트하기 위해 TRPO, PPO 2가지의 알고리즘으로 실험을 진행하였다.
Gradient Estimation Quality
Policy gradient method들의 핵심은 Policy gradient theorem을 이용하여 충분히 많은 샘플이 있다는 가정 하에 true gradient를 sampled gradient 식으로 바꿔치기 할 수 있다는 것이다. 저자들은 이 ‘충분히 많은 샘플’의 개수가 어느정도인지 대략적으로 세어 보기로 하였다.
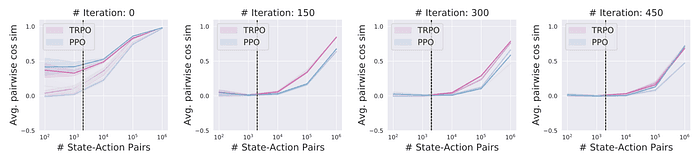
Figure 1. Sample 개수에 따른 sampled gradient의 pairwise cosine similiarity. 이 값이 0이면 variance가 최대, 1이면 variance가 0이다. 보통 사용되는 2k개의 샘플로는 Sampled gradient의 consistency를 보장할 수 없음을 알 수 있다.
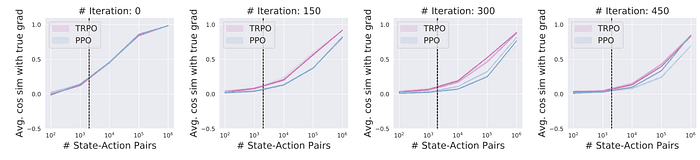
Figure 2. Sample 개수에 따른 sampled gradient와 true gradient 사이의 평균 cosine similarity. PPO에서 어느 정도 유의미한 similarity(cos similarity>0.5, 사이각 60도 이하)를 보이려면 적어도 ¹⁰⁵개 정도의 샘플은 필요하다는 것을 알 수 있다.
Fig. 1, 2에서 볼 수 있듯이, 일반적으로 True gradient estimation에 사용되는 2k개의 샘플로는 True gradient를 거의 반영할 수 없었다. (cosine distance가 0.2라는 것은 평균적으로 True gradient와의 각도가 평균 80도 정도라는 것이다 — Random gradient와 Avg. cos distance가 0인 것을 생각해 보면 얼마나 gradient estimation이 부정확한지를 알 수 있을 것이다.)
Value Prediction
많은 Policy gradient method들은 Q(s,a) 대신 Variance를 낮추어 줄 수 있는 Advantage function을 사용한다. 그리고 이를 Value function V(s)만으로 근사할 수 있게 해주는 GAE(General Advantage Estimator)의 등장 이후로 V(s)의 역할은 더욱더 중요해졌다. 과연 이 V(s)는 제대로 학습이 되고 있는가? 더 나아가 Advantage function은 얼마나 Variance를 낮추어주는가?
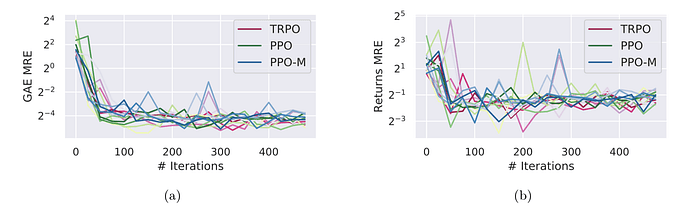
Figure 3. Iteration에 따른 (biased) GAE(a), (unbiased) Return(b) loss. 그림을 보면 어느 쪽으로 보아도 잘 학습하는 것으로 보인다.
Fig. 3에서 볼 수 있듯이, Value function의 학습은 상당히 안정적이다. Policy의 stochasticity와 environment의 불확실성을 고려해보면 적어도 Value function은 True value function를 어느 정도 근사할 수 있음을 알 수 있다.
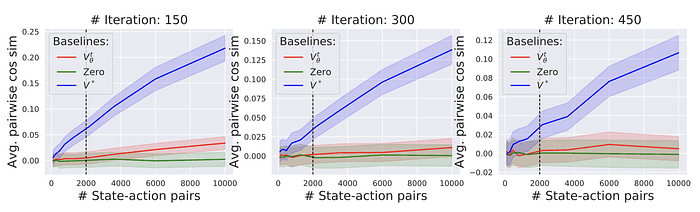
Figure 4. Sample 개수에 따른 sampled gradient의 pairwise cosine similiarity(높을수록 variance가 적다). 파랑, 초록, 빨강은 각각 True Value function, 0(영함수), 우리가 사용하는 Value estimation function이다. 그림에서 볼 수 있듯이 Variance를 어느 정도 줄여주고 있다.
Fig. 4에서 볼 수 있듯이, True value function과는 많은 gap이 있지만 그래도 어느정도 variance를 줄여주고 있다. Value function의 계산이 어렵지 않은 점을 감안하면, variance reduction을 공짜로 얻을 수 있는 Value prediction을 안 쓸 이유는 없어 보인다 (실제로 돌려보면 Value prediction의 유무는 최종 algorithm의 performance에 엄청난 영향을 미친다). 다만 이론적으로 기대되는 (True value function) variance reduction에는 훨씬 미치지 못한다.
Optimization Landscape
Supervised Learning과는 다르게, Policy gradient method에서 policy loss function의 값은 실제 cumulative reward값은 아니지만 gradient가 같은 방향으로 되는 proxy function의 역할을 수행한다. 다시 말해, 이론적으로는 policy loss function을 maximize 시키면 reward도 maximize되어야 한다.
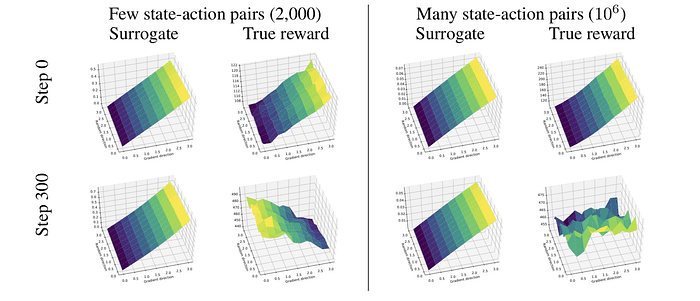
Fig 5. Sample 개수에 따른 Optimization landscape과 true reward landscape의 비교. Step 0에는 두 landscape이 비슷한 경향성을 보인다. 하지만, 학습이 진행되면서 Step 300에는 2k개의 state-action pair로는 Surrogate function이 reward function의 proxy가 되지 못한다는 것을 보여준다.
하지만, Fig. 5에서 볼 수 있듯이 학습이 진행되면서 학습에 사용되는 surrogate loss function와 True reward 사이의 간극은 경향성이 바뀔 정도로 커진다. 학습이 진행되기 전에는 loss function이 reward landscape을 잘 반영하지만, 학습이 진행되면서 보통 사용되는 2k정도의 sample로는 아예 경향성이 바뀐다는 것을 보여준다. 이는 에이전트를 학습시킬 때 중간에 학습이 이상하게 삑나는(?) 상황을 설명해준다.
Conclusion
저자들은 Real-world에서 Policy Optimization 알고리즘들이 얼마나 그 이론적 기반을 반영하고 있는지를 확인하고자 하였다. 이를 위해서 Gradient Estimation, Value Prediction, Optimization Landscape 3가지에 대하여 실험을 진행하였다. 실험 결과 및 분석을 요약하면:
Gradient estimation: True gradient와 큰 차이를 보인다. 더 좋은 estimation을 할 수 있다면 learning rate도 늘리고 학습 속도도 더 빨라질 것이다.
Value prediction: Variance를 줄여주고 있지만, 이론적으로 기대되는 값보다 그 효과가 훨씬 적다
Optimization landscape: True reward landscape와 큰 차이를 보인다 (심지어 반대로 움직일 수도 있다…)
저자들은 reliable한 강화학습 알고리즘을 만들기 위해서는 그 이론적 기반이 Real-world에서 얼마나 반영되는지에 대한 이해가 필수적임을 주장한다.