[Paper Review] Non-Attentive Tacotron

작성자 :
양진혁
요약:
Neural TTS의 attention mechanism은 제품에 사용하기엔 근본적으로 해결이 어려운 문제를 갖고 있음.
Tacotron 2의 attention mechanism을 explicit duration predictor로 대체하고, autoregressive decoder는 유지함.
Gaussian upsampling 제안
duration predictor의 unsupervised, semi-supervised 학습
robustness를 상당히 개선
MOS: Tacotron 2 (4.35), proposed (4.41), Ground truth(4.42)
Introduction
Autoregressive neural TTS 모델들은 녹음본만큼 자연스러운 음성을 생성하고 있다. 하지만 autoregressive network의 한계(중간 step에서의 잘못된 추정, early cut-off)나, attention mechanism의 한계(반복, 스킵 등)가 여전히 존재한다. 이러한 문제들이 많이 안화되었으나 근본적으로 해결된 것이 아니며, 상용화된 제품에서는 매우 적게 발생하더라도 사용자 경험에 치명적이다.
최근에는 non-autoregressive TTS 모델들이 많이 사용되고 있다. 이 방식은 explicit duration을 사용함으로써 attention이 겪는 문제를 해소했다. 하지만 autoregressive decoder는 TTS가 one-to-many problem(같은 text에 매우 다양한 음성)이라는 면에서 여전히 이점을 갖고 있다. Non-attentive Tacotron은 Tacotron2의 autoregressive decoder와 duration predictor를 결합한 방법이다.
논문의 key contributions
Tacotron 2와 duration predictor
Gaussian upsampling
Global and fine-grained control of duration at inference time
Semi-supervised and unsupervised duration modeling
Reliable evaluation metrics
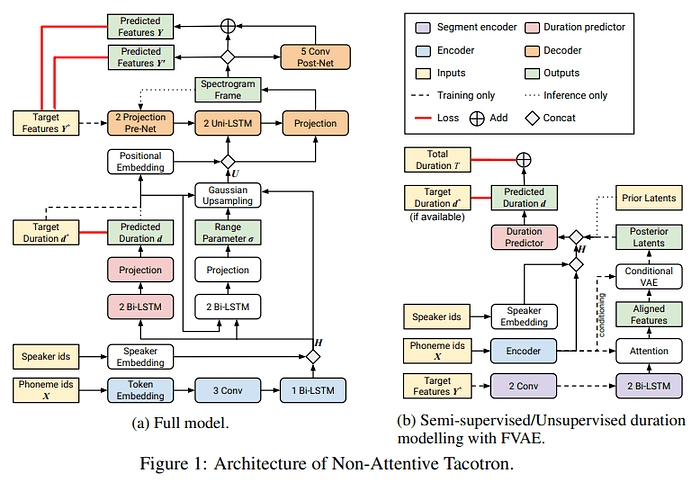
Methods
neural TTS는 feature generation network(e.g. text-to-mel) + vocoder network (e.g. mel-to-wav) 두 개의 network로 구성된다.
FastSpeech는 non-autoregressive TTS model로써 encoder output에 대한 duration만큼 repeat하는 방식을 사용했다. 저자는 repeat 방식이 아닌 Gaussian upsampling을 적용하였음.

FastSpeech의 repetition upsampling 방식
Gaussian Upsampling
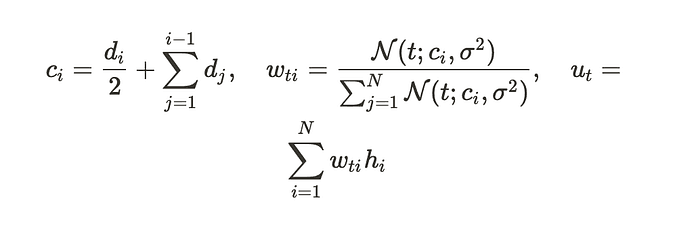
uₜ : upsample vector, hᵢ: encoder output
특정 token의 decoder time(t) 에서의 중심 위치©를 계산하여 mean으로 사용하고, σ는 duration과 h를 input으로 하는 network를 거쳐 학습한다.
upsampling 과정에서 repetition이 아니라 duration 값이 spectrogram 추정 과정에 포함됨으로써 fully differentiable 되었다는 강점이 생김. 이는 semi-supervised, unsupervised duration modeling을 가능하게 함.
Semi-supervised and Unsupervised Duration Modeling
spectrogram length와 일치시키기 위해 예측된 duration의 합을 T로 나눈 값으로 scale 하여 upsampling에 사용한다.
⠀⠀⠀• scale_factor=T / Σᵢdᵢ
⠀⠀⠀• d를 직접적으로 이용하여(should be integer) encoder output을 repeat 하는 방식이 아니라 Gaussian upsampling 방식이기 때문에 가능하다.
duration 추정을 효과적으로 하기 위해 학습에만 사용되는 FVAE(Figure1.b) 를 도입
Results
Settings
학습 데이터셋은 66명 화자, 4 accents, 화자 별로 5초부터 47시간까지 다양함. 총 354시간.
평가 화자 데이터셋은 남/여(5명:5명) 화자 별로 4시간 이상(Table 1) 혹은 약 4시간 정도(Table 4)
semi-supervised 는 평가 화자 데이터셋에 대해서만 duration label 사용하지 않음.
unsupervised 는 duration label을 전혀 사용하지 않음.
Analysis

제안 방법이 Tacotron2의 성능과 거의 유사함.

σ를 학습하지 않고 고정된 값(10.0)으로 했을 때(E2E adv. TTS 방법)보다 약간 좋은 성능을 보임.
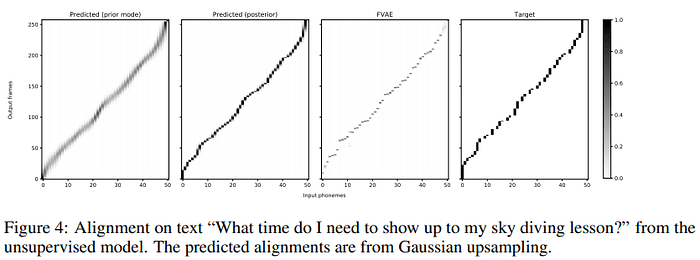
FVAE가 학습한 alignment가 target과 비슷하게 잘 잡히는 것을 볼 수 있음.
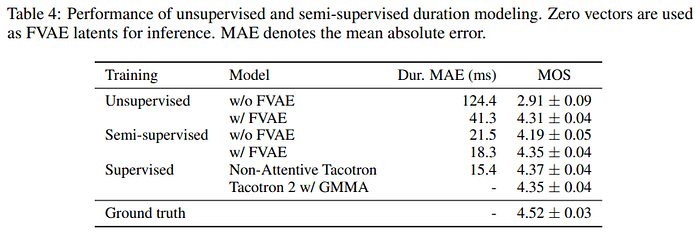
FVAE를 사용할 경우 duration label이 없어도 자연스러운 성능을 보임.
semi-supervised(평가 화자만 duration label이 없음)는 FVAE를 사용하지 않아도 높은 성능을 보이며, FVAE를 사용하면 supervised와 유사한 성능을 보임.
하지만 세밀히 조사해 본 테스트에서는 supervised가 아닌 경우 불명확한 발음, 음소 반복 등의 에러가 발생하는 것을 발견함(Tacotron 2 보다는 나음)
pace control에서도 supervised에 비해 alignment가 부정확한 모습을 보임.
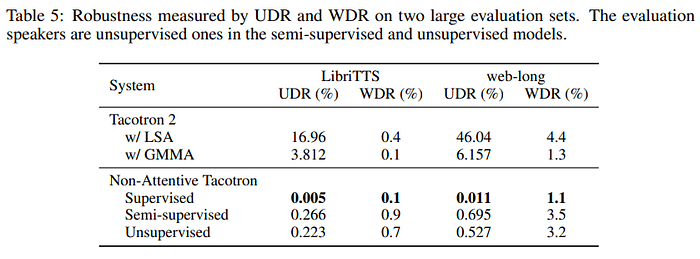
Robustness와 관련하여 UDR(Unaligned Duration Ratio)에서는 상당히 좋은 성능을 보인다. 이 measure는 Tacotron 2과 Non-attentive tacotron 방식을 구분하여 보는 것이 좋을 듯 하다.
WDR(ASR Word Deletion Error)에서 개선이 있었는데, Introduction에서도 언급했다시피 상용 제품에서는 약간의 robustness 개선도 중요하며, Supervised가 GMMA보다 꽤 좋아졌다.
median text length는 LibriTTS(74), web-long(224), Tacotron 2는 특히 long sentence에 약한 모습을 보임.
⠀**실험적으로 Tacotron 2는 위 성능 정도의 레벨을 달성하기 위해 상당히 예민한 data preprocessing이 필요했음.
Discussion
external alignment와 관련하여 구글은 자체적으로 증명된 좋은 인식 모델을 가지고 있음. speaker-dependent로 추정됨.
supervised + FVAE 는 supervised가 강력하여 큰 개선이 없었는가 의문
alignment tool이 매우 좋다면 필요 없을 수도 있지만, 그렇지 않을 경우(autoregressive TTS attention에서 가져왔을 경우)에는 같이 쓰는 것이 좋아질 수 있을 것 같다.
semi-supervised, unsupervised를 효과적으로 하는 방법이 제안되어 추후에 데이터가 적은 화자의 추가, unseen speaker or style로 확장한 모델 등에 도움이 될 것으로 보임.
non-autoregressive decoder를 사용하는 경우의 분석은 추가로 필요해 보임.