PointRend: Image Segmentation as Rendering

작성자 :
최주영
Point Selection for Inference and Training
Point-wise Representation and Point Head
Experiment: Instance Segmentation
Overview
제목: PointRend: Image Segmentation as Rendering
저자: Alexander Kirillov, Yuxin Wu, Kaiming He, Ross Girshick
기관: Facebook (FAIR)
요약: 기존 image segmentation 연구들은 low resolution의 segmentation mask를 결과로 출력한다. 이 논문에서는 high-resolution의 segmentation mask를 detail하게 predict 하는 방법을 제안한다. Image segmentation을 rendering 관점에서 보고, classical한 rendering 테크닉인 adaptive subdivision[1] 방식을 차용한다. 기존 image segmentation 모델 (Mask R-CNN, FCN)에 flexible하게 적용 가능하다.
Motivation
Instance Segmentation의 대표 모델인 Mask R-CNN의 output mask의 크기는 고작 28x28이다. 이 결과를 high-resolution으로 upsample 하되, 아래처럼 더 detail한 mask를 생성하자는 연구다. 아래는 순서대로 본 논문의 figure 1,7이다.


Method overview
논문에서 제안하는 PointRend 모델은 다음 세 component로 정리할 수 있다. (아래 Point-wise Representation and Point Head 섹션의 그림을 보고 오면 이해가 잘 된다.)
Point selection strategy
Extract point-wise feature representation
Point head
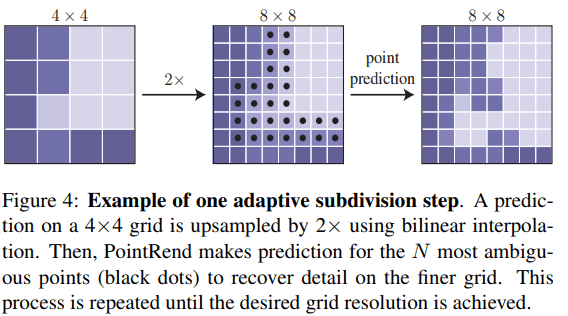
PointRend는 inference를 할 때 low-resolution 결과를 iterative 하게 upsampling을 하면서 adaptive subdivision을 적용한다. 각 iteration에서는 아래 그림처럼 bilinear interpolation으로 2x upsampling을 한 후에 point prediction을 하는데, 여기서의 point는 computational cost를 고려해서 모든 pixel이 아닌 소수의 point를 선정한다. 이때 point들을 선정하는 방식이 point selection strategy이다. 그 다음에는 선정된 point들에 대해 CNN feature에서 bilinear interpolation으로 point-wise feature representation을 얻는다. 이 point-wise feature를 point head로 label prediction을 한다.
아래 구체적인 method 설명은 instance segmentation에 기반한 설명이다.
Point Selection for Inference and Training
Inference
이 논문에서 차용하는 adaptive subdivision은 high-resolution image를 rendering 할 때, neighbor간의 값 차이가 큰 영역에서만 computing을 하는 기법이다. PointRend은 위 figure 4처럼 mask output을 iterative하게 2배씩 rendering 한다. 각 iteration에서는 bilinear interpolation으로 2배 upsampling을 한 후 point prediction으로 rendering 해주는데, prediction을 해야하는 point는 N개의 "most uncertain point"이다. 여기서 uncertain point는 binary mask일 확률이 0.5에 가까운 point를 의미한다.
Iteration의 횟수는 생각보다 적기 때문에 computational cost 가 적다. N=14^2이고 7x7를 224x224로 rendering 해주는 걸 생각하면 iteration은 5번이면 되고(32x7=224), 각 iteration에서 14^2개의 point에 대해서만 point prediction을 해주면 된다. 만일 일반적인 방식으로 224x224의 output을 출력하려면 224x224개의 pixel prediction을 해야하는데, 이에 비해 훨씬 가볍다.
Training
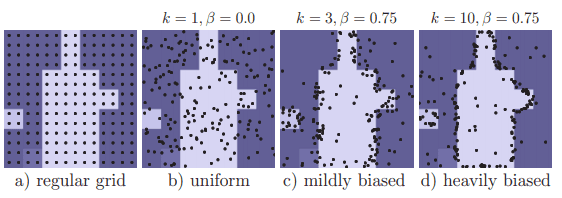
Training할때는 back-propagation을 생각했을때 iterative 한 방식은 쉽지 않다. 그래서 training을 할때는 point를 non-iterative하게 sampling 해줘야한다. Point selection은 uncertain region에 집중하되, 어느정도의 uniform coverage가 필요하다. 그래서 training point selection strategy는 아래 세가지 principle을 지키며, 아래 그림을 참고할 수 있다.
Overgeneration: 후보 point를 uniform distribution에서 kN개 sampling. (k>1)
Importance Sampling: most uncertain bN개 point 선정 (uncertainty estimate 방식은 instance segmentation과 semantic segmentation간에 차이가 있음) (0
Coverage: 나머지 (1-b)N개를 uniform distribution에서 sampling
실제 training은 아래 중 mildly biased (k=3, b=0.75) selection strategy를 따라야 결과가 가장 좋다고 한다.
Point-wise Representation and Point Head
아래 그림처럼 fine-grained feature와 coarse prediction feature를 결함하여 point-wise feature representation을 생성한다. Coarse prediction 부분은 기존 Mask R-CNN[2]의 mask branch를 살짝 변형한 모습이다. 기존 mask r-cnn의 mask branch는 4개 conv layer로 구성되어있다. 여기서의 coarse prediction branch는 2개 conv로 7x7 feature를 생성한 후에 두개 MLP로 7x7 mask prediction을 한다. (왜 그러는지는 의문...)
각 부분에서 point-wise feature는 각 point의 4 nearest neighbor로 bilinear interpolation을 통해 얻는다. Fine-grained feature는 256-dimension, coarse prediction feature는 K-dimension이다. (K는 class개수) 아래 그림처럼 두 feature를 concat하고 3 hidden layer MLP를 통과시켜 각 selected point에 대해 K-class prediction을 출력한다.

학습할때 loss는 두 가지가 있다. 우선 coarse segmentation prediction (7x7)에서 average cross entropy. 그리고 point prediction부분에서 c라는 class의 bounding box에 loss는 두 가지가 있다. 우선 coarse segmentation prediction (7x7)에서 average cross entropy (기존 mask r-cnn과 동일). 그리고 point prediction부분에서 c라는 class의 bounding box에 대해, N개 point의 c-th MLP output의 binary cross entropy가 있다.
Experiments: Instance Segmentation
기존 image segmentation의 metric인 AP와 mIOU가 boundary improvement에 insensitive하지만, 기존 segmentation 모델에 PointRend를 적용했을때 스코어가 오른다. 4x conv가 기존 Mask R-CNN이라고 볼 수 있는데, AP도 상승하고 FLOPs에서 큰 이득을 봤음을 확인할 수 있다. 그리고 실제 결과를 비교해보면 훨씬 detail한 mask를 잘 찾아냄을 알 수 있다. 그리고 high-resolution에서 masking을 더 detail하게 잘 한다.
Quantitative Results

Qualitative Results


Thoughts
매번 느끼지만 FAIR는 vision 분야에서 그들이 해결해야 하는 문제가 명확히 존재하고, "딥러닝+전통 비전 기술"으로 해결책을 제시한다. 그리고 논문에서 주장하는 포인트 하나하나씩 각 table 혹은 figure로 실험결과로써 보여주고 싶어하는 것 같다.
기존 segmentation 연구들의 output resolution이 작다는 건 알고 있었는데 왜 여태 아무도 이에 대해 의문을 품지 않았을까? 하는 생각도 든다.
현재 weakly-supervised instance/semantic segmentation 연구들은 아직 detail 한 masking을 잘 못하는데, 이쪽에도 adaptive subdivision을 적용할 수 있지 않을까 하는 naive한 생각이 든다.
Reference
[1] An improved illumination model for shaded display
[2] Mask R-CNN