Tool-use Ability and Multi-Agent System

작성자 :
홍성훈
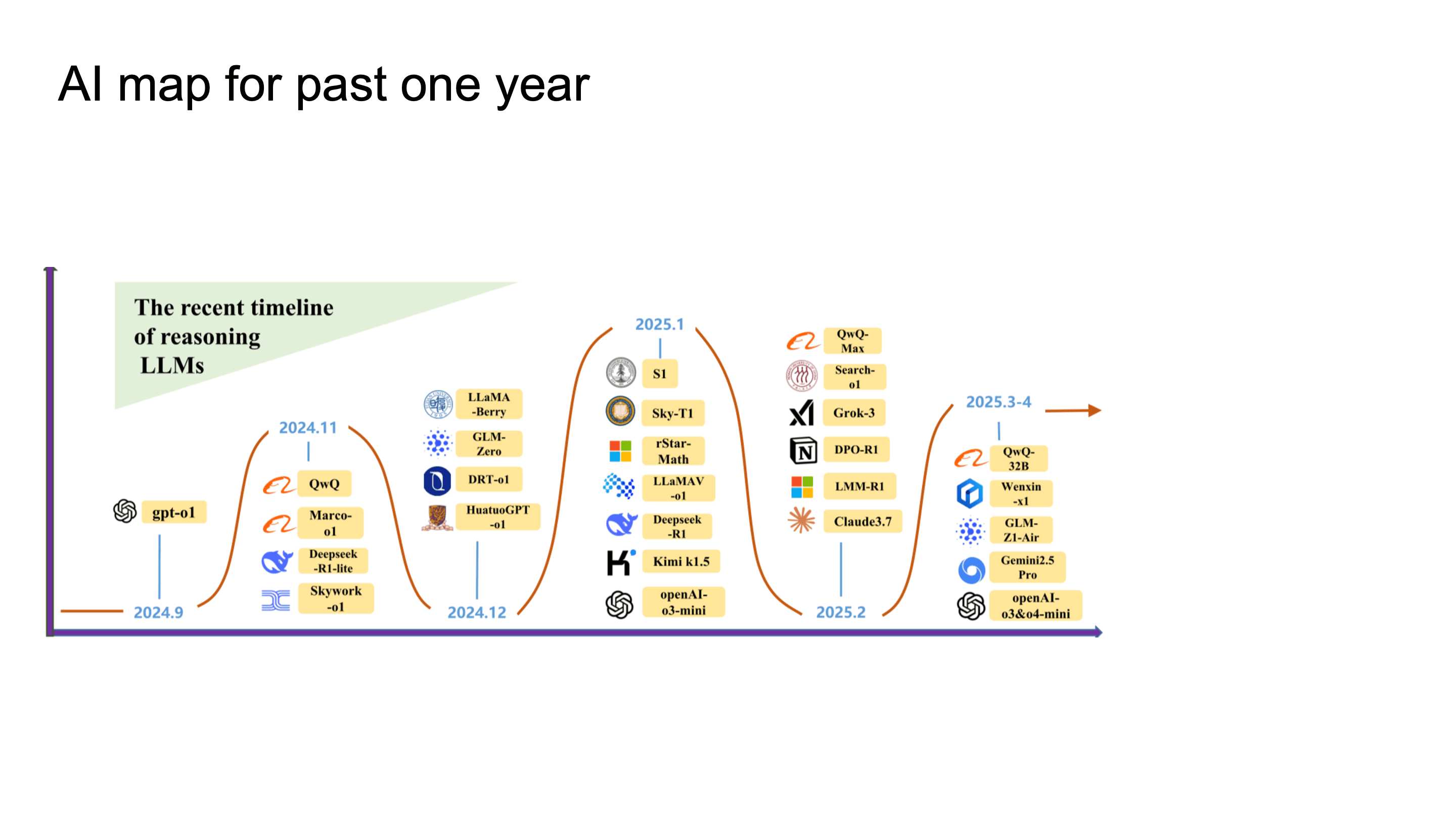
2024년 하반기부터 2025년 상반기까지 gpt-o1을 시작해 Deepseek-R1, o3, o4 등 1년 밖에 되지 않는 기간에 엄청나게 많은 변화가 일어났습니다. OpenAI가 o1, o3를 내놓으면서 inference-time에 더 많은 compute를 투입해 reasoning quality를 올리는 패러다임이 자리를 잡았던 시간이었습니다.

Reasoning model은 IMO 금메달을 딸 정도로 발전했지만, 실제 태스크를 수행할 때 context가 없어서 제대로 수행하지 못하는 경우도 많았습니다. 그래서 context engineering, memory 등 LLM의 external capability를 부여하는 시도가 많아졌습니다.
그 중에서도 특히 tool-use ability를 이 글에서는 주로 다루고자 합니다.
모델이 internal reasoning만으로 해결하려 하지 말고, calculator, search engine, code interpreter 같은 external tool을 호출해서 그 결과를 context에 다시 주입하는 것입니다.
이렇게 하면 arithmetic이나 factual knowledge 태스크에서 hallucination 없이 효과적으로 정확도를 높일 수 있습니다.
Tool Ability란 무엇인가

Tool ability는 크게 세 가지 축으로 정의할 수 있습니다. What - 어떤 툴을 호출할 것인가, When - 어느 시점에 호출할 것인가 (invocation timing). How - 어떤 argument를 구성할 것인가.
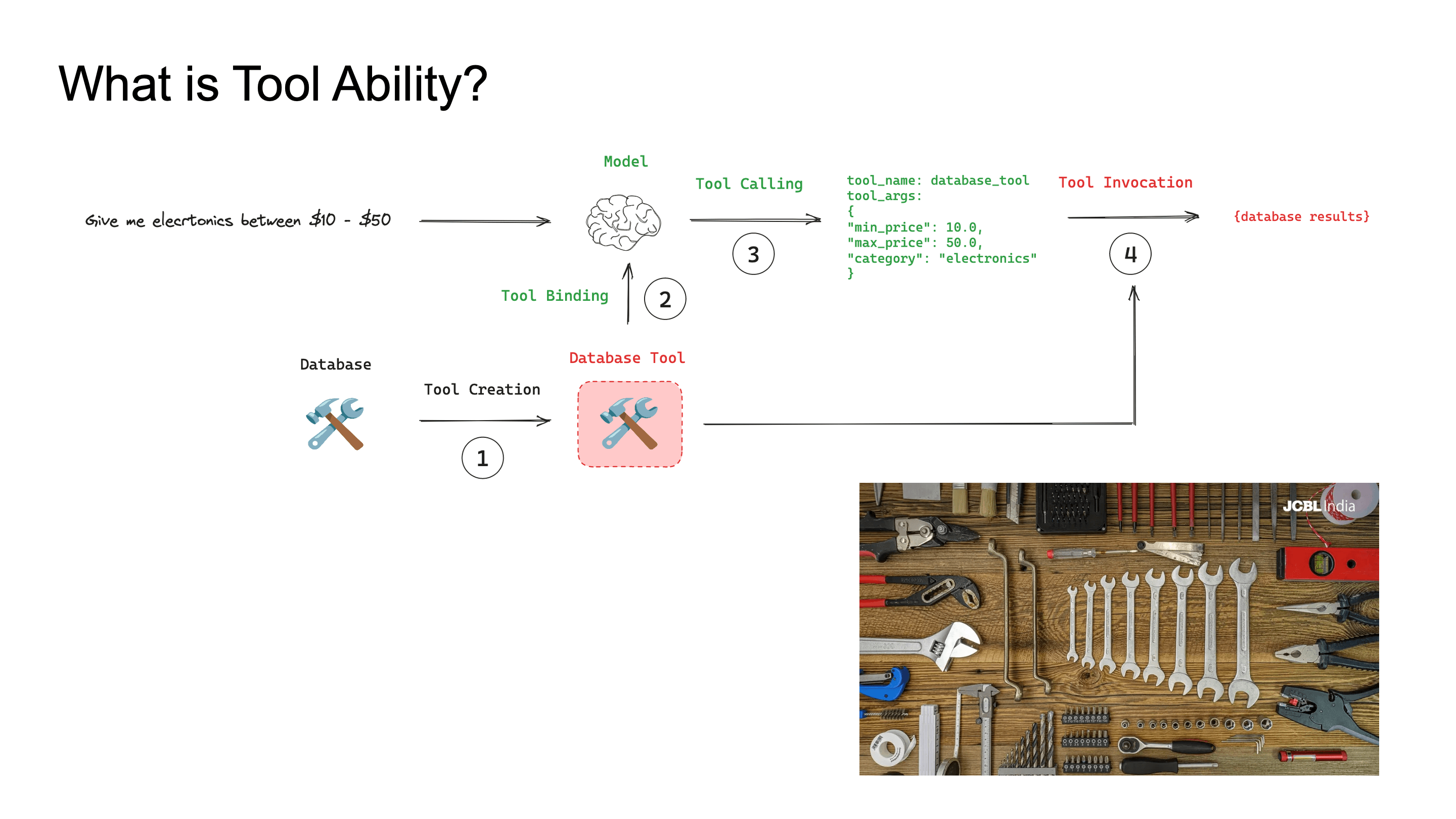
LLM의 tool calling은 생각보다 단순합니다. user query를 받아서 적절한 API를 select하고, schema에 맞는 argument를 construct해서 호출하고, 그 response를 다시 자기 reasoning context에 반영하면 됩니다
이 글에서는 Tool ability를 학습시키는 두 가지 큰 흐름, SFT 기반 접근과 RL 기반 접근을 중심으로 살펴보고, evaluation benchmark, 그리고 Multi-Agent System 예시까지 다뤄볼 예정입니다.
Part 1: SFT 기반 Tool Ability
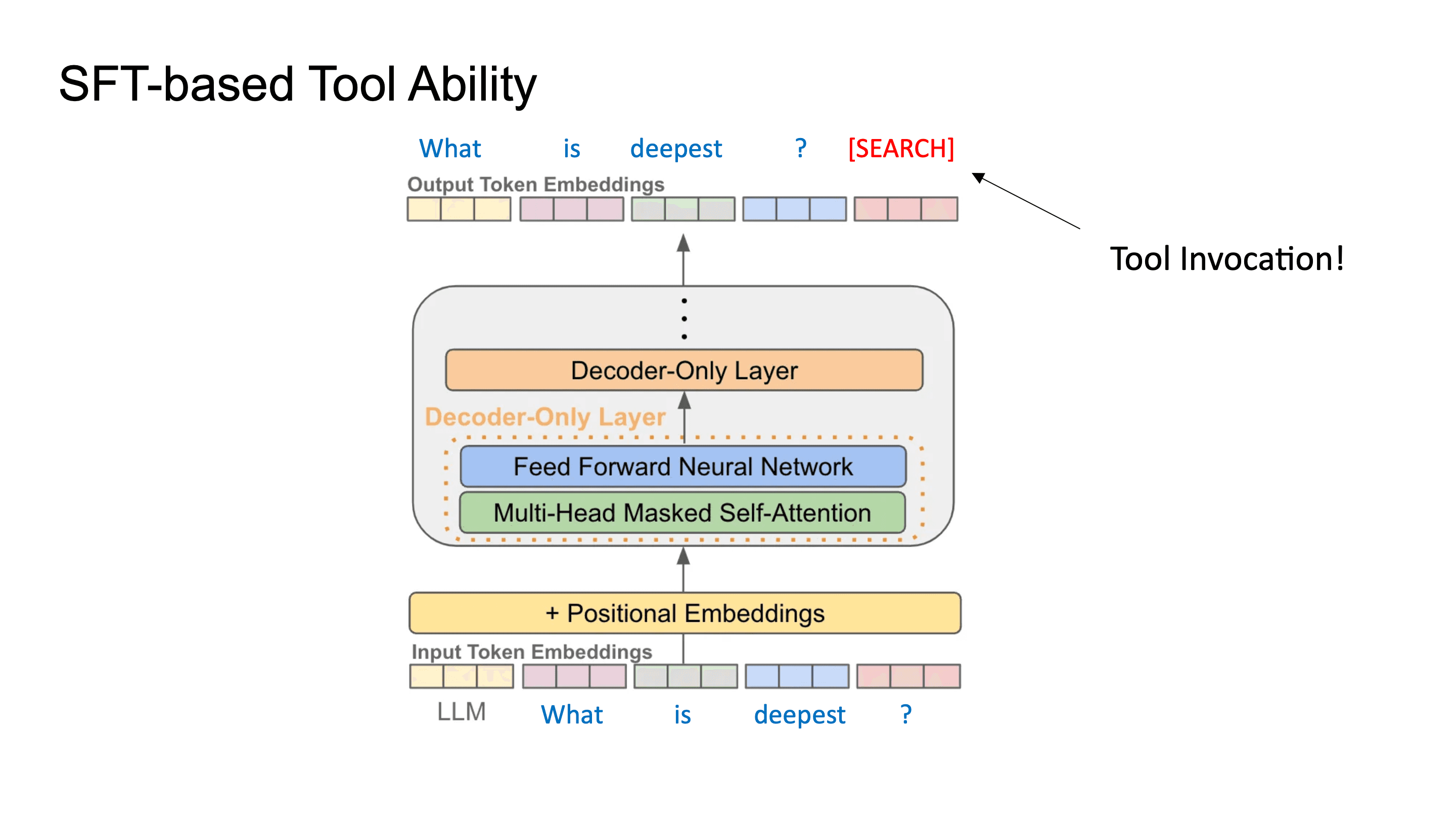
만약 유저가 What is deepest? 라는 입력을 했다고 할 때, LLM은 그 다음 토큰을 예측하는데 있어서 internal reasoning을 하지 않고 웹 검색을 통해서 Deepest가 무엇인지 알 수 있다면 정확한 정보를 제공할 수 있을 겁니다. 이런 아이디어로 연구된 논문이 ReAct 입니다.
ReAct: Reasoning과 Acting의 Interleaving
ReAct의 핵심 아이디어는 LLM의 action space를 language space로 확장한 것입니다.
기존에는 reasoning trace와 action execution이 별도의 module이었지만, ReAct는 reason과 act 토큰을 하나의 시퀀스로 합쳤습니다.

구체적으로 보면, 모델이 search[entity], lookup[entity], finish[answer] 같은 action을 text token으로 생성합니다. In context learning만으로도 reasoning-action trajectory를 내뱉을 수 있었고, 3000개 trajectory로 fine-tuning했을 경우 더 stable한 성능을 보였습니다.
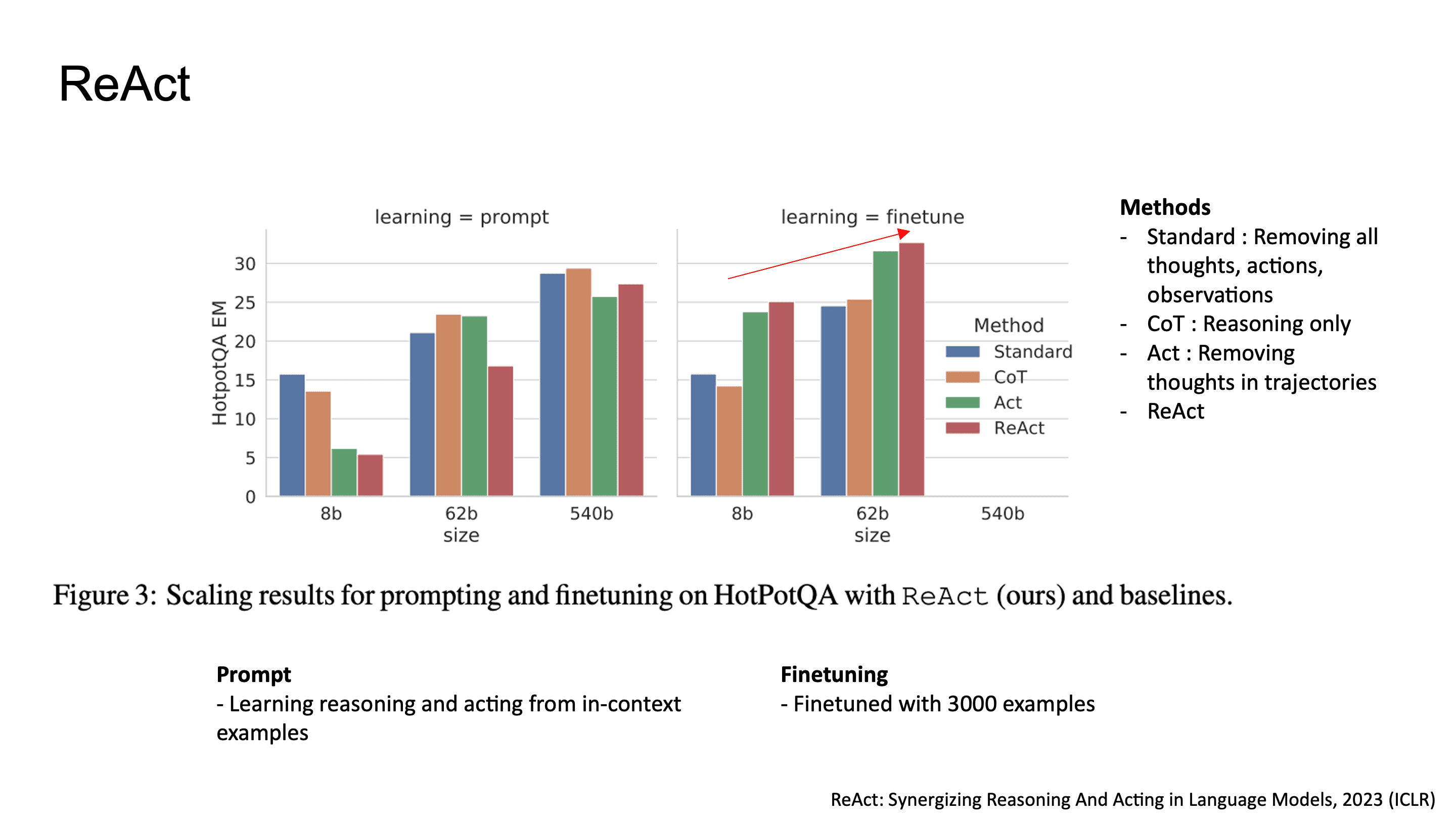
ablation에서 ReAct는 Standard(no thought, no action), CoT-only(reasoning만), Act-only(action만)와 비교했는데, finetuning까지 거쳤을 때 ReAct의 성능이 다른 방법에 비해 차이가 나는 것을 볼 수 있습니다.
Toolformer: Self-supervised Tool Learning

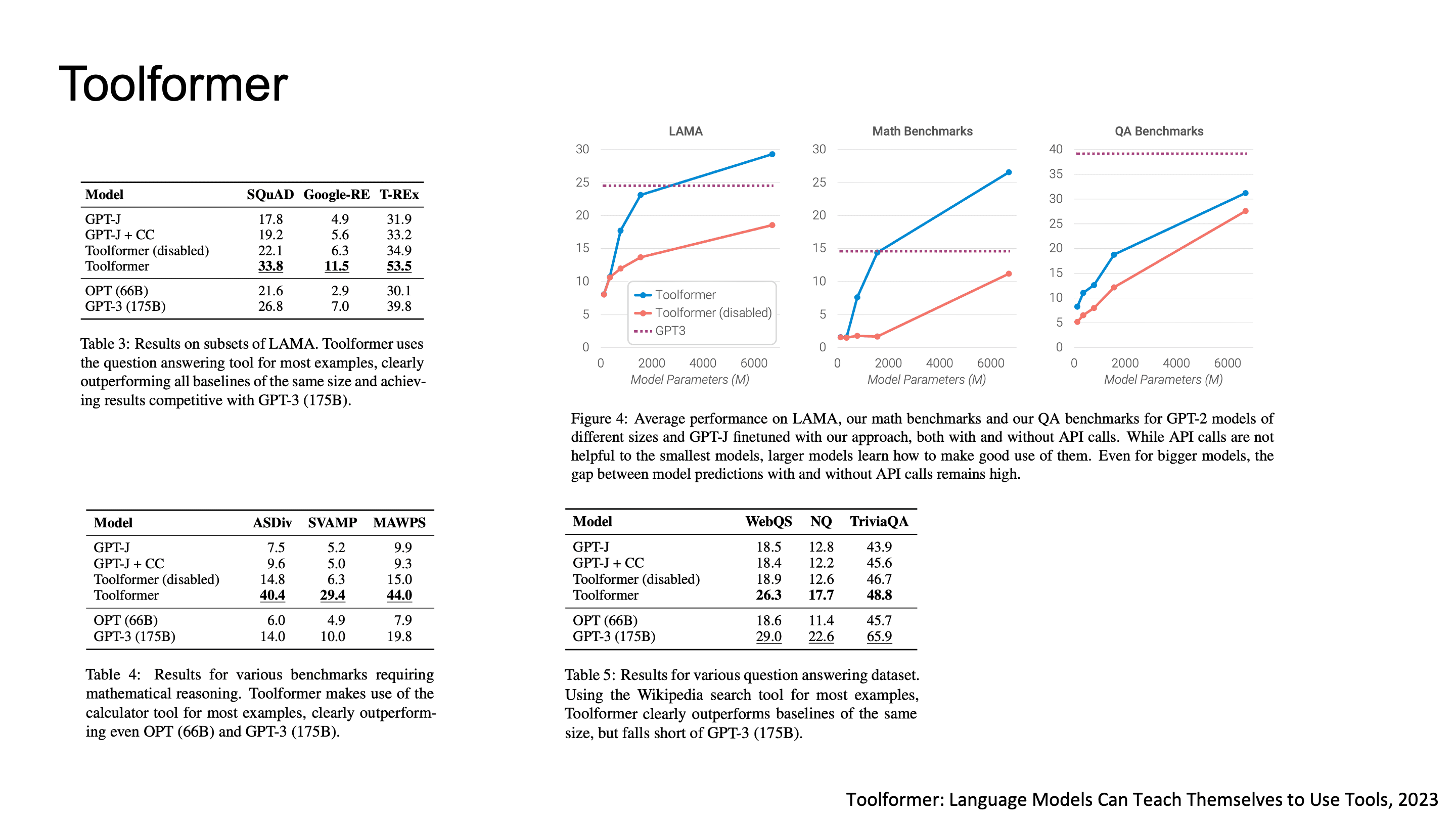
2023년에 나온 Toolformer라는 논문은 모델이 self-supervised 방식으로 API 호출의 위치, 종류, argument를 스스로 학습하도록 만들었습니다.
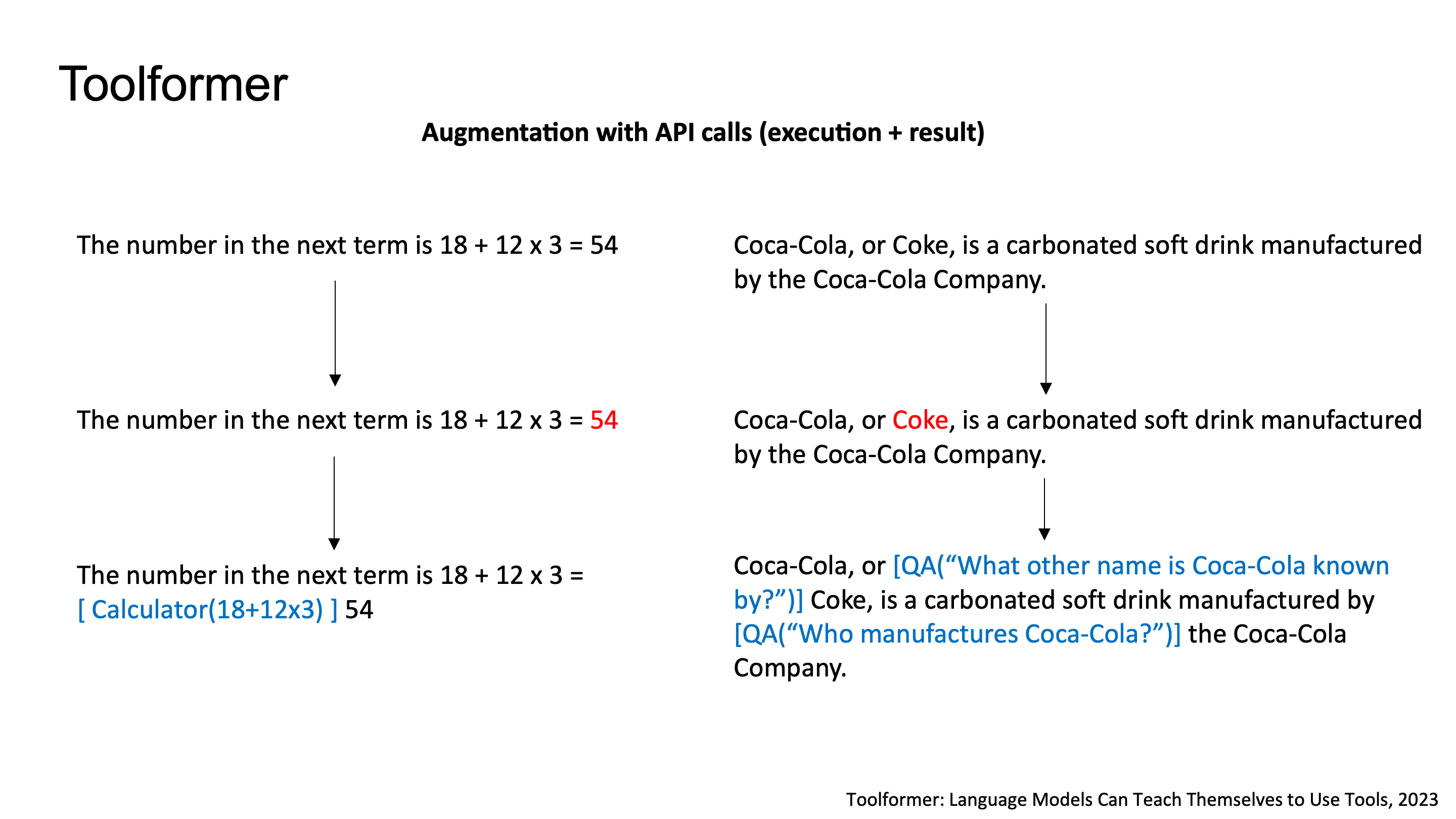
Toolformer의 학습 과정을 자세히 보면 먼저 텍스트 안에서 API call을 삽입할 수 있는 position을 sampling합니다.
예를 들어, "The number in the next term is 18 + 12 x 3 = 54"라는 문장에서 모델이 [Calculator(18+12x3)]을 적절한 position에 삽입하고, "Coca-Cola, or Coke, is a carbonated soft drink..."에서는 [QA("What other name is Coca-Cola known by?")]를 끼워넣는 식이에요.
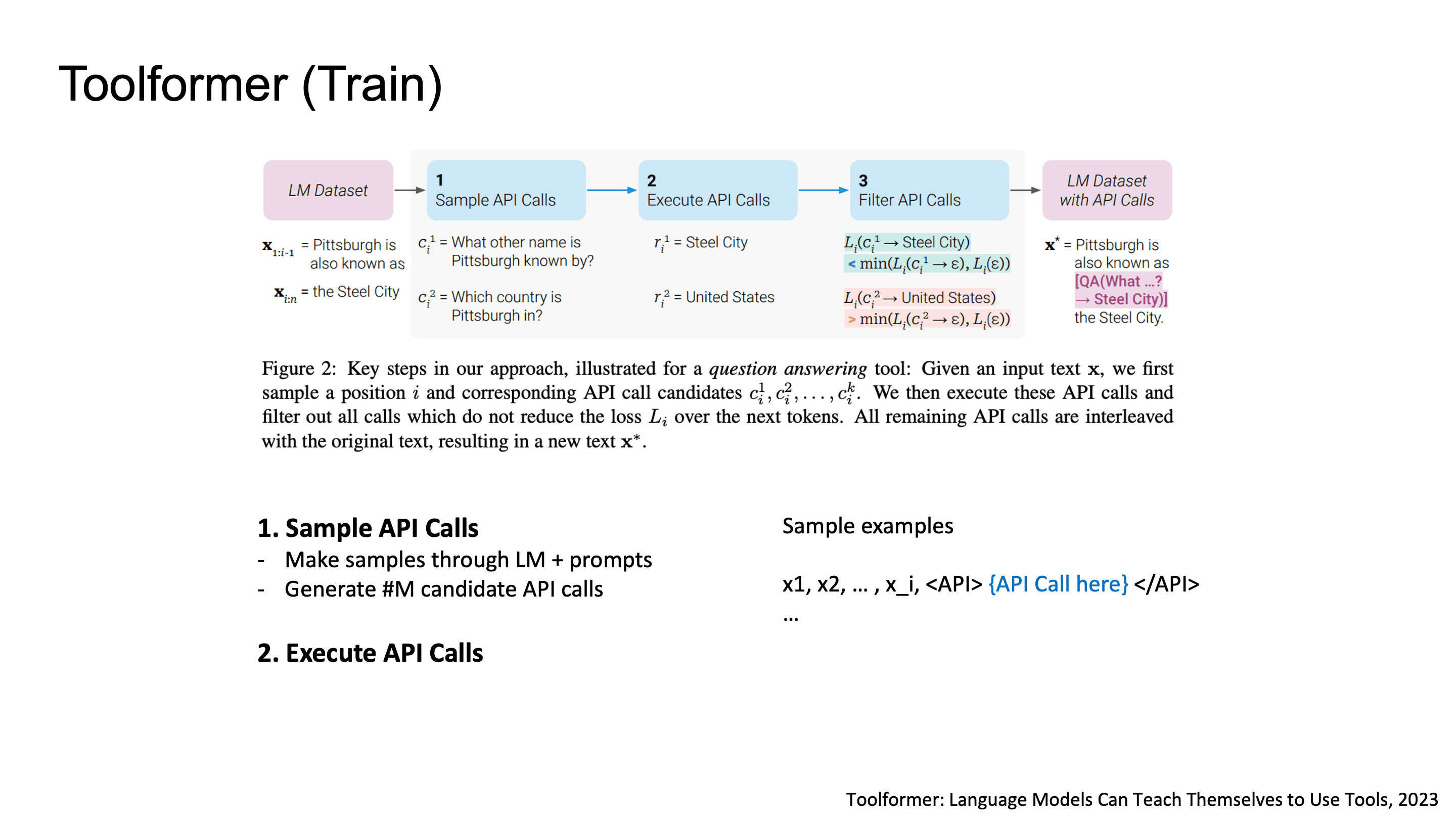
학습 파이프라인의 핵심은 세 단계입니다:
Sample API Calls: LM에 few-shot prompt를 줘서 position i마다 M개의 candidate API call를 생성합니다.
Execute API Calls: 실제로 API를 실행해서 response를 받아옵니다.
Filter API Calls: 학습 데이터를 만들기 전에 유용한 데이터만 필터링 하는 단계입니다. API 호출이 next token prediction에 실제로 유용한지를 cross-entropy loss로 검증합니다. API를 호출하지 않았거나 API response 값이 없을 경우의 loss와 API response를 넣었을 때의 loss를 비교해서, 차이가 τ 이상 날때만 학습 데이터에 포함시켜요. 즉, 유의미한 API response인 경우만 필터링해서 남긴다고 보면 됩니다.
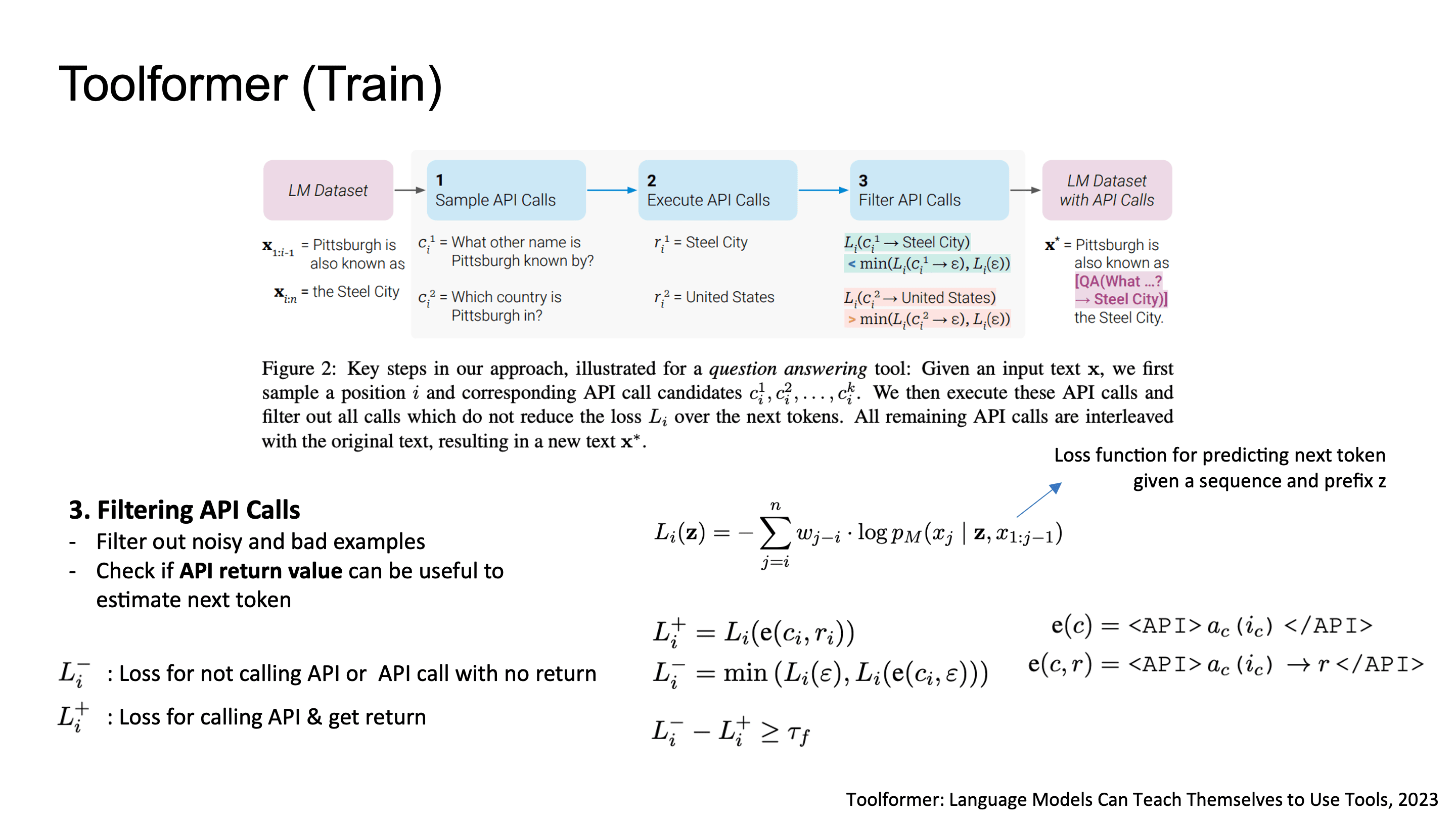
이렇게 filtering된 결과와 기존 dataset으로 augment된 dataset으로 GPT-J를 fine-tuning하고, inference 시에는 decoding 중 special token "->"이 나타나면 API를 호출하고 결과를 태그로 감싸서 context에 append하는 방식으로 동작합니다.

ToolLLM: 16,000+ Real-world API Scaling
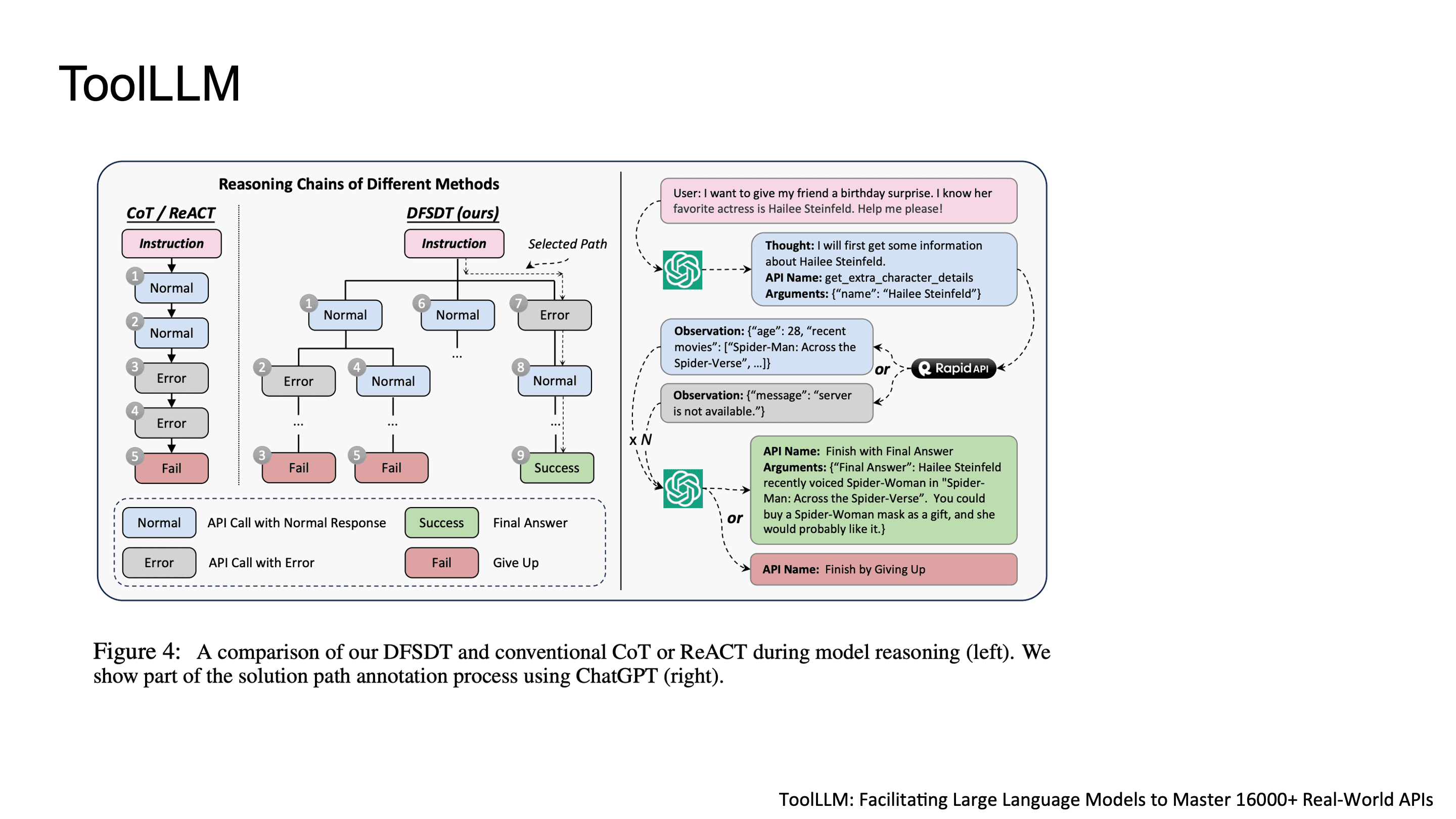
Toolformer가 일부 API로만 학습을 했다면, ToolLLM은 이걸 real-world scale로 끌어올린 연구입니다. RapidAPI Hub에서 16,000개 이상의 REST API를 수집하고, 이를 다룰 수 있는 instruction-tuned LLM을 만들었습니다. API Call이 성공한 결과를 받을 때까지 병렬적으로 API를 호출합니다.
Part 2: RL 기반 Tool Ability
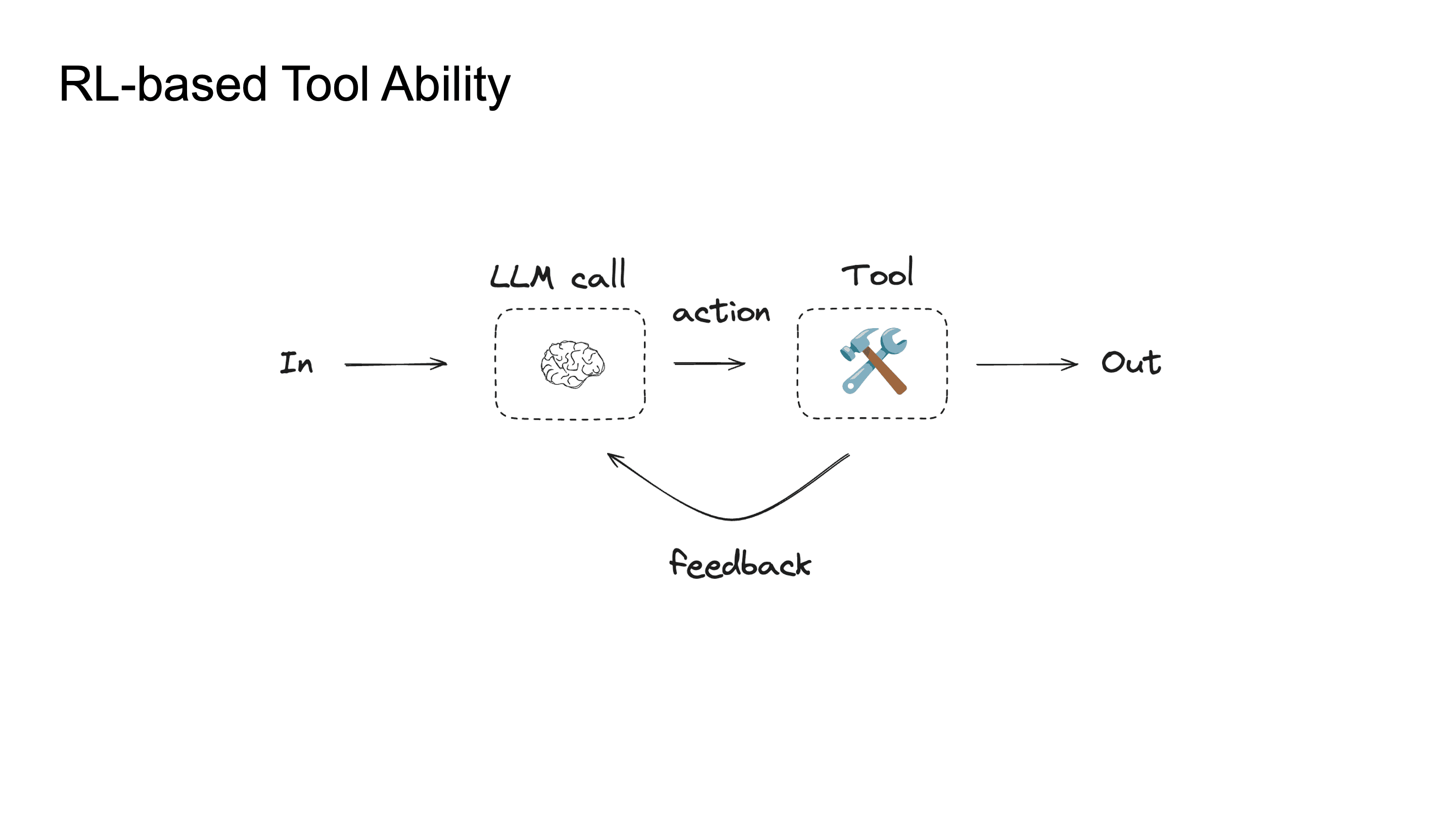
Tool ability를 더 끌어올리기 위해서 강화학습을 사용할 수도 있습니다. Tool-use의 경우 tool execution result가 자연스러운 reward signal이 됩니다. 코드를 실행하면 정답이 나오거나 에러가 나고, 검색하면 relevant document가 나오거나 garbage가 나오니까요. 이걸 RL의 reward로 활용하면, SFT의 distribution shift 문제를 넘어서 on-policy에서 optimal tool-use strategy를 학습할 수 있습니다.
ReTool: PPO를 활용한 Tool-augmented Reasoning
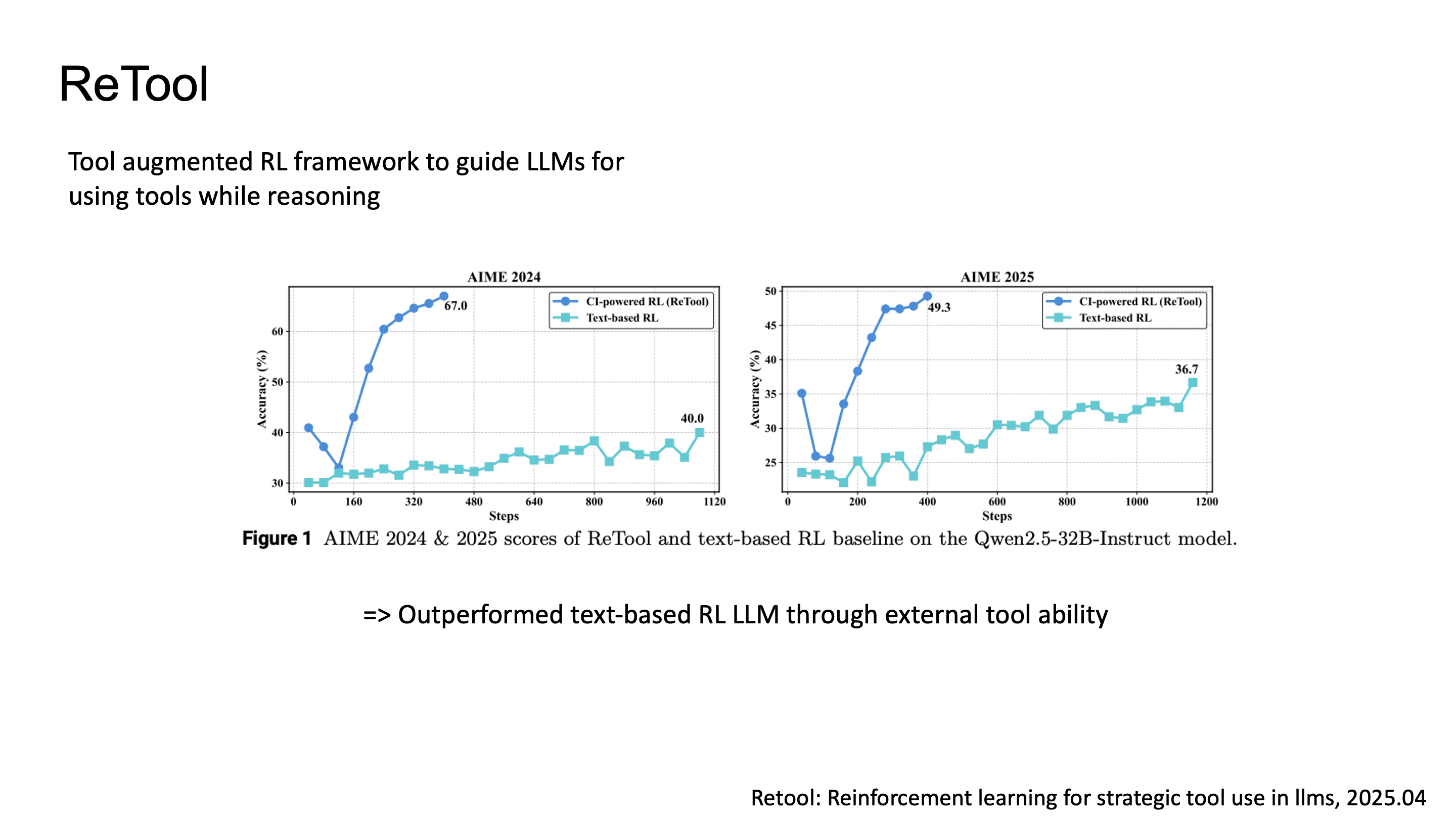
ReTool은 tool-integrated reasoning을 RL로 학습시키는 framework입니다.
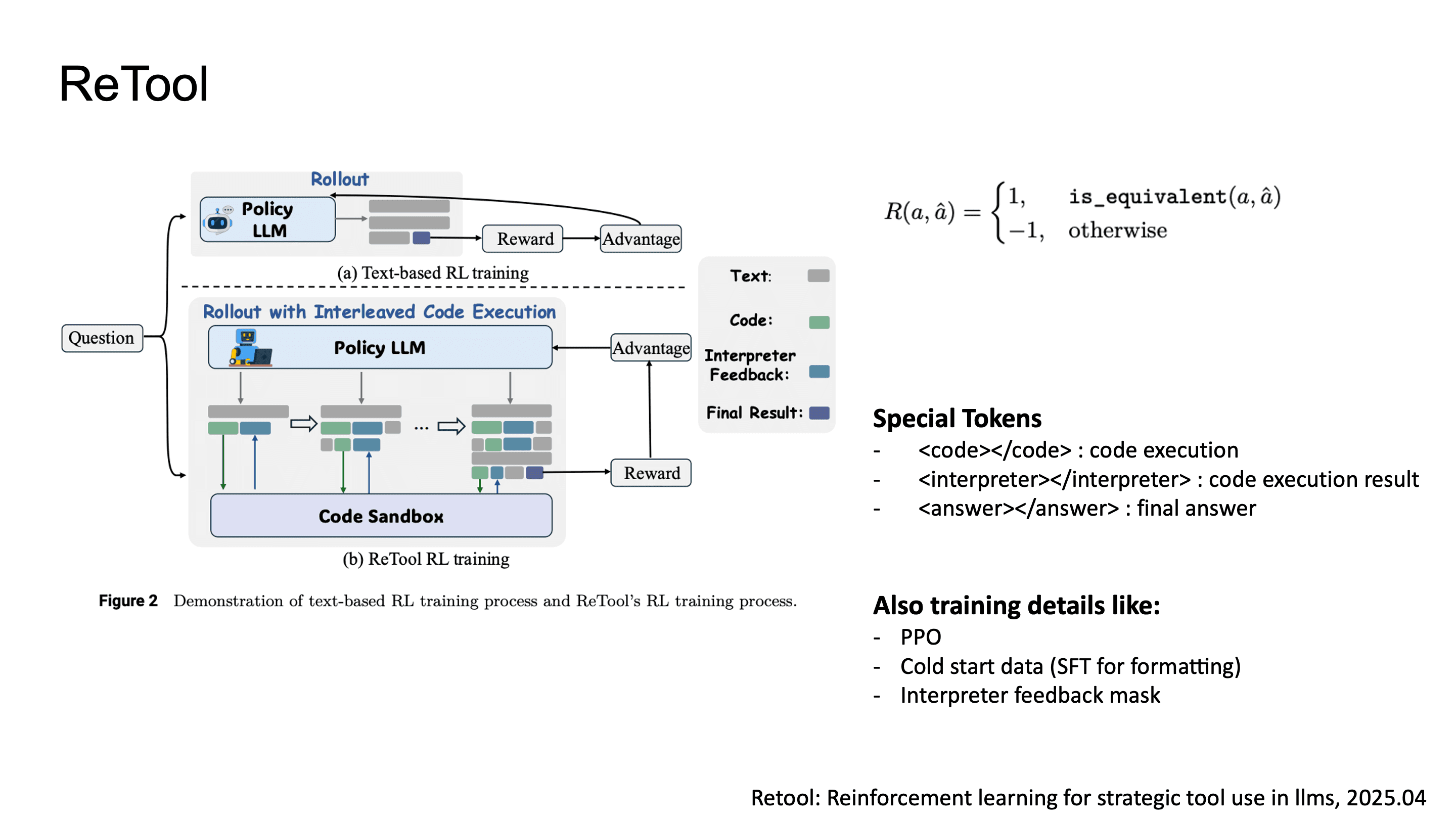
ReTool에서 제안한 방식은 토큰으로 Python code execution을 감싸고, 로 execution output을 받으며, 로 final answer를 표시하는 것입니다.
학습 파이프라인은 두 phase인데, 먼저 cold start SFT로 format compliance를 확보한 뒤, PPO로 policy optimization을 수행합니다. 이 과정에서 interpreter output token에 대한 gradient masking을 진행해서 모델이 생성하지 않은 environment feedback에 대해서는 loss 계산을 하지 않습니다.
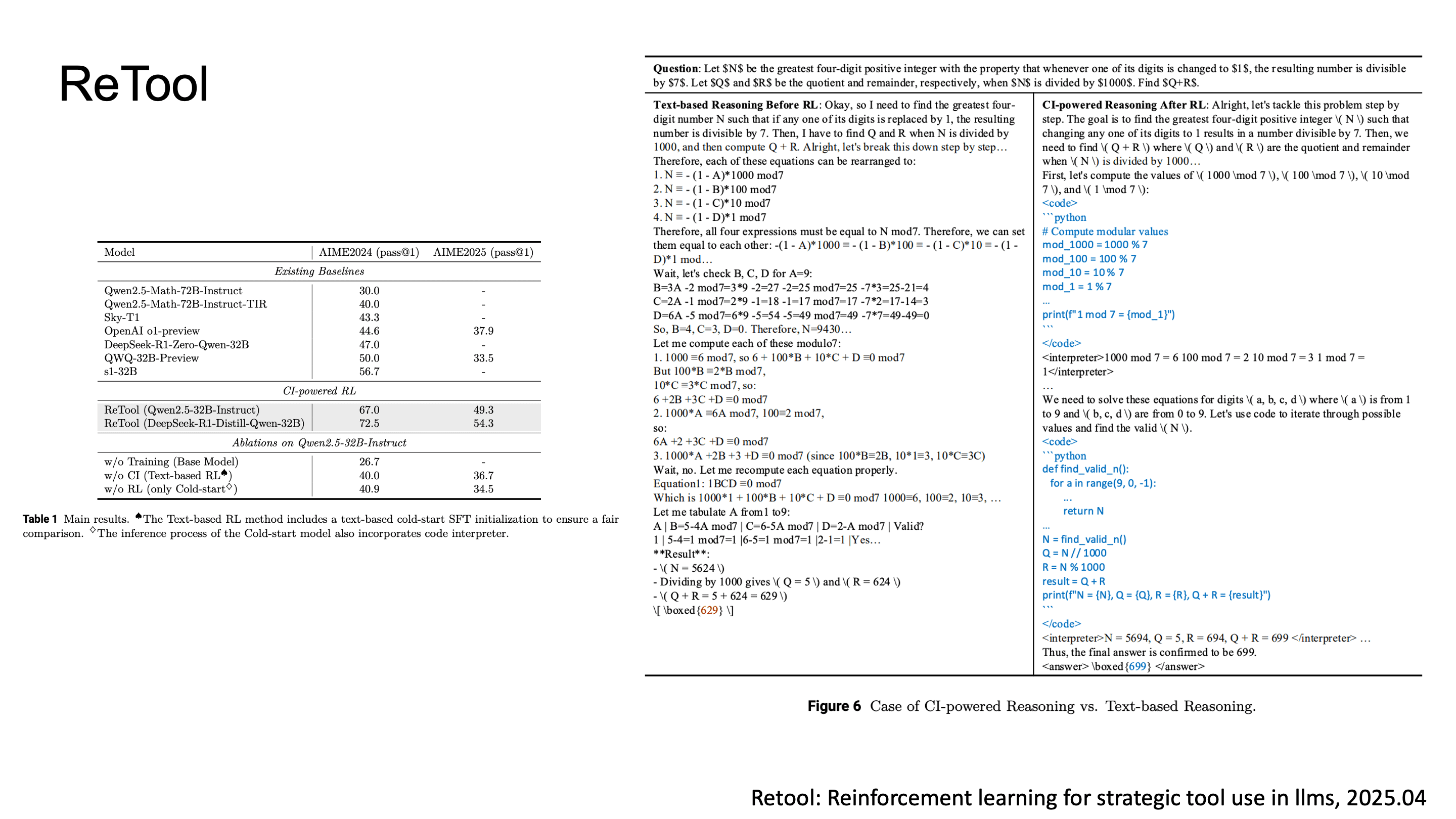
결과적으로 ReTool은 text-only RL baseline 대비 높은 성능을 보여줬고, 특히 수학 문제에서 code execution을 통한 verification이 reasoning accuracy를 크게 끌어올렸습니다.
Search-R1: Search Engine as a Differentiable Tool
기존에 external knowledge를 활용하려면 RAG pipeline을 별도로 구축해야 했는데, 이를 위해서는 pre-built index에 의존하고, embedding model의 성능에 RAG의 정확도가 좌지우지 되는 등의 한계가 있습니다.
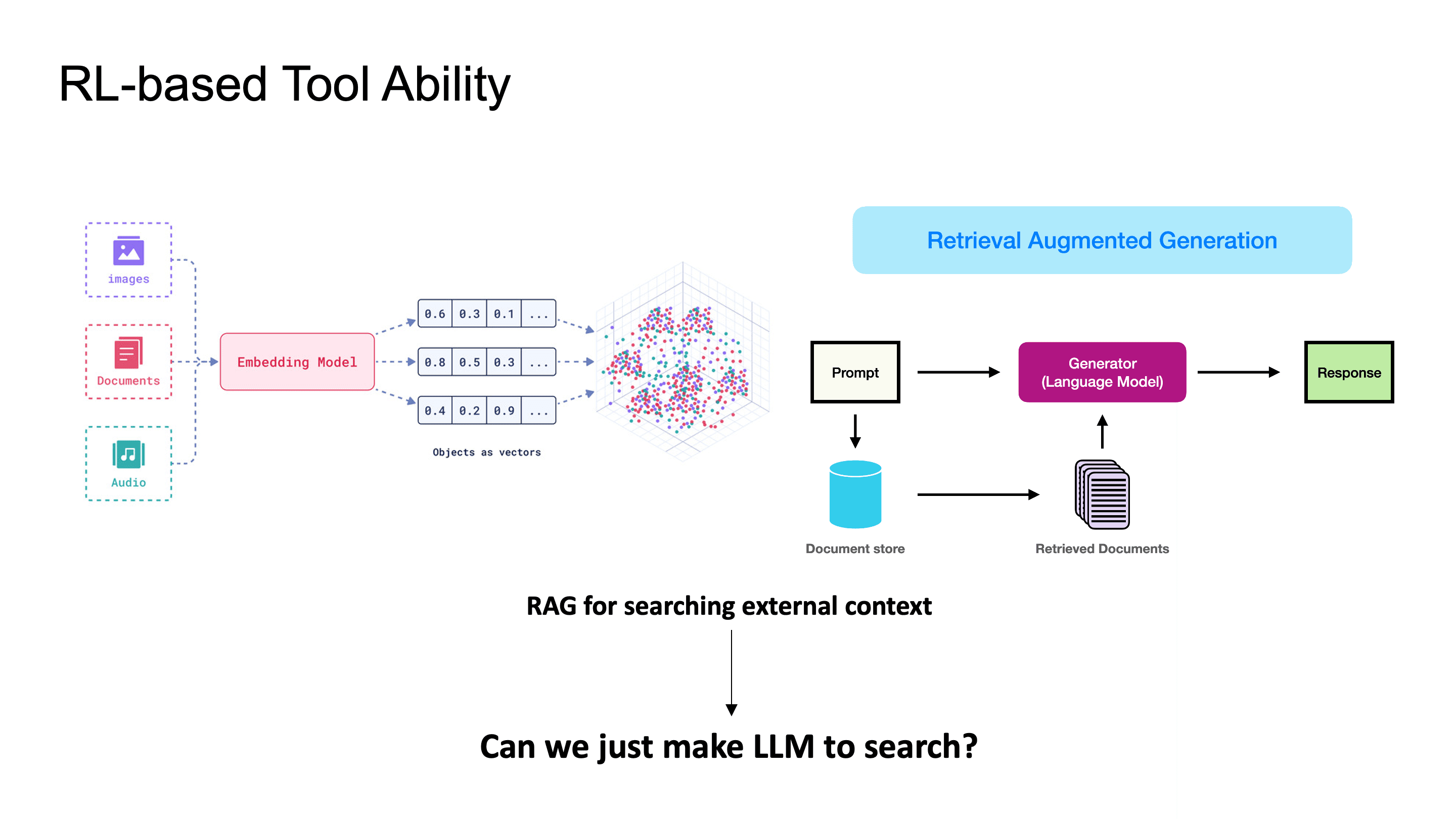
Search-R1 논문은 LLM이 직접 search query를 생성하고, search engine을 tool로 호출하는 전체 과정을 end-to-end RL로 학습시키는 방법을 제안했습니다.

Search-R1의 token은 (reasoning),
(search query generation), (retrieved document injection), (final answer)으로 구성됩니다.
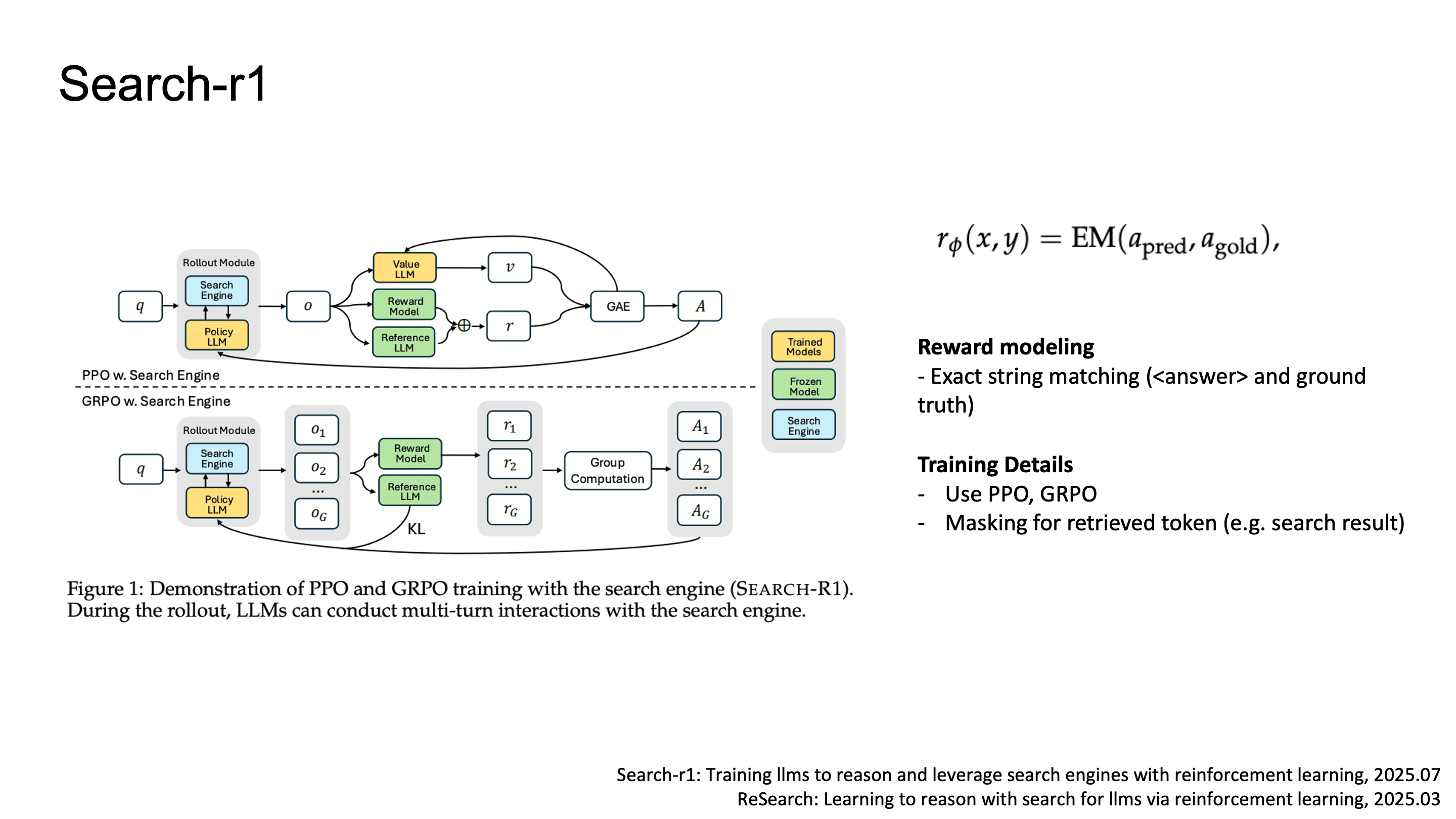
reward design은 단순한데, token 내의 텍스트와 ground truth 간의 exact string matching만 사용했습니다.
optimizer는 PPO와 GRPO 둘 다 실험했고, ReTool과 마찬가지로 내의 retrieved document token에 대해서는 gradient masking을 적용했습니다.
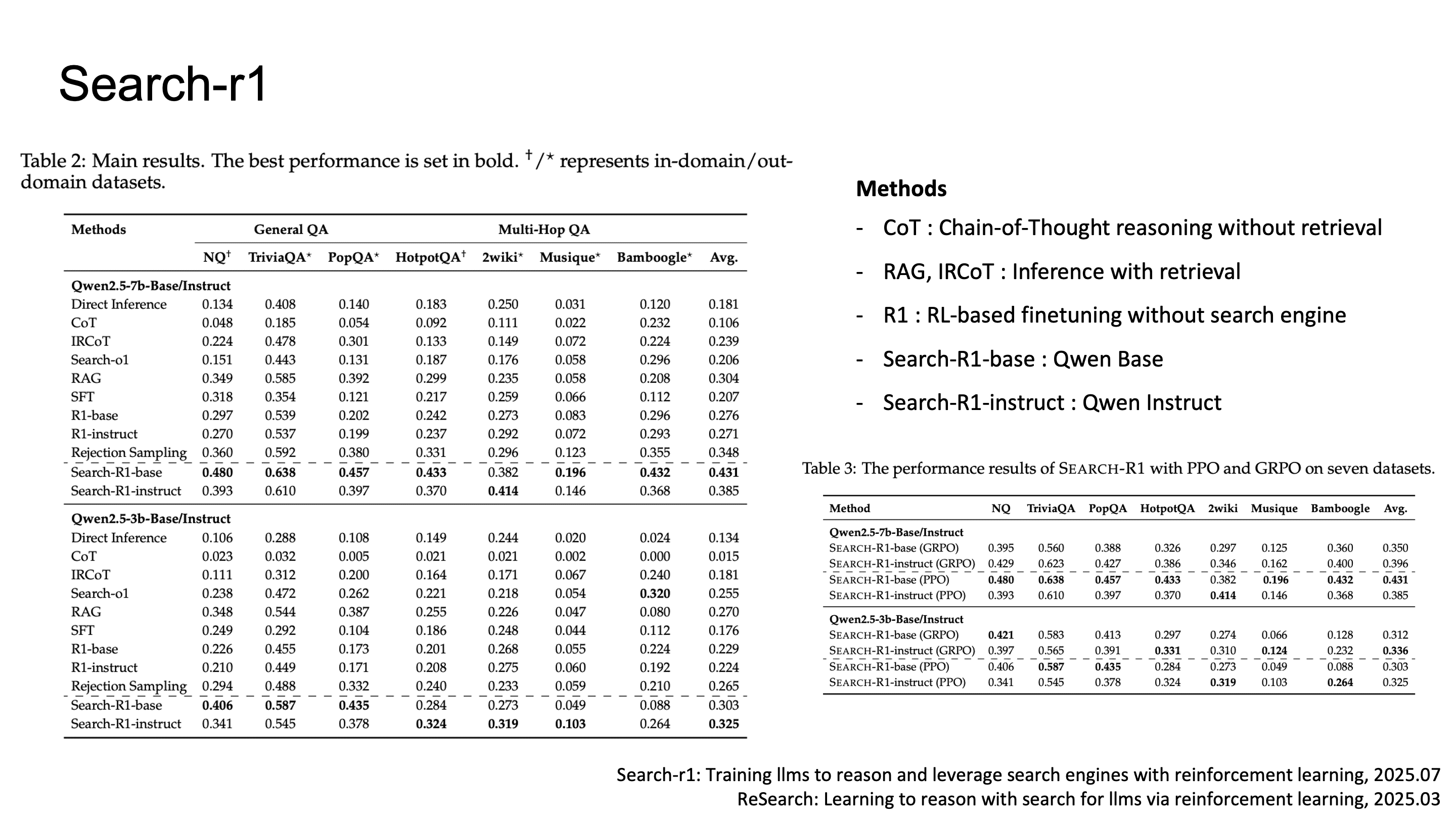
실험 결과를 보면, Search-R1은 CoT (no retrieval), RAG (static retrieval), IRCoT (interleaved retrieval + CoT), R1 (RL without retrieval) 등을 모든 benchmark에서 좋은 성능을 보였습니다.

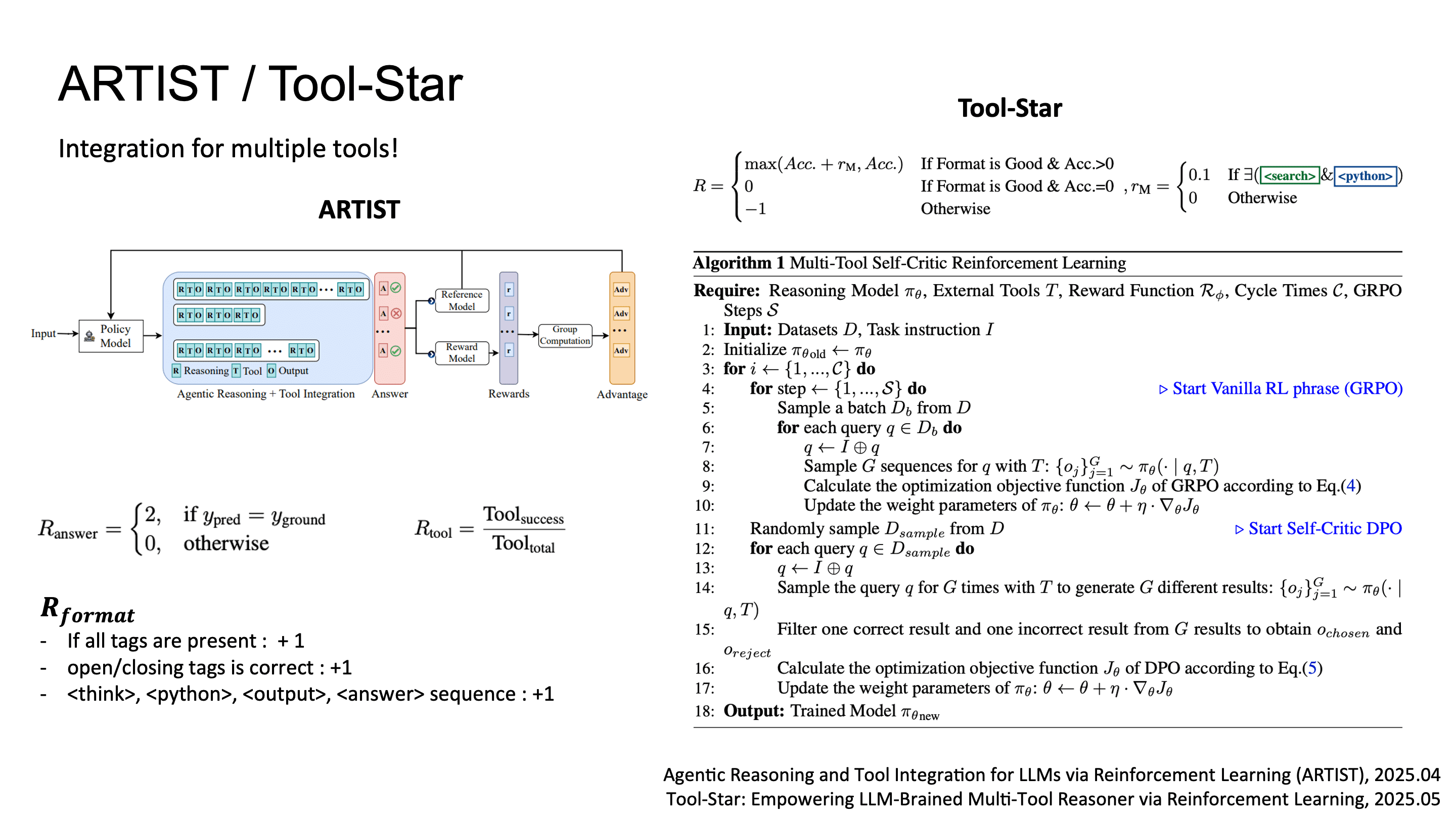
ARTIST & Tool-Star: Multi-tool Integration via RL
ARTIST와 Tool-Star와 같은 연구에서는 single-tool이 아닌 여러개의 tool 사용 사례를 위해 search, calculator, code interpreter 등 heterogeneous tool set을 RL로 joint optimization하는 framework를 제시했습니다.
Tool-use 평가: MCP-RADAR
LLM이 tool-use ability가 생김에 따라 systematic evaluation의 필요성도 커졌습니다.
MCP-RADAR는 기존 benchmark들이 단순 accuracy만 봤던 한계를 넘어서, multi-dimensional evaluation을 제안한 벤치마크입니다.
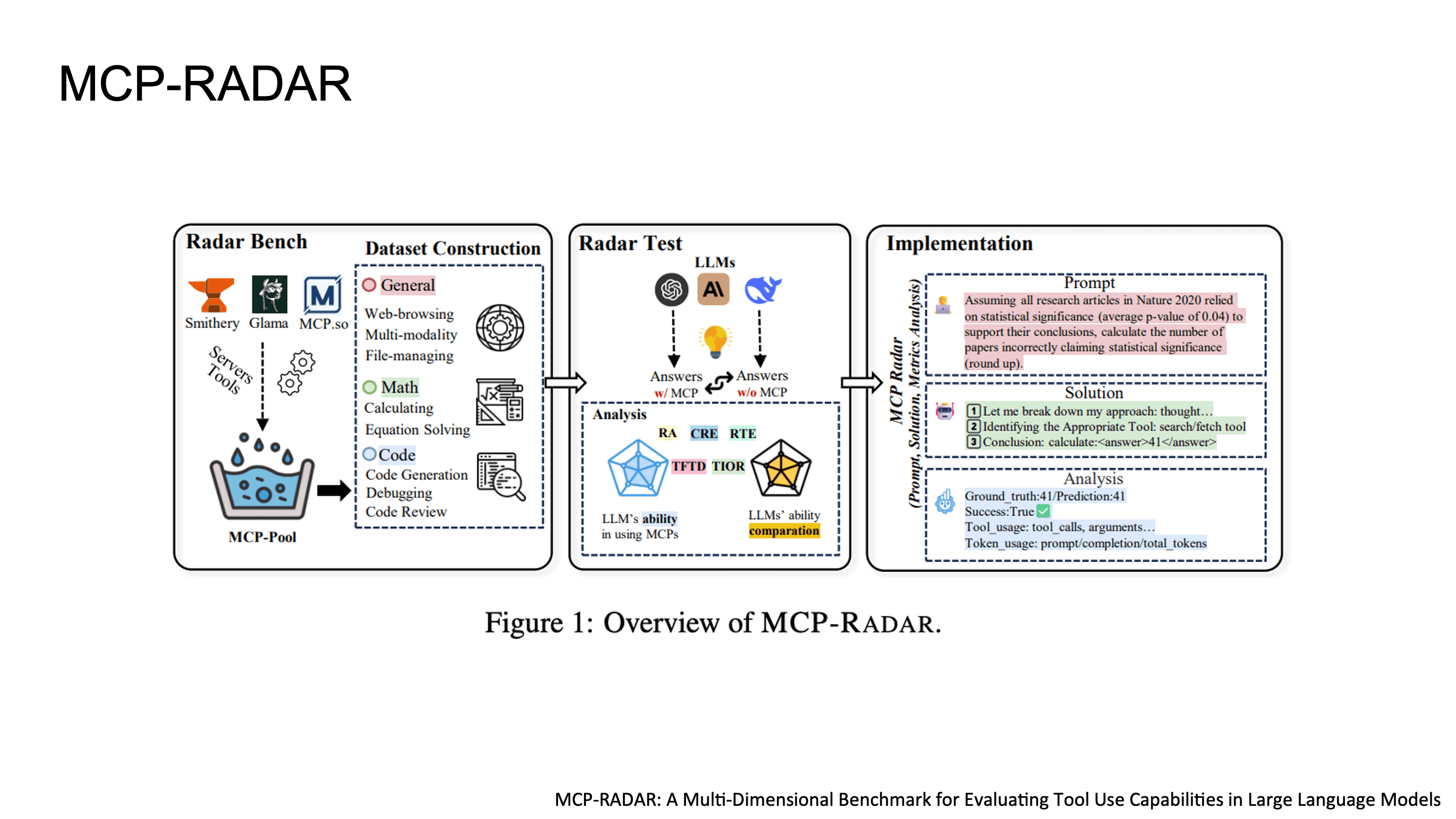

MCP-RADAR의 다섯 가지 metric은 다음과 같습니다.
RA (Result Accuracy): end-to-end task completion 성공률
DTSR (Detailed Tool-use Success Rate): 각 individual tool call의 correctness. call-level granularity로 어디가 잘못됐는지 추적 가능
FEP (First Error Position): multi-step workflow에서 첫 번째 error가 발생하는 position. error propagation 분석에 유용
CRE (Computational Resource Efficiency): token consumption 기반의 resource efficiency. 같은 정답이라도 토큰을 덜 쓰면 높은 점수
RTE (Response Time Efficiency): input부터 final response까지의 latency efficiency
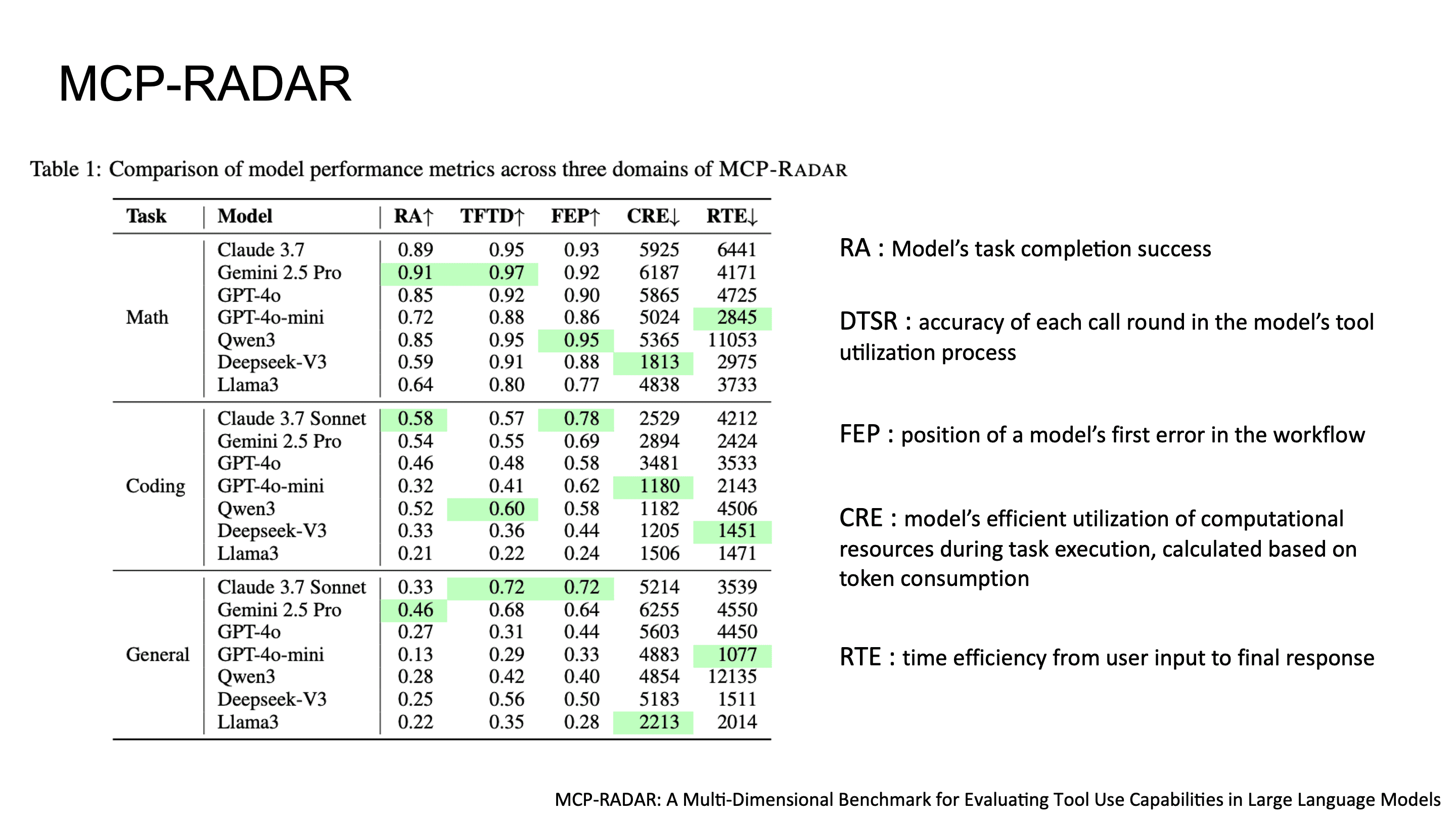
accuracy뿐 아니라 token efficiency와 tool call이 실패한 경우까지 평가하는 점에서, real-world deployment를 고려한 practical한 benchmark라고 볼 수 있습니다.
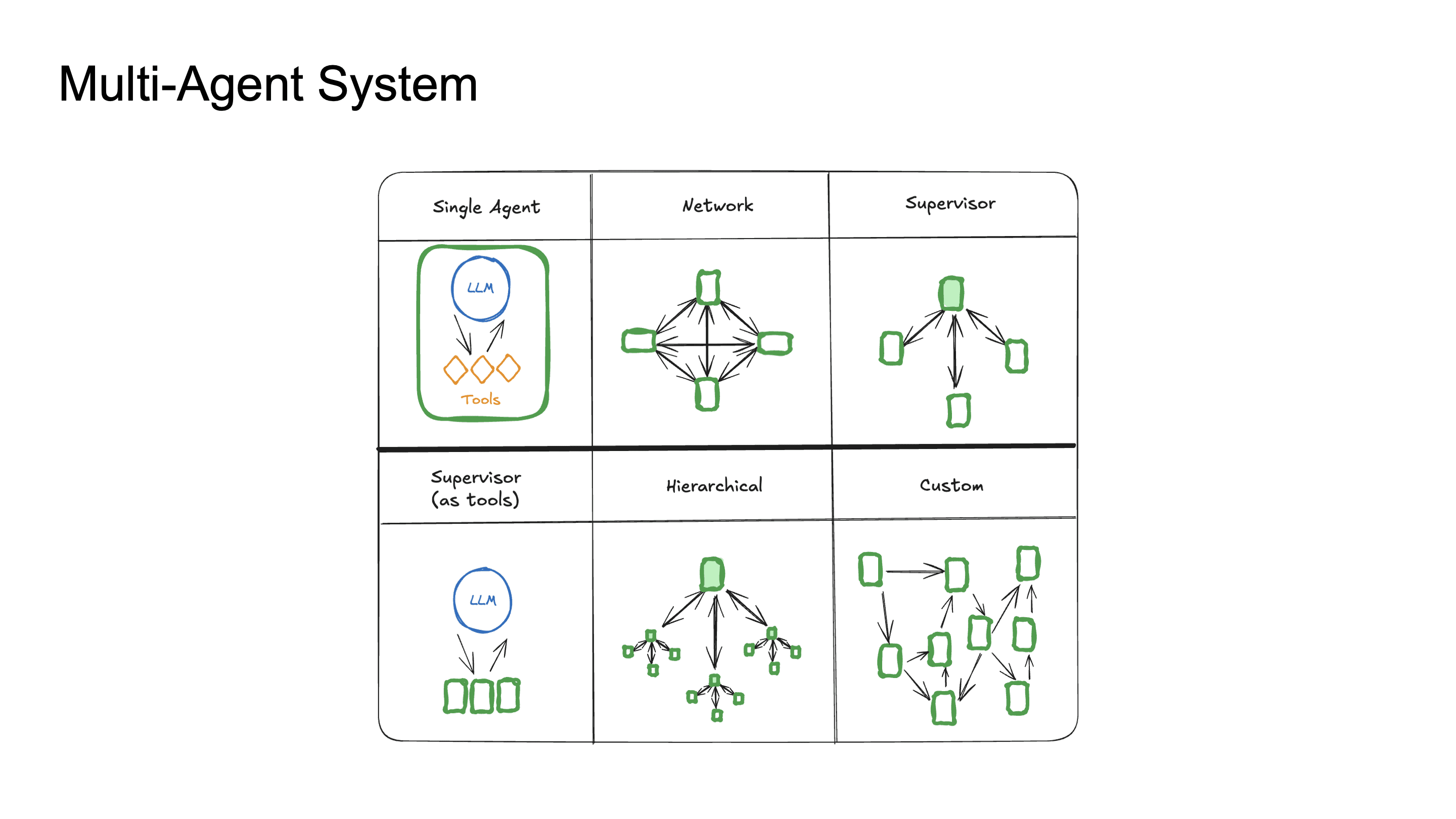
Part 3: Multi-Agent System, Tool-using Agent Orchestration
이후 tool-capable LLM이 만들어지고, 여러 agent들의 orchestration에 많은 사람들이 관심을 가지게 되었습니다. single agent의 context window 한계, task decomposition의 필요성, 그리고 specialization을 통한 성능 향상을 위해 MAS가 연구되었습니다.
Anthropic의 Multi-Agent Research System
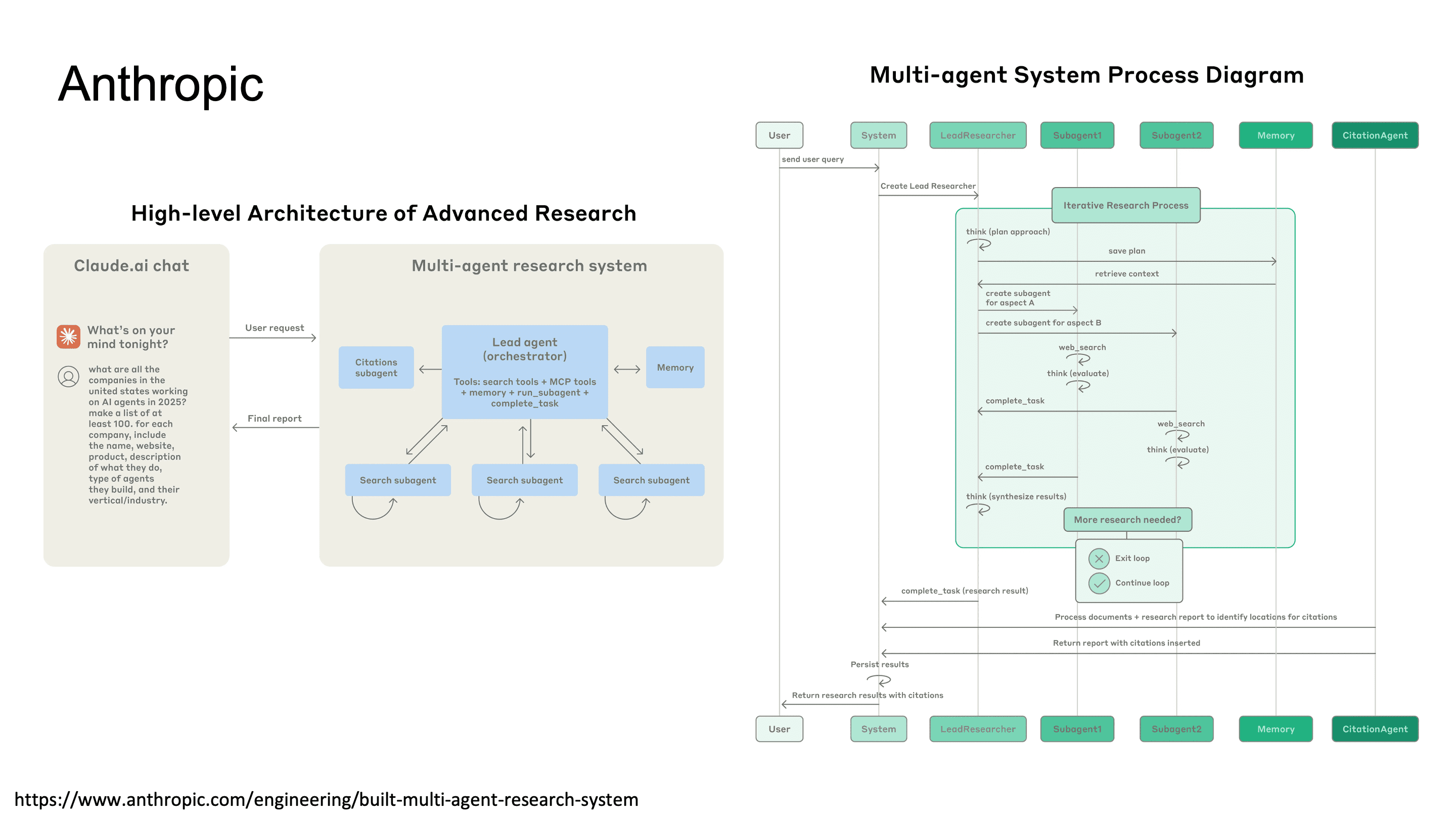
Anthropic은 자체 multi-agent research system 구축 경험을 공개했는데요. 재밌는것은 Anthropic이 task decomposition strategy, agent 간 communication protocol, result aggregation 방식 등을 실용적 관점에서 정리했습니다. 특히 agent에게 충분한 autonomy를 줘야 하지만, hallucination을 catch할 수 있는 verification loop가 중요하다고 합니다.

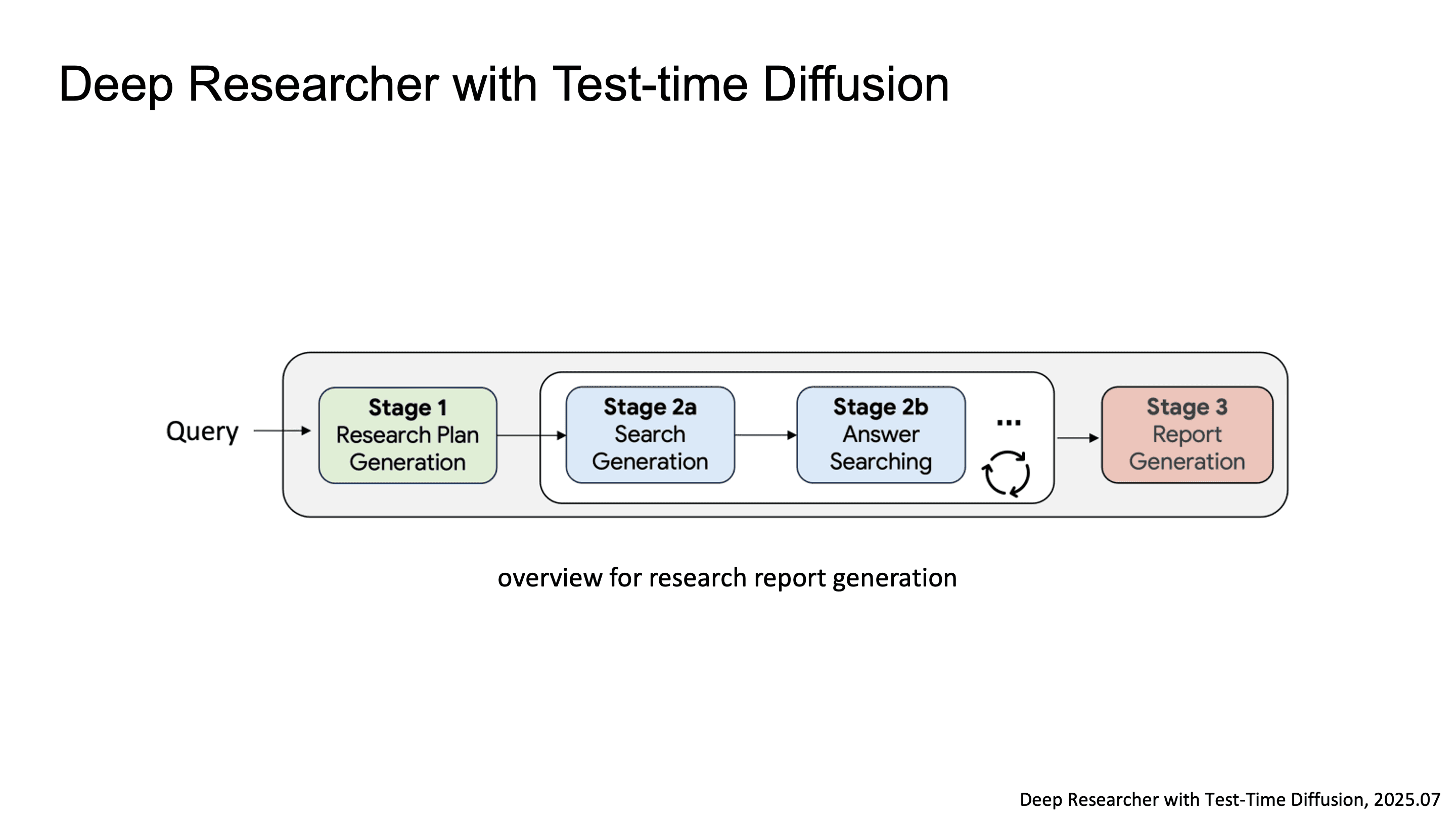
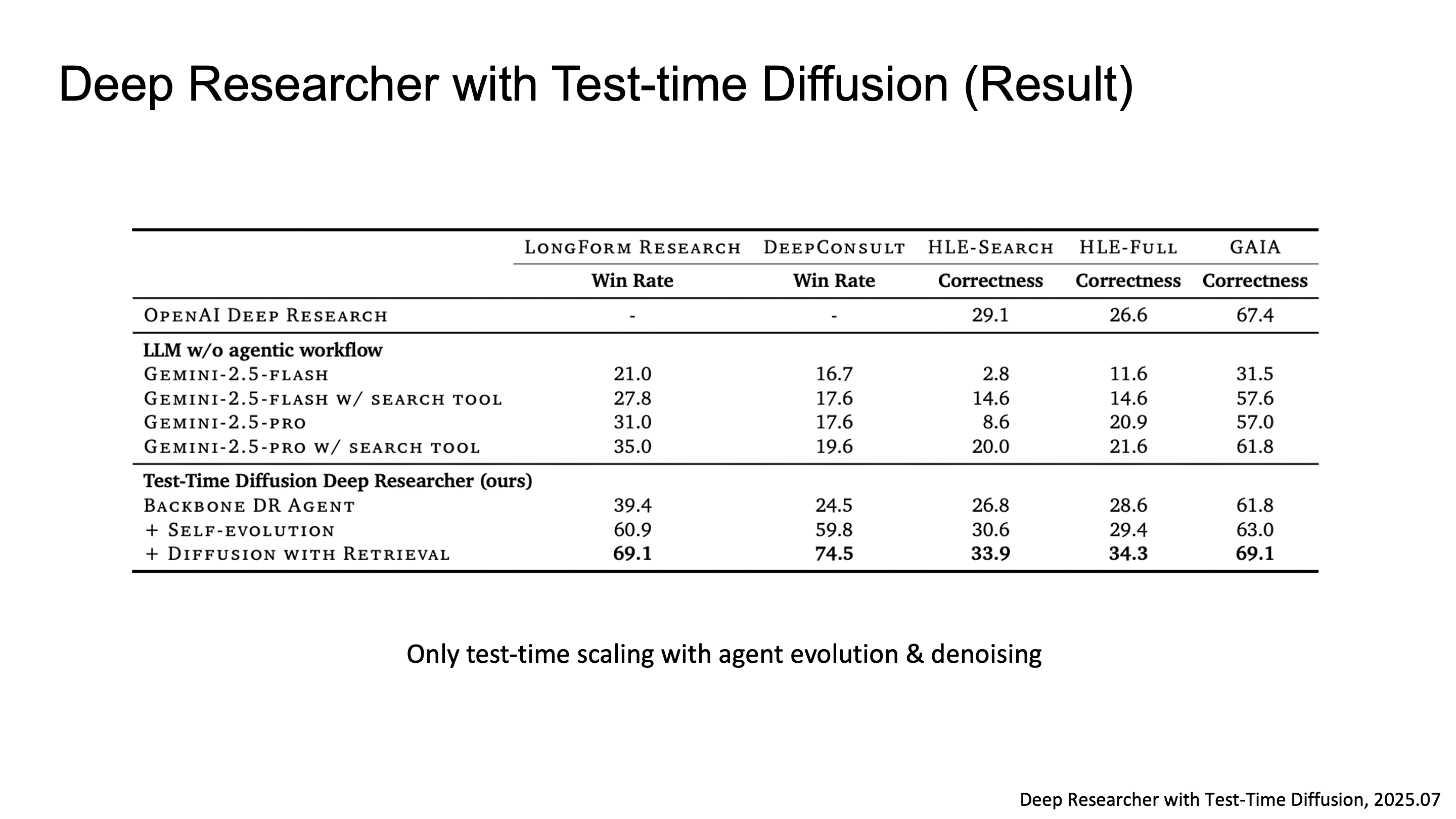
Deep Researcher with Test-time Diffusion
Google에서는 Deep Researcher with Test-time Diffusion 논문을 통해서 LLM이 human researcher 수준의 복잡한 long-form research report를 생성할 수 있는가를 연구한 결과를 발표했습니다.
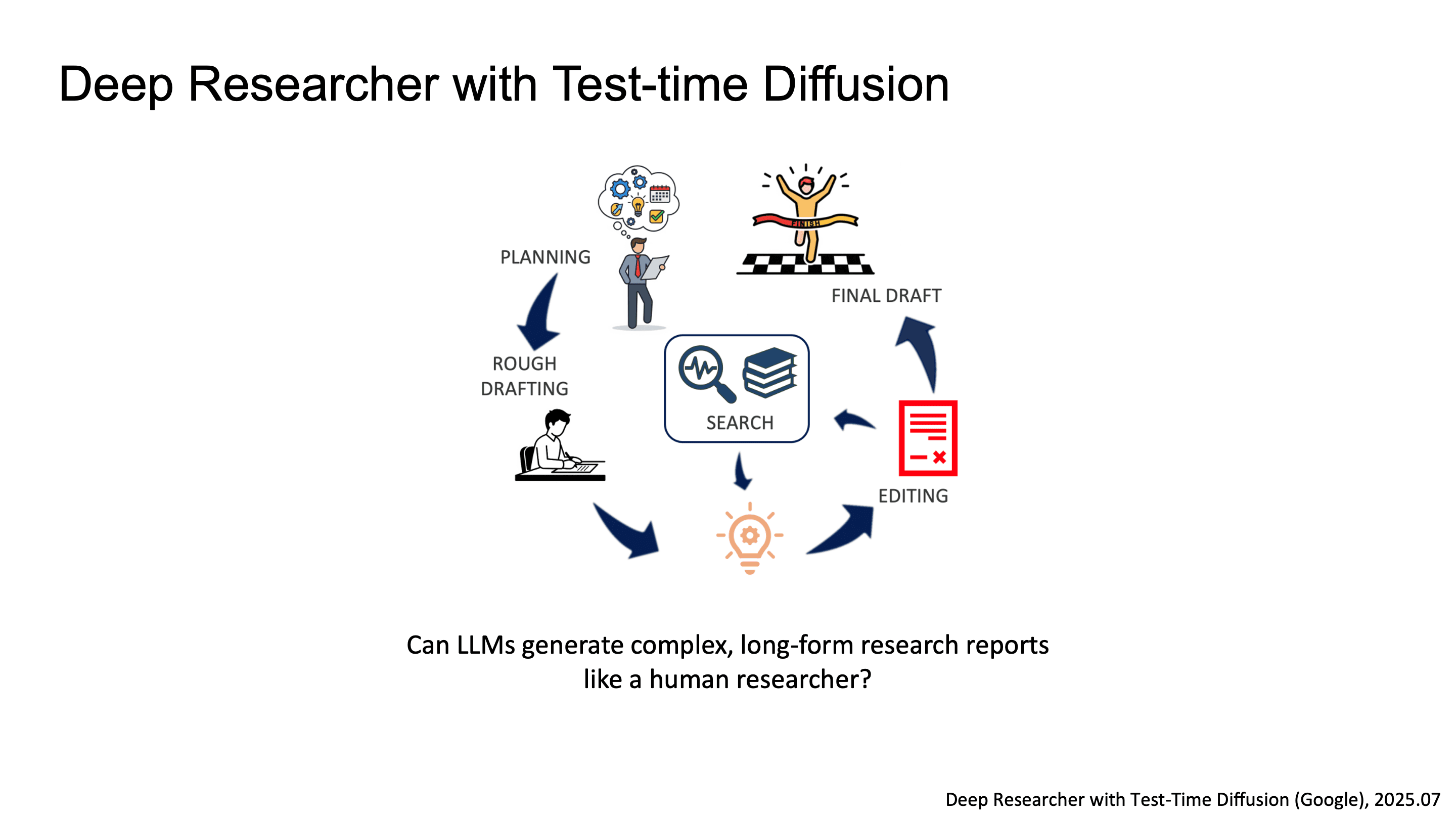
전체 파이프라인은 research report 생성을 위한 여러 component로 구성되는데, 핵심 메커니즘은 두 가지입니다.
첫 번째는 Component-wise Self-Evolution이에요. plan, search query, final report 각각에 대해 LLM-as-judge가 Helpfulness, Comprehensiveness, Factuality 같은 multi-dimensional fitness score를 매기고, evolutionary algorithm으로 더 높은 fitness를 향해 iterative refinement를 수행합니다.
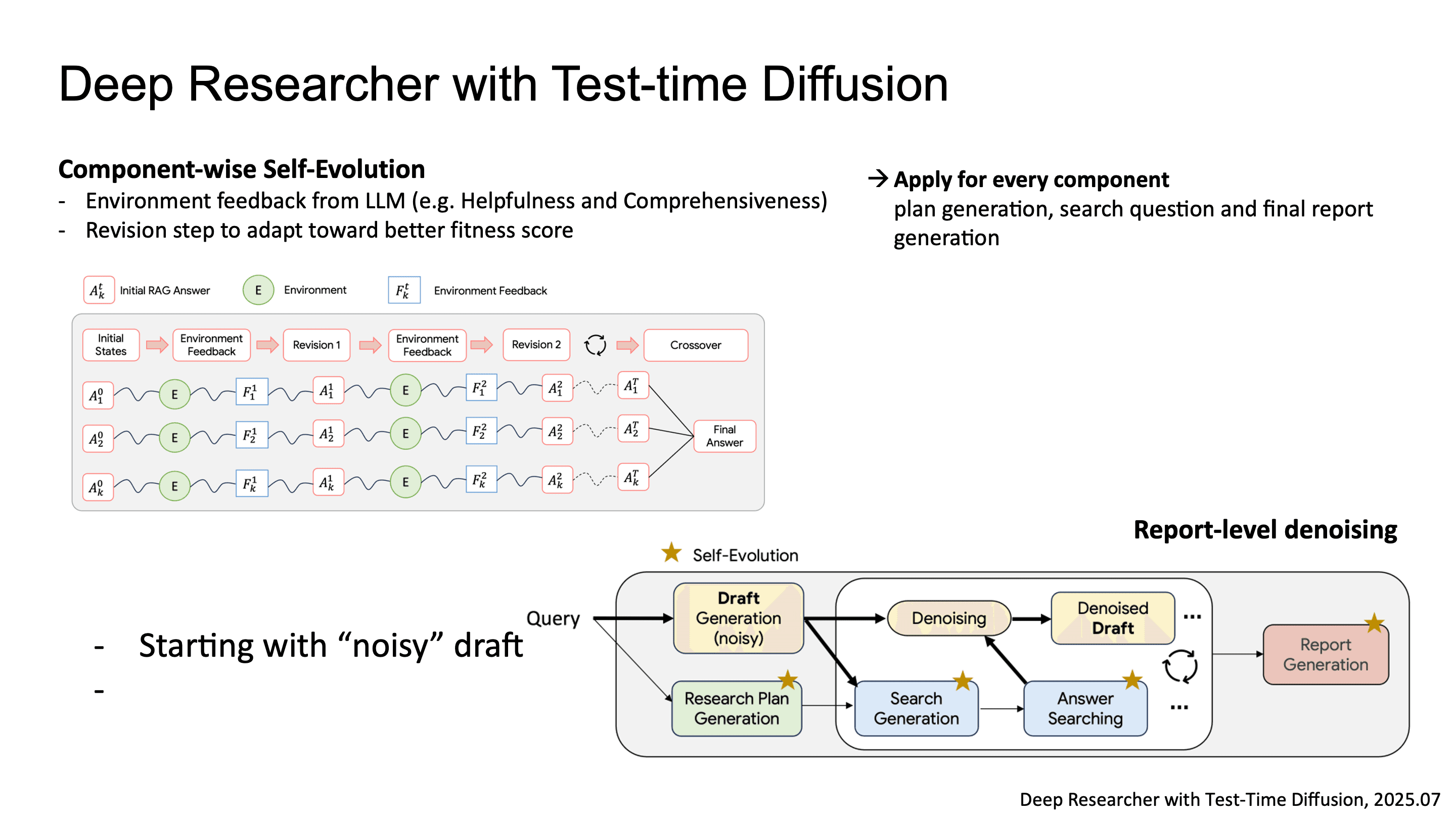
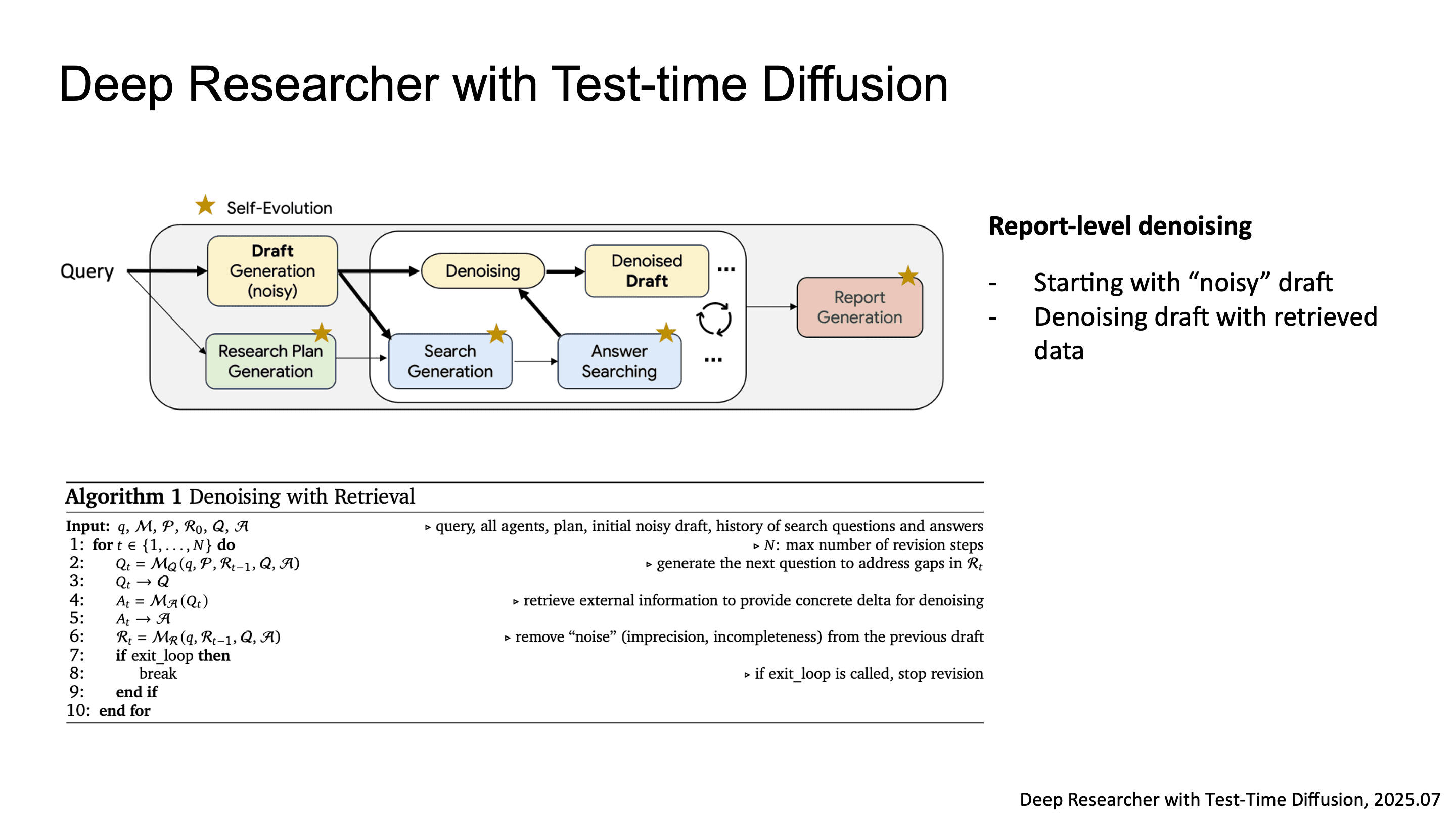
두 번째는 Report-level Denoising입니다. diffusion model의 denoising process를 report generation에 차용한 건데, random noise로 초기화된 noisy draft에서 시작해서, search-retrieved evidence를 conditioning signal로 삼아 iterative denoising step을 거치며 보고서를 정제합니다.

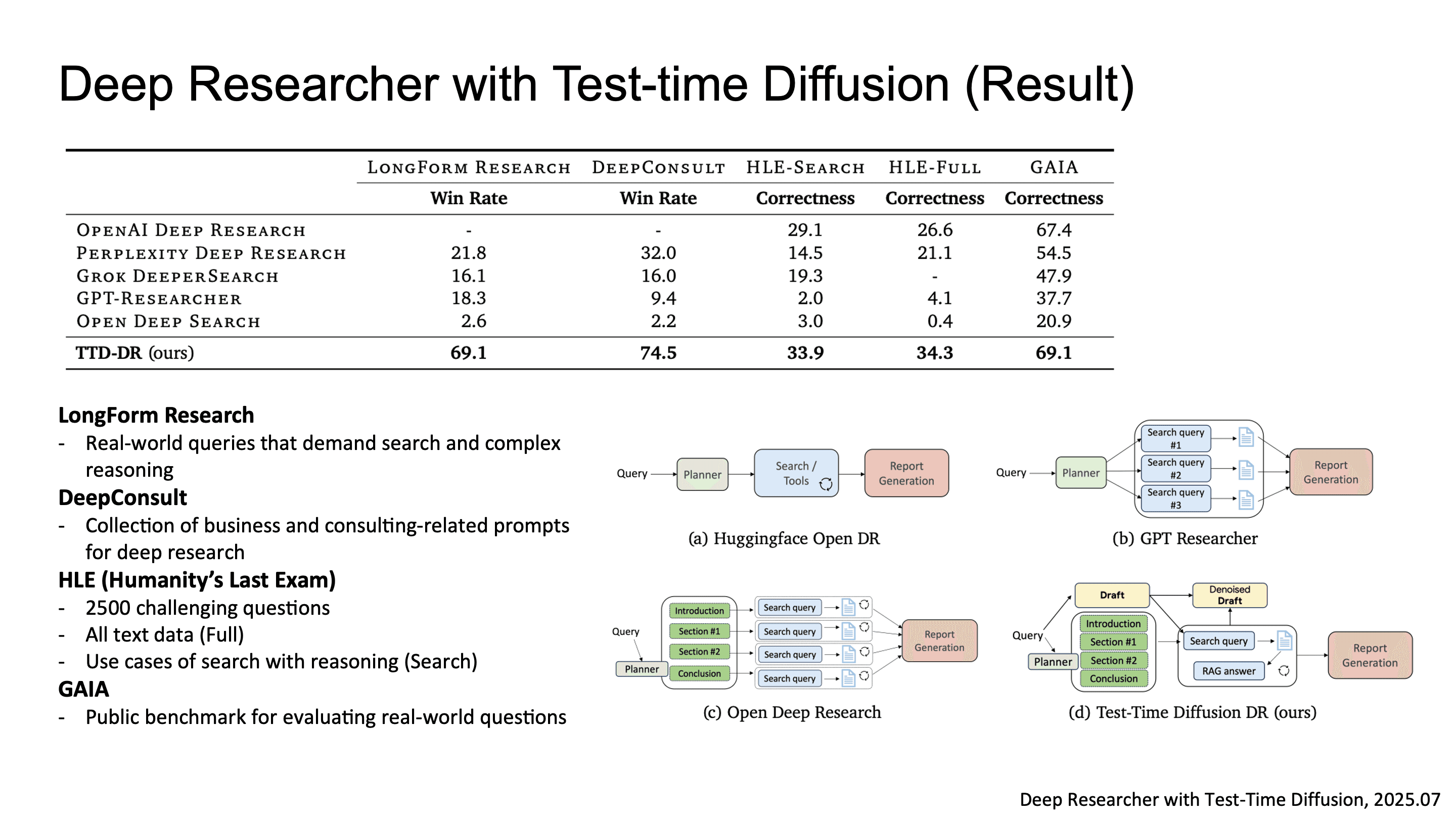
결과를 보면, LongForm Research, DeepConsult, HLE, GAIA 벤치마크에서 baseline들을 넘었습니다.
주목할 점은, 별도의 training 없이 pure test-time scaling, 즉 agent evolution과 denoising iteration만으로 이 성능을 달성했다는 겁니다.
AlphaEvolve: Evolutionary Coding Agent for Scientific Discovery

마지막으로 Google DeepMind의 AlphaEvolve입니다. AlphaEvolve는 algorithmic discovery를 위한 coding agent로, LLM과 evolutionary search를 결합한 구조입니다.
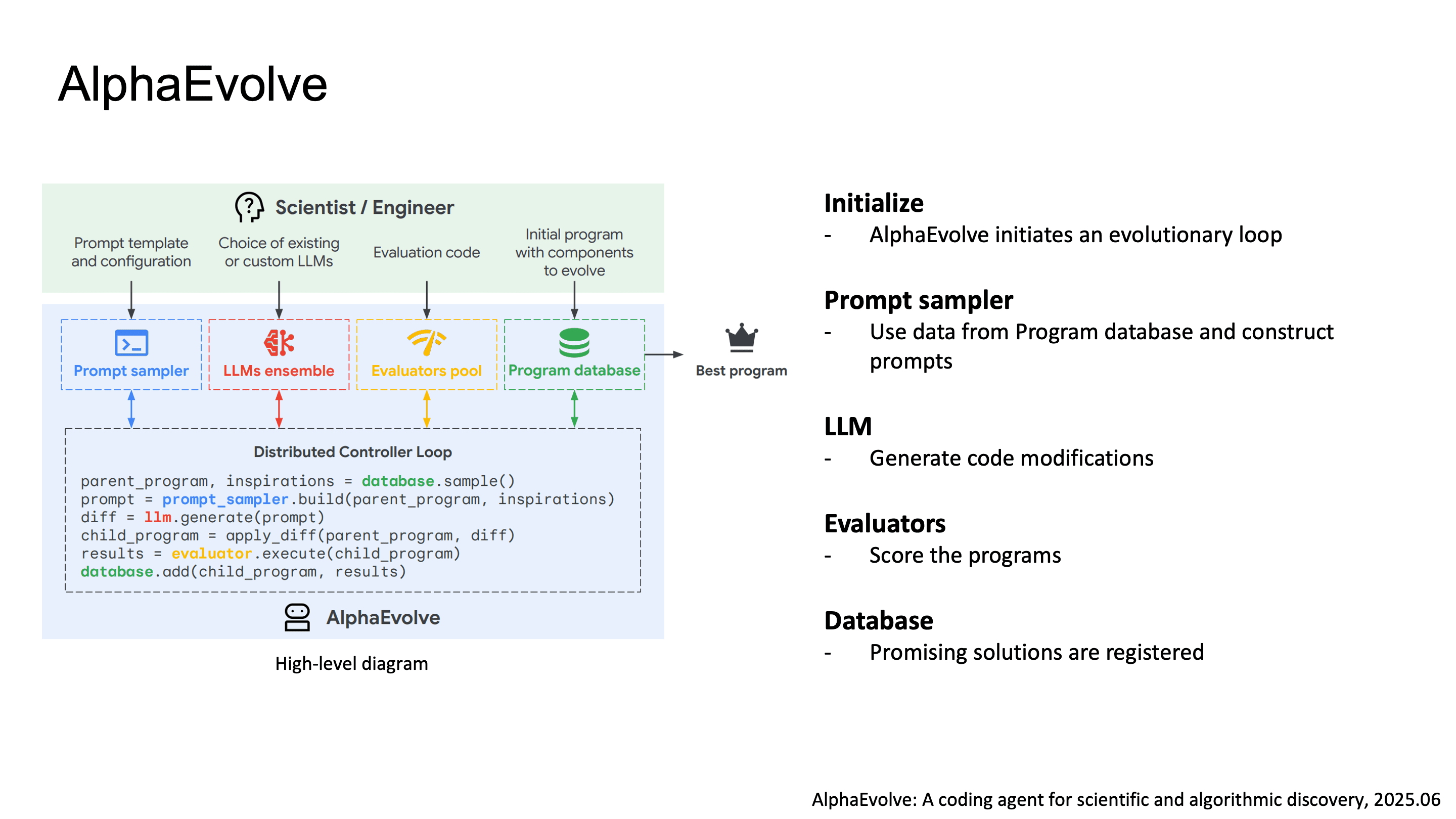
AlphaEvolve의 파이프라인을 보면:
Initialize: evolutionary loop 시작, initial program population 구성
Prompt Sampler: Program Database에서 parnt program을 선택하고, 이전 evaluation feedback과 함께 LLM prompt를 구성
LLM: code diff 형태로 mutation을 생성. full rewrite가 아니라 targeted modification
Evaluators: evaluation cascade(점진적으로 난이도가 올라가는 test suite로 early rejection하여 compute 절약)와 LLM-based qualitative feedback을 결합
Program Database: fitness-based selection으로 유망한 variant를 등록
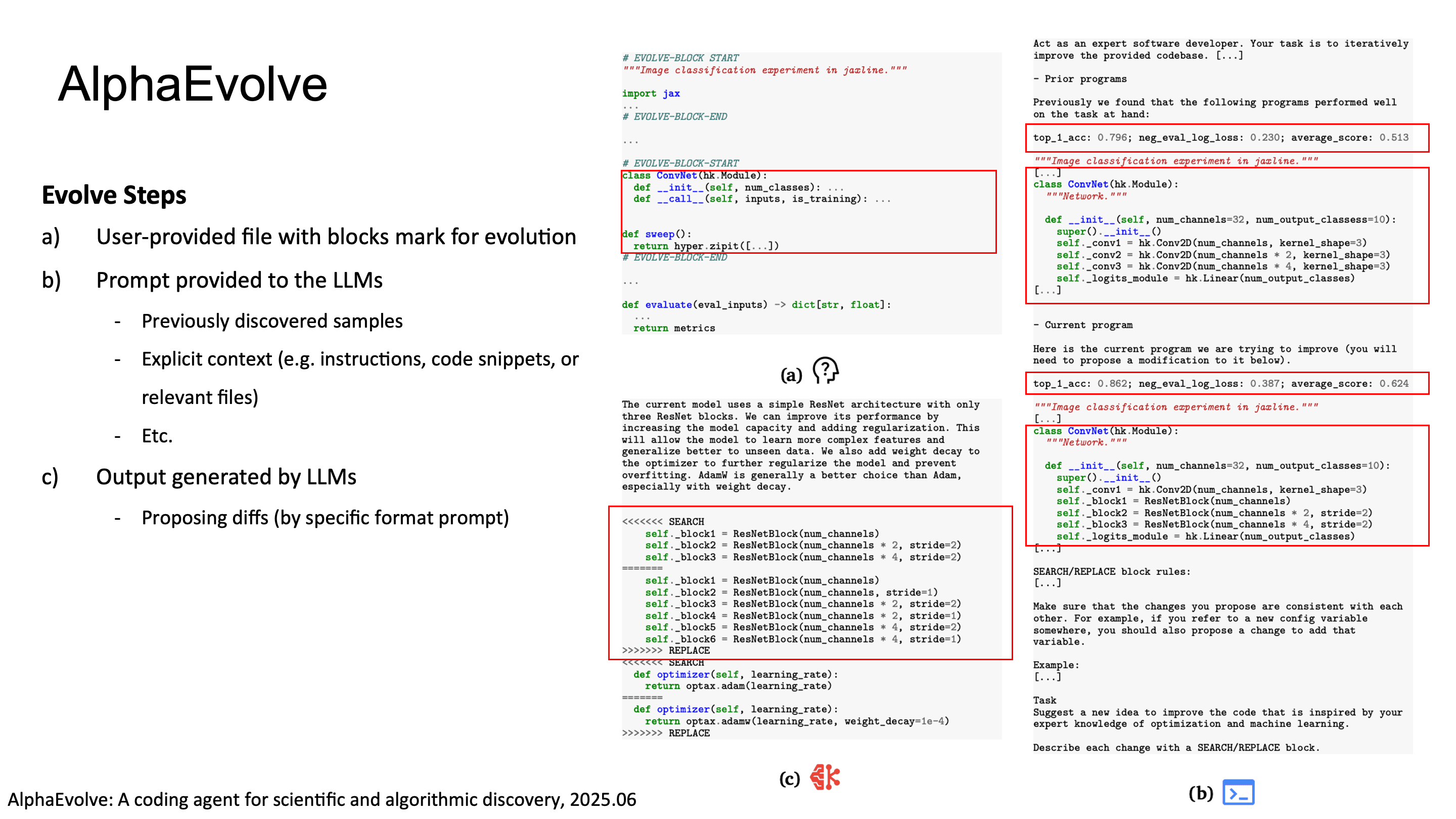
AlphaEvolve의 핵심적인 디자인은 3가지 입니다. 먼저, LLM이 whole program이 아닌 diff를 생성하므로 기존 코드의 structure를 보존하면서 targeted improvement가 가능합니다.
그리고 evaluation cascade로 compute budget을 효율적으로 쓸 수 있습니다. 마지막으로, program selection에 MAP-Elites algorithm을 사용해서 quality-diversity trade-off를 관리합니다. 단순히 best fitness만 쫓으면 premature convergence가 일어나는데, MAP-Elites는 behavioral feature space에서의 diversity를 유지하면서 exploitation도 할 수 있습니다.

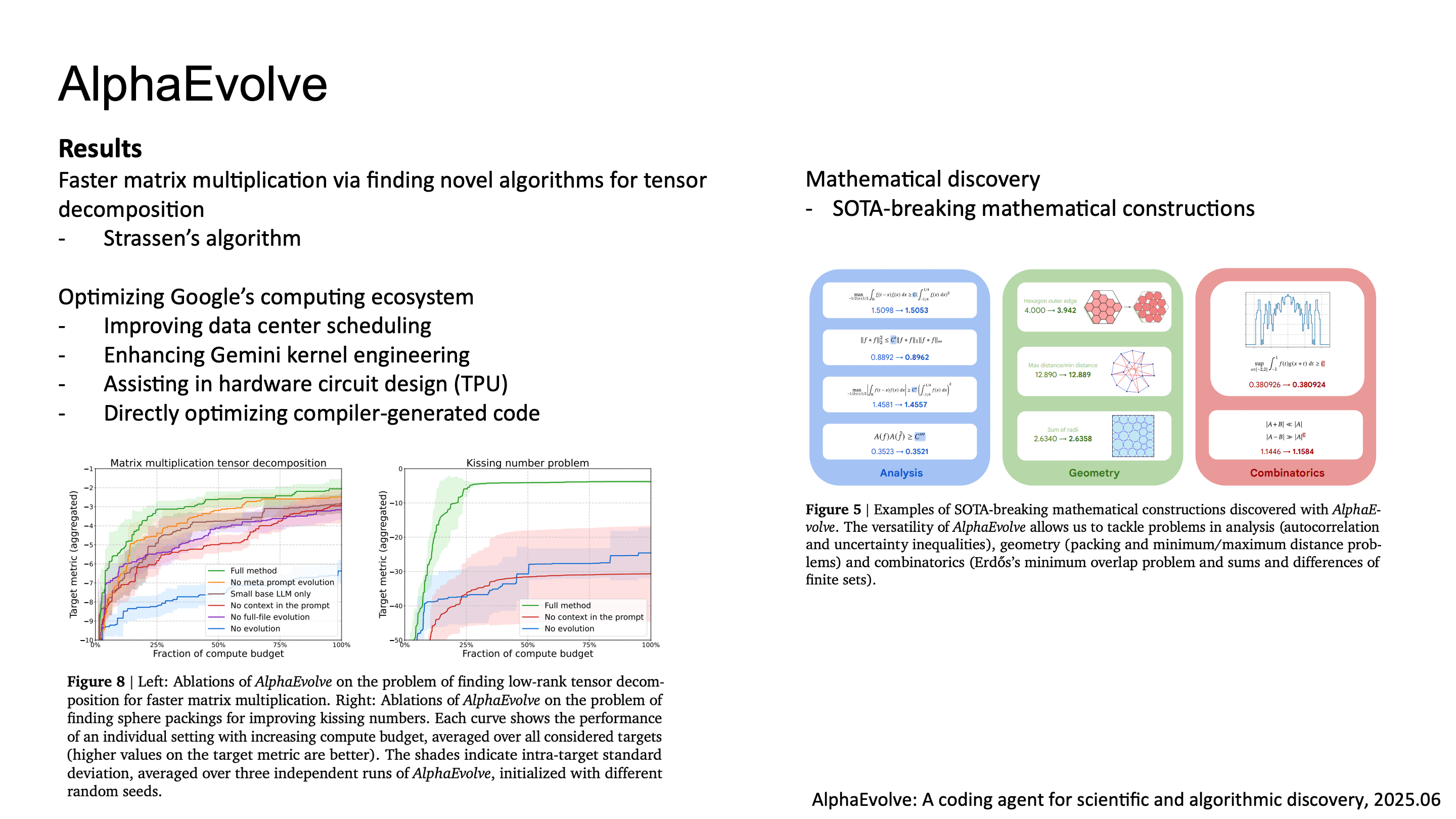
AlphaEvolve의 결과를 보면, 4x4 complex matrix multiplication을 위한 tensor decomposition에서 새로운 알고리즘을 발견했고, Google data center scheduling을 0.7% 최적화했으며, Gemini kernel engineering 개선, TPU circuit design에서의 Verilog 최적화, XLA compiler의 tile-size heuristic 개선했습니다.
마무리하며
지난 1년간의 흐름을 봤을 때 test-time scaling의 한계가 tool-augmented reasoning으로 이어지고, tool-use의 학습이 SFT에서 RL로 진화하며, single-tool에서 multi-tool로, single-agent에서 multi-agent orchestration으로 확장되었습니다.
Toolformer가 utility-aware self-supervised tool learning의 가능성을 보여줬고, ReTool과 Search-R1이 RL을 통한 strategic tool-use를 증명했으며, Deep Researcher와 AlphaEvolve가 이런 능력을 기반으로 human expert 수준의 complex task execution이 가능하다는 걸 보여줬습니다.
개인적으로 앞으로 유의깊게 볼 방향은 evaluation이라고 생각합니다. RL reward를 어떻게 잘 설계하냐에 따라서 모델의 성능이 바뀔 수 밖에 없고 점차 LLM이 복잡하고 오래 걸리는 작업을 하기 때문에 얼마나 이 task들을 잘 수행하냐가, 그리고 어떻게 평가하느냐가 중요한 문제가 될 것이라고 생각이 듭니다.
References
ReAct: Synergizing Reasoning And Acting in Language Models (ICLR 2023)
Toolformer: Language Models Can Teach Themselves to Use Tools (NeurIPS 2023)
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-World APIs (ICLR 2024)
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs (2025)
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning (2025)
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning (2025)
ARTIST: Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning (2025)
Tool-Star: Empowering LLM-Brained Multi-Tool Reasoner via Reinforcement Learning (2025)
MCP-RADAR: A Multi-Dimensional Benchmark for Evaluating Tool Use Capabilities in Large Language Models
Deep Researcher with Test-Time Diffusion (Google, 2025)
AlphaEvolve: A Coding Agent for Scientific and Algorithmic Discovery (Google DeepMind, 2025)
Anthropic: How We Built a Multi-Agent Research System
A Peek into Token Bias: Large Language Models Are Not Yet Genuine Reasoners (EMNLP 2024)
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling (2024)
A Survey of Context Engineering for Large Language Models (2025)