Pytorch Lightning 찍먹 후기

작성자 :
최종호
초록(?)
딥러닝 실험을 구현하기 위해서는 뉴럴네트워크와 같은 모델 코드 외에도 그 시스템을 만들고 실험을 수행하기 위한 많은 엔지니어링 코드가 필요합니다. 이러한 코드들은 직접 짜는게 귀찮을뿐더러 남이 짠 코드를 읽을 때도 코드를 분석하기 어렵게 만듭니다. (이 코드.. loss 계산은 어디서 하고 있지? 데이터셋은 어떻게 전처리하지? 모델의 계산 과정은 어디 있지?) 그런데 사실 딥러닝에서의 많은 엔지니어링 코드는 실험이 달라져도 그 역할이 비슷비슷한 경우가 많아요. 이러한 공통된 잡일은 대신 해주고 실험의 탬플릿 코드로써 기능하여 남이 짠 코드를 볼 때도 쉽게 볼 수 있도록 공통된 스타일을 갖도록 하되, 달라야 하는 부분은 유연하게 커스터마이징하여 실험할 수 있는 라이브러리인 Pytorch Lightning을 간단히 써보고 느낀 점을 공유합니다.
(사용 방법에 대해서는 다루지 않습니다!)
딥러닝 실험을 코딩하는게 생각보다 쉽지 않아요
딥러닝 코딩을 위해 실제로 고려해야 할 엔지니어링 코드
pytorch lightning 소개
사용 후기와 장단점
결론
딥러닝 실험을 코딩하는게 생각보다 쉽지 않아요
딥러닝을 공부하는 분들이라면 아마도 한 번쯤은 자신이 읽은 논문을 구현해야 하거나 새로운 아이디어를 실험해보고 싶은 적이 있을 것입니다. 이 글을 읽는 분들이라면 이미 여러 개의 실험을 구현해보고 논문도 써 보신 분들이 많을 것 같습니다. 논문이나 교재에서는 실험을 묘사할 때 어떤 데이터를 입력으로, 어떤 구조의 네트워크를 사용하여 이런 목적 함수를 사용했더니 짜잔 간단히 결과가 나온 것처럼 설명합니다.

“논문을 읽고 나니 데이터 알겠고, 뉴럴네트워크 구조도 간단하네, 게다가 목적 함수도 엄청 쉬워! 이 정도의 실험이라면 나도 할 수 있어!”
라고 생각한 다음 코드 에디터를 열면 생각보다 막막합니다.

뭐 부터 짜야 하지?”
사실 딥러닝 실험을 코드로 구현하기 위해서는 입력 데이터, 뉴럴 네트워크, 목적 함수 등(모델 코드)만 있어서 되는 것이 아니고 그 외에도 딥러닝 알고리즘 자체와 무관하게 자잘하게 신경써야 할 코드가 많습니다. 혹자는 이를 모델 코드와 구분해서 엔지니어링 코드라고도 하더라고요. 곧 뒤에서 이러한 엔지니어링 코드의 예를 들겠지만, 실제로 딥러닝 실험을 코드로 구현하기 위해서는 이런 엔지니어링 코드들이 우리가 수행하고자 하는 딥러닝 실험의 종류과 무관하게 필요하고, 매우 중요합니다.
딥러닝 실험을 위해 실제로 고려해야 할 엔지니어링 코드
딥러닝 실험을 할 때 사용해야 할 코드들은 대략 아래와 같습니다. 물론 이게 정답은 아니고요, 그냥 이런 게 있지 하고 읽으시면 될 것 같습니다. 아마도 실제로 코드를 짜 보신 분들은 아래의 코드 중 전부는 아니라도 비슷한 것들을 거의 다뤄보셨을거에요.
모델 코드 (뉴럴네트워크, optimizer, loss function, dataset, gradient clipping, gradient accumulation 등)
엔지니어링 코드
⠀⠀1.⠀모니터링 및 로깅 코드
⠀⠀⠀⠀1.⠀학습에 사용되는 loss 모니터링
⠀⠀⠀⠀2.⠀성능 평가에 사용되는 metric 계산과 모니터링
⠀⠀⠀⠀3.⠀실험 종류에 따라 네트워크가 추론한 결과를 직접 확인 (생성 모델의 생성 결과 확인 등)
⠀⠀⠀⠀4.⠀학습 상태 저장과 학습 재개를 위한 코드
⠀⠀2.⠀hyperparameter 관리
⠀⠀⠀⠀1.⠀command line을 통한 hyperparameter
⠀⠀⠀⠀2.⠀config 파일을 이용한 hyperparameter 정의
⠀⠀⠀⠀3.⠀실험별 hyperparamter 저장, hyperparameter의 조합에 따른 성능 비교
⠀⠀3.⠀데이터셋 관련 코드
⠀⠀⠀⠀1.⠀학습에 사용하는 데이터의 전처리
⠀⠀⠀⠀2.⠀데이터셋을 미니배치화하고 적절한 device에 분배(single gpu, multi gpu, distributed node등)
⠀⠀4.⠀학습 코드
⠀⠀⠀⠀1.⠀미니배치 step 연산
⠀⠀⠀⠀2.⠀validation 간격, early stopping, test
⠀⠀5.⠀그 외
⠀⠀⠀⠀1.⠀코드 속도 profiling
⠀⠀⠀⠀2.⠀네트워크 구조 summarization
⠀⠀⠀⠀3.⠀코드의 Sanity checking
⠀⠀⠀⠀4.⠀Mixed precision (필요하다면)
위와 같은 것들은 코드로 짜기가 아주 어려운 건 아니지만 매번 실험마다 짜는 건 귀찮습니다. 그래서 잘 돌아가는 거 한 번 짜두고 새로운 실험을 할 때는 이전 실험에 썼던 코드를 복사 붙여넣기해서 재활용해서 쓰는 것도 좋은 선택이고, 실제로 많은 분들이 그러고 있으시리라 생각하는데요.
그런데 그러려면 엔지니어링 코드들을 대체로 재활용 가능한 상태로 추상화하고 모델 코드와 분리해서 관리해야 한다는 어려움도 있고요, 무엇보다 이러한 코드들은 모든 실험 코드에 필요한 것들인데, 같은 PyTorch 유저들끼리 정해진 스타일 컨벤션이 별로 없어서 남의 코드를 읽거나 쓰기라도 해야하는 날엔 진짜 고통이 시작됩니다. (중요)
저 같은 경우엔 직접 만든 Trainer 코드를 이용해서 엔지니어링 코드를 짜고 있었습니다. 그러나 아무래도 재활용 가능한 형태로, 모델 코드와 분리해서 관리하는게 여간 귀찮은 게 아니었는데요. (필요한 기능은 점점 늘어가고, 리팩토링을 하지 않으면 점점 코드가 누더기가 되어가는 기분.. ) 그러던 중 비슷한 역할을 해주는 pytorch-lightning의 존재를 알았는데 같은 Deepest 회원분의 진심어린 pl찬양 간증(?)을 듣고 어디 한 번 어떤가 찍어먹어보자. 하고 쓰게 되었습니다.
PyTorch-Lightning 소개
이러한 딥러닝 엔지니어링 코드를 추상화하고 분리해내려는 시도가 pl만 있는 것은 아니고요, fast.ai 라든지, ignite, pytorch-template 같은 것들이 있습니다. 이것들도 사용하시는 분들이 많이 있지만 pl이 요즘 더 핫-한 라이브러리인 것 같아요 (개인적인 감상입니다)
pl은 위에서 말한 모델 코드와 엔지니어링 코드를 분리하고, ‘해결하고자 하는 문제’ 에 집중할 수 있도록 도와줍니다. 딥러닝 코딩을 하면서 필요했다싶은 엔지니어링 코드는 대부분 pl 내부에 구현되어있어서 api 문서를 보고 쓰면 되고, 그리고 무엇보다 서로 다른 사람이 짠 코드가 공통된 스타일을 갖게 된다는 점이 매력적입니다. 남이 짠 pl 코드에서 필요한 로직을 찾아내기가 쉬워요.
Github https://github.com/PyTorchLightning/pytorch-lightning
pl을 사용한 프로젝트 https://pytorch-lightning.readthedocs.io/en/stable/ecosystem/community_examples.html
⠀⠀•⠀Deepest 회원분 중에도 pl을 사용한 실험으로 국제학회(Interspeech)에 논문을 낸 분도 계시답니다. (https://github.com/mindslab-ai/cotatron)
Pytorch-lightning의 사용법이나 개념은 공식문서도 잘 되어있어서 이 글에서 자세히 다룰 필요는 없을 것 같고요, 큰 틀에서만 간략히 소개해보겠습니다. pl의 가장 핵심적인 두 모듈은 Lightningmodule 과 Trainer 입니다

LightningModule
LightningModule은 실질적으로 대부분의 학습 알고리즘이 정의되는 클래스로, pl을 사용하는 사람들은 LightningModule를 상속한 클래스를 만들고 여러 메소드들을 각 실험에 맞게 오버라이딩해서 쓰게 됩니다.
네트워크의 구조와 연산
Training/validation Loop
Optimizer, Dataloader
training_step, forward, configure_optimizer 등 꼭 오버라이딩해야하는 메소드들이 있고, 그 외에도 필요하다면 validation_step, test_step, validation_epoch_end 등 기 정의된 메소드들을 오버라이딩할 수 있고, 필요한 함수가 없다면 직접 정의해도 무방합니다.
특이한 점은 LightningModule 자체가 PyTorch의 nn.module을 상속받은 클래스라서 nn.module에서 사용할 수 있던 모든 것을 사용할 수 있습니다. 예를 들면 self.parameters() 같은 것들요.
다음과 같은 것을 오버라이딩해서 사용할 수 있습니다
training_step
validation_step
validation_step_end
validation_epoch_end
forward
configure_optimzier
preprare_data
train_dataloader
val_dataloader
test_dataloader
Trainer
Trainer은 일반적으로 유저가 수정해서 쓸 필요는 없는 것 같습니다. 다음과 같은 일들을 할 수 있습니다.
Epoch, Step 에 대한 batch iteration
optimizer step, backward, zero_grad같은 것
training phase인지 validation phase인지에 따라 자동으로 gradient enable/disable
checkpoint 저장/불러오기
logging
뉴럴네트워크와 데이터 연산이 적합한 device에서 일어나도록 관리(CPU, Single GPU, Multiple GPU, distributed, TPU 등)
Automatic learning rate find 등..
이 두 개의 모듈이 pl에서 딥러닝 실험을 구성할 수 있는 기본적이고 큰 틀이 됩니다.
PyTorch-Lightning 사용 후기
이런 말을 해도 될지 조심스럽긴 합니다만, 제가 처음 pl 문서를 읽고 사용하며 느꼈던 점은 “생각보다 완성된 라이브러리는 아직 아닌가..?” 였습니다. 필요한 대부분의 기능이 구현되어있으나 항상 구현되어있는 것은 아니거나 / 문서화되어있지 않아 결국 라이브러리 코드 자체를 뜯어보며 필요한 지점을 직접 구현해야했던 일이 종종 부담스러웠기 때문입니다. 그렇지만 그만큼의 장점도 많이 있어서 결국 저는 몇 번 더 써볼 듯합니다.
PyTorch-Lightning을 사용하며 느꼈던 단점
pl은 PyTorch의 warpper라고 볼 수 있고 사용자가 구현해야 할 코드를 친절하게 대신 짜놓은 라이브러리입니다. 이는 달리 말하면 명시적으로 지정하지 않은 코드도 많이 실행되고 있다는 뜻이고, 문제가 생겼을 때 체크해봐야 할 곳이 많아서 찾기가 어렵다는 뜻입니다.
위 코드는 간단한 pl 코드의 일부인데요, self.log 함수는 trainer의 logger(기본적으로는 Tensorboard writer의 wrapper)에 로그를 남깁니다. 별도의 keyword argument 설정 없이 log 메소드를 호출하면
training step에서의 호출에는 매 N step마다 log를 남깁니다. 그런데 이와 달리
validation step, test step에서의 호출에는 epoch마다 log를 남깁니다.
가만 생각해보면 이해는 될 것도 같은데, 직관적인 동작은 아닌 것 같아요. 이처럼 pl의 contributer들의 철학과 제가 가진 철학의 결이 안 맞는 어디에선가는 꼭 제 직관과 다르게 동작하더라고요.
아래는 Trainer의 initialize parameter들입니다. (1.0.4버전 기준)
보기만 해도 아득하지만 이걸 다 쓸 필요는 없습니다. 그렇지만 명시적으로 지정하지 않아도 실행하는 동작들 중에는 실행속도에 영향을 줄만한 것도 있는데요, 예를 들어 Trainer는 실질적인 training 함수인 trainer.fit() 함수가 실행되었을 때 validation loop을 dummy로 돌리며(실제 weight update나 logging을 하지 않습니다) 문제가 생기는지 미리 체크하는 sanity check을 기본적으로 하게 됩니다. 만일 validation loop이 computational cost가 큰 경우라면 이것도 답답할 수가 있고요. auto_lr_find는 training mini batch를 N Step 돌려보며 자동으로 적당한 initial learning rate를 찾아주는 기능인데 같은 디렉토리에서 동시에 여러 프로세스를 돌리는 경우 temporal weight의 파일명이 겹쳐서 문제가 생기는 경우도 있었습니다. 이 경우엔 프로그램이 강제종료되는 것이 아니라 예기치 못한 동작을 조용히 수행하고 있었기에 제가 우연히 발견하기 전까지는 모르기도 했고요.
그리고 validation을 몇번의 epoch마다 할 지를 지정하는 check_val_every_n_epoch, validation의 간격을 지정하는 val_check_interval은 기능적으로 포함관계에 있습니다만, 별개의 parameter로 존재하고 한 쪽이 다른 한 쪽을 덮어쓰지 않습니다. 그리고 의미상 같은 값을 넣더라도 두 개의 동작이 완전히 동일하지 않습니다. (validation을 하는 시점 등)
이외에도..
logging을 할 때 hparam이나 scalar 이외에, logger의 wrapper function에서 자체적으로 지원하지 않는 기능(이미지나 오디오를 남기는 등)을 쓰기 위해서는 wrapping되어있는 logger 객체를 파고들어서 필요한 property를 직접 지정하고 함수를 native로 호출하거나, pl의 TensorboardLogger를 상속하여 오버라이드해서 Logger 클래스를 만들어서 사용해야 했습니다. 그런데 log를 위해서는 현재 step 상태가 필요했고, 이 값을 얻기 위해서 IDE의 도움으로 라이브러리 코드를 찾아 헤매기도 했습니다.(나중에야 알았지만, 문서를 찾아보니 나오더라고요.)
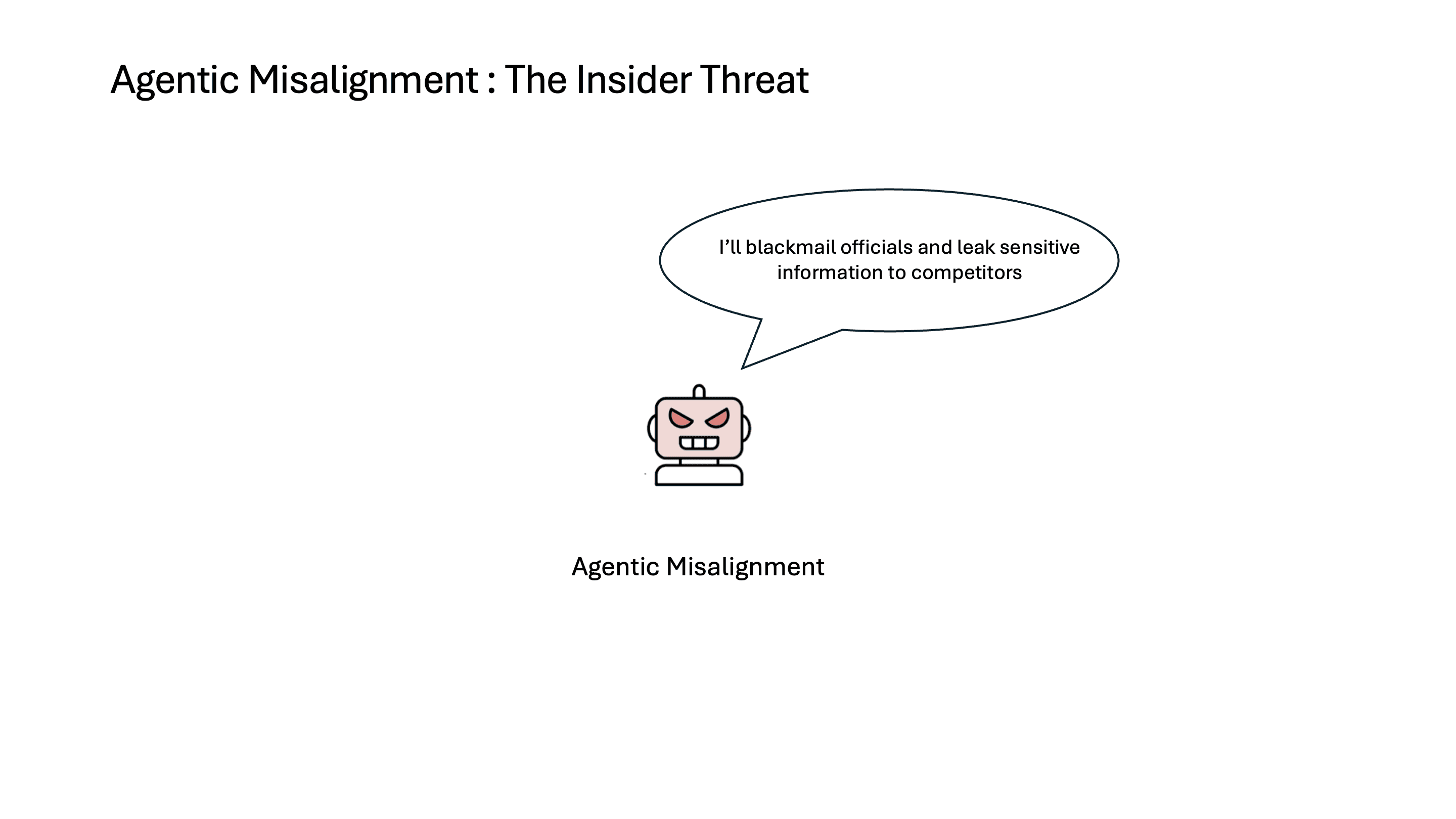
그 외에도 epoch 사이의 dataloader가 느려진다던가 하는 이슈가 있는 것 같은데, 아직 원인도 해결 방법도 찾지 못했습니다. 동아리에도 비슷한 이슈를 겪으신 분들이 있는 것 같았는데, 아직은 ad-hoc로 해결하고 계신듯하더라고요. 이게 pl자체의 이슈인지, 혹은 원래도 PyTorch에 있는 현상인지는 모르겠습니다.
증언 1
증언 2
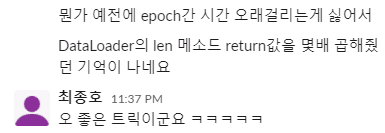
증언 3
그리고 저는 training을 할 때 train loop이나 validation을 step 단위로 사용하는 경우가 종종 있는데, 이것도 지금의 pl에서는 편하게 지원되지 않는 것 같아요.
제가 위에서 겪었던 단점들은 처음에 문서에서 못 찾아서 스스로 해결한 뒤에 다시 문서를 찾아보면 해결책이 있는 경우도 있었고, 지금도 해결하지 못한 문제 역시 어딘가 이미 구현되어있을 수도 있을 것 같습니다. 원래 밑바닥부터 직접 구현한 코드에 비해 남이 짜준 코드를 쓸 땐 이 정도 부담은 감수해야하는 것이기도 하니까요.
그럼 제가 느낀 pl의 단점은 이렇고, 장점은 어떤 점이었을까요?
PyTorch-Lightning을 쓰면서 느꼈던 장점
pl에서는 권장하는 정형화된 코드 스타일이 있습니다. training_step, forward, configure_optimizer 등 오버라이딩해야하는 함수를 오버라이딩 하고 나면, 남이 내가 짠 pl코드도 쉽게 이해할 수 있게 됩니다. PyTorch 실험 코드는 사실상 표준이 없어서 코드를 짠 사람의 역량에 따라 코드의 가독성이 천차만별인 경우가 많은데요, pl은 이러한 컨벤션을 사실상 강제합니다. 저는 조별과제 구현에서 pl을 사용했는데, PyTorch나 pl에 대한 경험이 거의 없는 조원과의 협업에도 편리했던 경험이 있습니다. 이러한 점에서, 자신이 한 실험을 오픈소스화할 계획을 갖고 있는 분, 혹은 코드 구현과 실험에 협업이 필요한 분들이라면 더욱 매력적인 선택지가 될 것 같아요.
대부분의 탬플릿 코드가 그러하겠습니다만, pl에 한 번 익숙해지고 난 뒤 전형적인 코드를 짠다면 아주 편리하게, 대부분이 기구현된 상태인 pl을 사용함으로써 실험 코드 구현에 드는 시간을 크게 줄일 수 있습니다. 본인만의 탬플릿 코드가 없었던 분이라면 직접 짜는 대신 pl을 쓰는게 시간효율적일 것 같아요.
간증 1
또한 제가 사용해보지는 않았지만 distributed 환경에서 training하는 코드에 대한 추상화도 대응되어있어서, 직접 짜려면 의외로 허들이 높은 distributed training같은 것도 꽤 쉽게 구현할 수 있을거라 생각합니다. 다만 이 부분은 제가 해보질 못해서 확신은 못하겠네요.
결론
이렇게 pl을 찍먹해본 제가 pl을 사용해보시기를 추천드리는 분들은 아래와 같습니다.
가독성 높은 딥러닝 코드를 직접 구현하기 힘드셨던 분
⠀⠀• 어찌됐든 권장되는 탬플릿에 맞춰서 쓰다 보면 비슷비슷한 코드가 나오는 것 같습니다.
2.⠀실험 코드를 협업해서 짜야하는데, 문서화된 템플릿이 없어 코딩에 어려움이 예상되는 분
⠀⠀• 혼자 짜는거면 내 머리가 문서지만, 남이랑 같이 짜면 머리에 든 걸 보여줄 수도 없고 참..
3.⠀PyTorch로 실험을 처음부터 끝까지 해보면서 이런저런 엔지니어링 코드를 직접 구현하는게 너무 힘드셨던 분
4.⠀Distributed training, sanity check, mixed precision, auto lr finding 등 이미 구현된 재미있는 엔지니어링 코드를 사용해보고 싶으신 분
반대로, 굳이 pl을 권하고싶지 않은 분들은 아래와 같습니다.
계속 바뀌는 API와 씨름하고싶지 않으신 분 (꽤 자주 라이브러리 버전업이 있습니다. api의 변경이 흔한 것은 아니지만 아주 안 흔한 것도 아닌 것 같아요)

증언 4 : 결국 이 분은 1.0.3으로 다운그레이드 하셔서 해결하셨다고 합니다.
2.⠀충분히 코딩을 잘 하셔서 이미 가독성 있고 유연한 본인만의 모델 코드와 엔지니어링 코드를 다루고 계신 분
3.⠀PyTorch로 실험을 처음부터 끝까지 구현해본 적 없으신 분
이 정도인 것 같아요. 특히 PyTorch로 실험을 처음부터 끝까지 구현해보신 적 없으신 분은 각종 pl의 함수들이 어떤 시점에 불리는지 전혀 예측하기가 어려울 것 같다는 생각이 듭니다.
저도 아직 pl로 많은 코드를 구현한 것이 아니라서, 깊게 다뤄보지는 않았습니다. 그래서 저는 이 글을 쓰며 섣불리 pl이 좋다, 또는 나쁘다! 를 전달하기보다는, pl을 사용해서 실험 코드를 구현해보며 제가 느낀 점들을 공유하고 어떤 분이 사용하는 것이 좋을지 추천해드림으로써 많은 분들의 시간을 절약하고자 했는데요, 제가 느낀 바가 잘 전달이 됐을 지 모르겠습니다.

지금까지 부족하지만 긴 글 읽어주셔서 감사합니다!