TedEval: A Fair Evaluation Metric for Scene Text Detectors

작성자 :
Louis Park
Introduction
OCR에서 글자 영역 검출(text detection) 모듈은 주로 object detection의 모델이 그대로 쓰이는 경우가 많기 때문에 IOU기반의 mAP등 object detection에서 쓰이는 메트릭을 그대로 사용하는 경우가 많다. 하지만 다음과 같은 경우들 때문에, 이러한 메트릭으로만 실제 OCR 모델의 성능을 측정하는 것은 한계가 있다.
Granularity and Completeness

Granularity
Completeness
여기서 DetEval은 기존 IOU 기반의 방법들 대신 OCR에서 쓰기 위해 고안된 메트릭으로, ICDAR 대회의 리더보드에도 쓰이고 있다고 한다. 2005년에 나온 이 논문에서 제시되었다.
Method
Pseudo Character Center
Granularity와 Completeness 문제를 해결하기 위해 TedEval이 제시하는 방법의 핵심 아이디어는, 단어 단위의 라벨에서 적당히 글자들의 대략적인 위치를 찾고, detection결과에 그 점이 들어있는지 여부에 따라 스코어를 계산하자는 것. 라벨을 사용해 계산한 글자 중심들을 PCC(Pseudo Character Center)라고 부르며, 계산방법은 다음과 같이(그림만 봐도 이해가 될 정도로) 매우 간단하다.
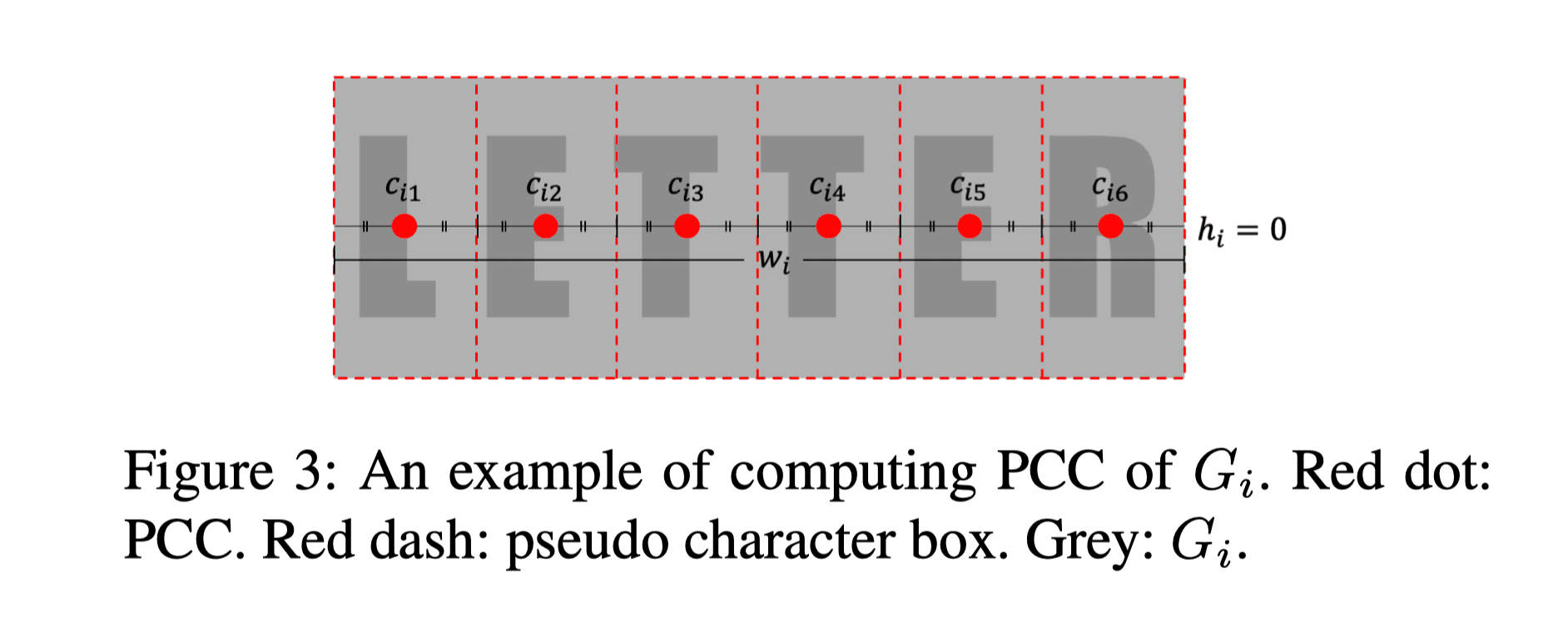
논문에는 좀더 수학적인 표현으로 되어있지만, 간단히 말하자면 GT에 나온 단어의 길이가 n이라고 할 때(Fig.3에서는 6), 단어의 좌우 모서리의 중점을 잇는 선분을 찾아 그것을 2n등분 한 뒤 홀수번째 점들을 글자 중심으로 사용하자는 것이다. 글자가 어느 방향으로 써있는지를 어떻게 판단하는지 궁금했는데, 글자 방향에 따라 annotation에서 좌표들의 순서가 일정하게 되어있다고 가정이 깔려있었다.

Matching Process
TedEval계산의 첫 스텝은 각각의 detected bbox가 어떤 GT에 해당하는지 매칭하는 것. 각각의 GT, Prediction쌍마다 1 또는 0의 값을 갖는 binary matrix가 나온다. 기존 연구인 DetEval에서와 마찬가지로 area recall, area precision을 계산해서 thresholding을 하지만, 사용하는 threshold값을 크게 낮추어 웬만하면 이 단계에서 제외되는 GT-prediction 쌍이 적도록 했다. 또, DetEval에서는 한개의 GT에 여러개의 prediction이 매칭되어도 첫번째 prediction만을 가져와 사용하는데, TedEval에서는 one-to-many, many-to-one케이스를 잡기 위해 일단 전부 통과시키고 뒤에서 걸러내는 방법을 사용한다.
다만, multi-line text가 하나의 박스로 잡히는 경우는 매칭 단계에서 별도로 걸러내는데, one-to-many, many-to-one 매칭이 생기면 many쪽에 있는 박스들의 모든 pair에 대해 아래 Fig.2와 같이 단어의 양 끝단과 중심 사이의 각도를 계산해서 45도 이상일 경우 multiline으로 판단하고 매칭 스코어를 0으로 조정하는듯.

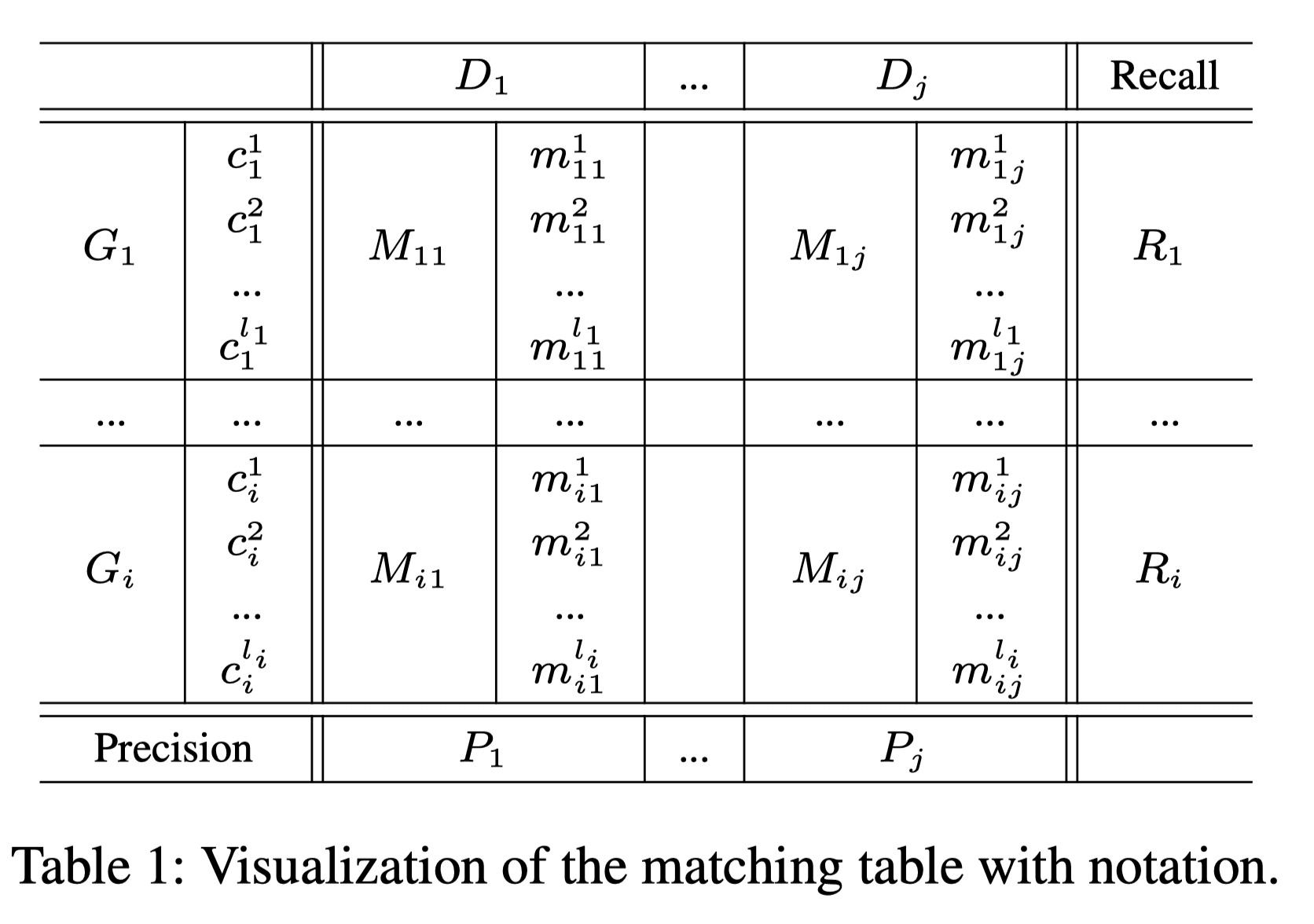
여기까지 하면 위 Table.1 에서 각각의 GT(G_i), Prediction(D_j)마다 matching score(M_ij)를 구한것.
Scoring Process
여기부터는 부록에 있는 예시들을 보는 게 이해하기 훨씬 쉬운 것 같다.
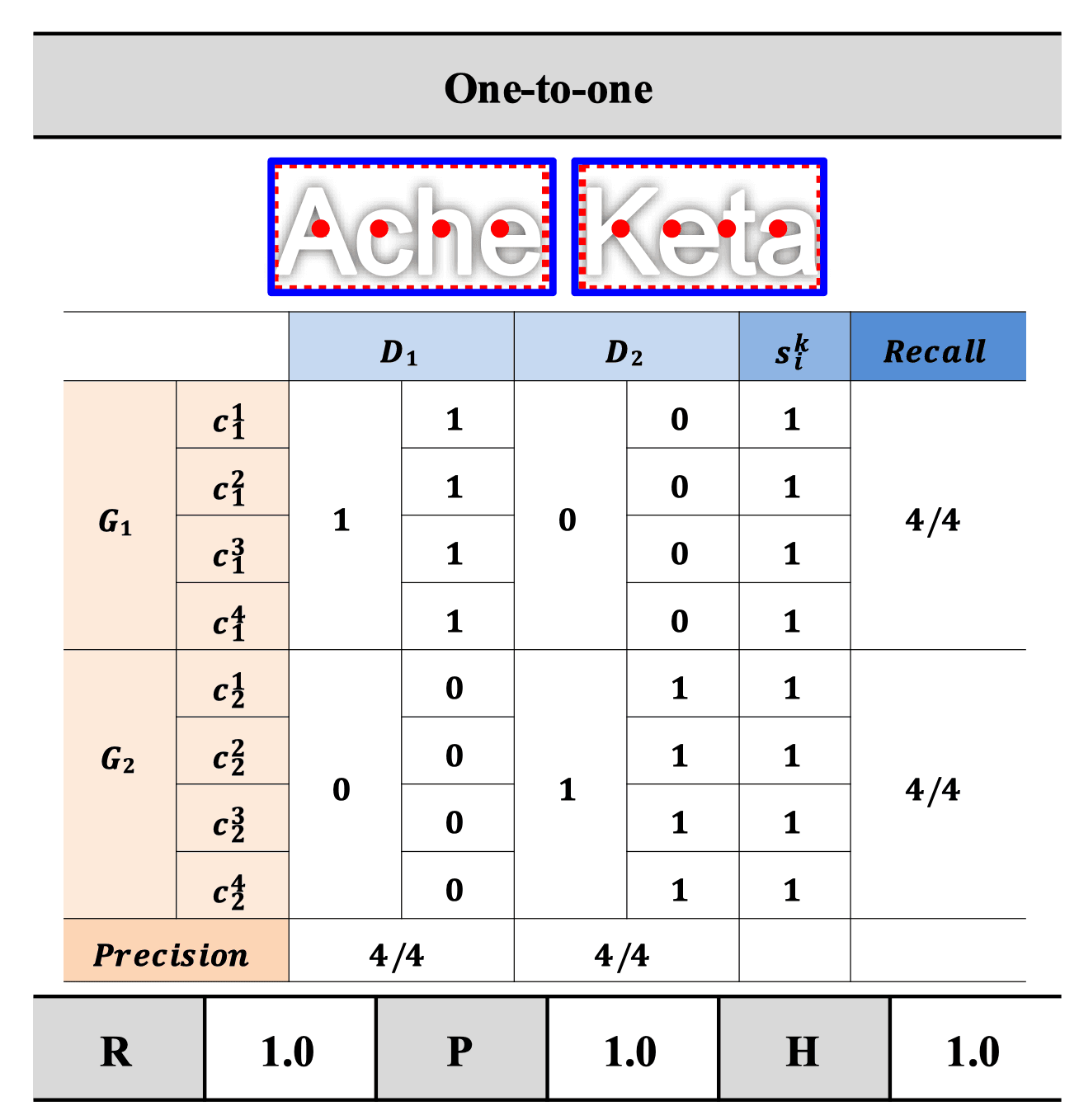
모든 GT박스가 잘 detect된 경우 matching table은 위와 같이 나타난다. GT 라벨의 bbox(빨간 점선)와 라벨의 글자수를 가지고 계산한 글자 중심(PCC, 빨간점) 8개는 표의 각 row에 대응하는데, k번째 GT의 i번째 글자에 대한 s_i^k는 각각의 PCC가 몇번 Detect 되었는지 나타낸 스코어라고 볼수 있다. 이 경우 GT의 모든 글자들이 한개씩의 detection box에만 포함되므로 Recall이 1로 나오고, 모든 Detection의 매칭된(M_ij == 1) GT에서 모든 글자가 detect 되었으므로 Precision도 1이다.
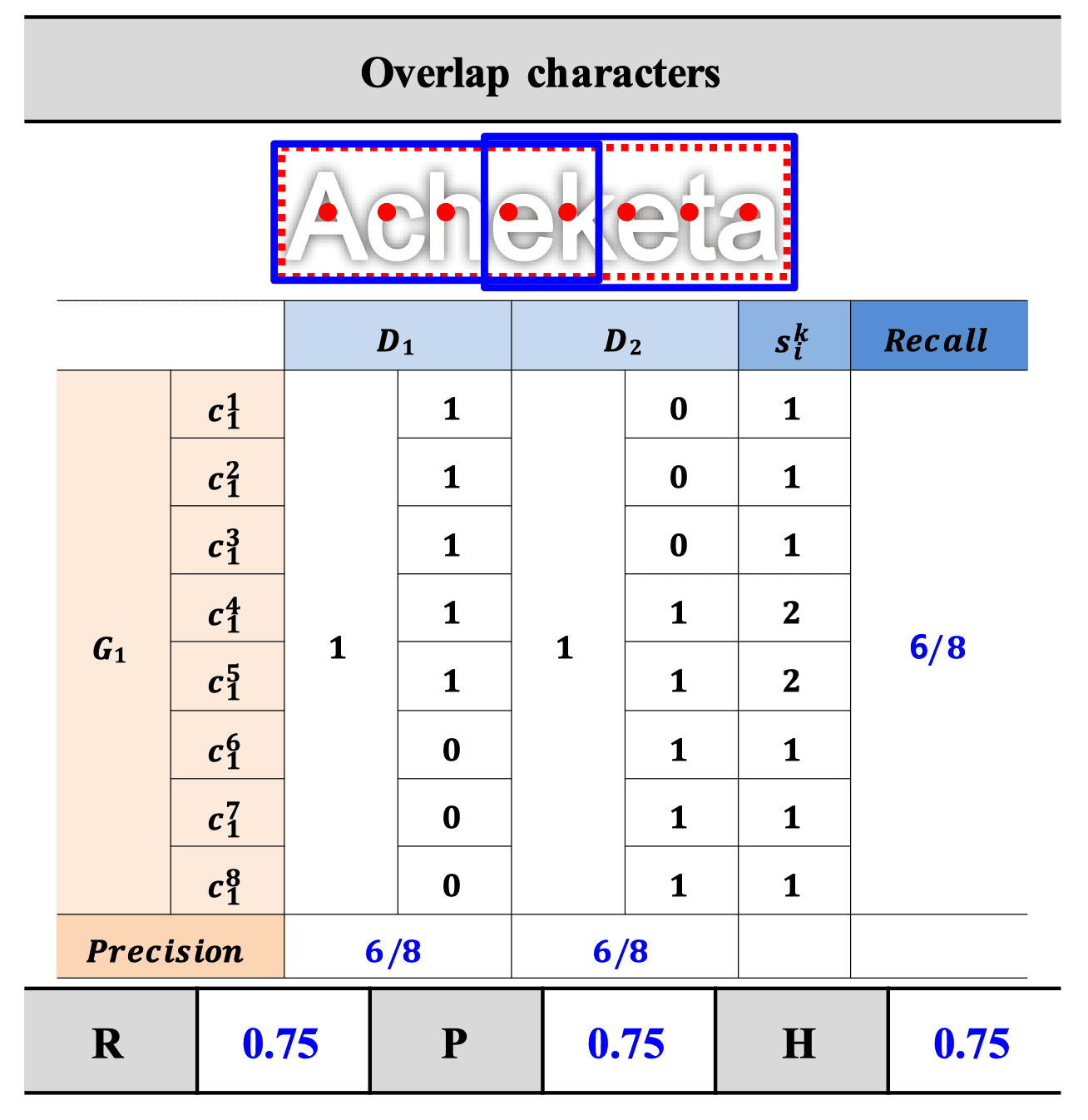
정리하자면, Recall은 각각 GT박스마다 계산되며, GT의 글자(PCC)마다 s값이 정확히 1인 것들의 비율로 계산한다. 위 샘플에서는 총 8개 PCC중 2개 prediction에 중복되어 잡혔으므로 6/8로 계산됨. Precision의 경우 predicted bbox마다 계산하며, detect된 PCC 수 / 매칭된 GT의 글자수로 계산한다. 위 표에서는 아무리 생각해도 Precision이 둘다6/8이 아니라 5/8인것 같은데... 그냥 잘못 써둔게 아닐까 싶다.
Usage
트레이닝이 끝난 OCR모델을 가지고있다면, 클로바에서 공개한 코드를 통해 간단하게 TedEval 스코어를 구해볼 수 있다. GT 라벨과 모델 output을 zip으로 압축해놓고 돌리면 평가해주는 방식이며, visualization tool도 제공해주는 듯 하다. 자세한 내용은 공식 깃헙 리포지토리를 참고.
Discussion
직접 구현도 시도해보고, 상당수 이미지에 visualization해서 살펴본 결과, 실제 적용하기 전에 다음 내용들을 한번 생각해보면 좋을 것 같다는 생각이 들었다.
글자 방향 판단
세로쓰기로 되어있는 라벨에서 PCC를 계산하면 가로선이 아니라 세로선에 PCC가 잡혀야 하며, 이게 잘못될 경우 값이 상당히 잘못될 수도 있다. 논문에서는 글자의 방향을 aspect ratio나 각 선분의 길이로 판단하지 않고 글자 방향에 따라 라벨에서 좌표가 등장하는 순서가 고정되어있다고 가정하는데, 자체적으로 수집한 데이터가 아니라 ICDAR 데이터셋 등의 공개 데이터셋을 사용하는 경우, 라벨링이 이렇게 되어있다고 가정하기는 힘들것.
아닌가...? ICDAR홈페이지에서 데이터셋 설명을 다시한번 찾아보긴 해야겠다.
사실 저 설명만 들으면 90도 돌아간 글자 말고 세로쓰기는 어떻게 처리하는 게 맞는지 애매하기도 하다.
'###'이 세글자짜리 단어로 나타나는 문제
ICDAR 데이터에서 글자를 확인하기 어려운 경우 텍스트 라벨을 '###'으로 두는데, 이 '###'이 3글자 단어로 인식되면서 역시 PCC 계산이 살짝 이상해진다. 명백하게 한글자, 혹은 열글자 이상인 단어인데 PCC좌표가 세개만 달랑 찍혀있게 되는 것. 사실 ###으로 되어있는 라벨의 경우 evaluation을 살짝 덜 정확하게 한다고 해서 문제가 되는 경우는 많이 없고, 정 거슬리면 가볍게 필터링해서 사용할 수 있기 때문에 심각한 문제는 아닌듯.
띄어쓰기 처리
GT에 띄어쓰기가 들어간 단어가 있을 때 모델 결과물은 띄어쓰기에서 두 단어로 나뉘어 잡히는 경우가 많다. 이럴 때, 띄어쓰기에 해당하는 PCC는 두개로 나뉜 bbox 사이에 위치하기 때문에 보통 절묘하게 bbox밖에 위치하게 되는데, 인식에 필요하지 않은 띄어쓰기가 평가에 영향을 미쳐 모델 성능이 (살짝) under-estimate되는 경우가 있을 것이다. PCC를 찾을때 라벨에서 띄어쓰기에 해당하는 위치는 제거하는 방식으로 성능을 개선할 수 있지 않을까?
#카카오 #dpr2020